一种用于SLAM/SFM的深度学习特征点 SuperPoint
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
本文转自3D视觉工坊


Homographic Adaptation
)的策略以增强特征点的复检率以及跨域的实用性(这里跨域指的是synthetic-to-real的能力,网络模型在虚拟数据集上训练完成,同样也可以在真实场景下表现优异的能力)。
介绍
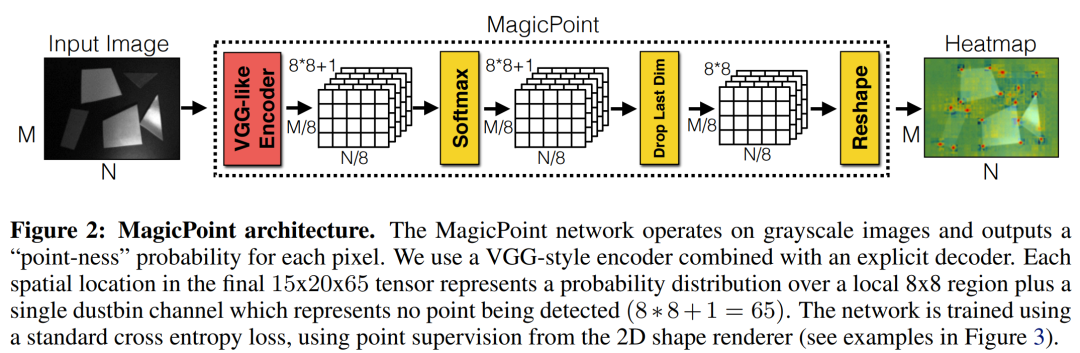
MagicPoint
,这个pre-trained的检测器就是
MagicPoint
检测器。这些
MagicPoint
在虚拟场景的中检测特征点的性能明显优于传统方式,但是在真实的复杂场景中表现不佳,此时作者提出了一种多尺度多变换的方法
Homographic Adaptation
。对于输入图像而言,
Homographic Adaptation
通过对图像进行多次不同的尺度/角度变换来帮助网络能够在不同视角不同尺度观测到特征点。综上:SuperPoint = MagicPoint+Homographic Adaptation
算法优劣对比
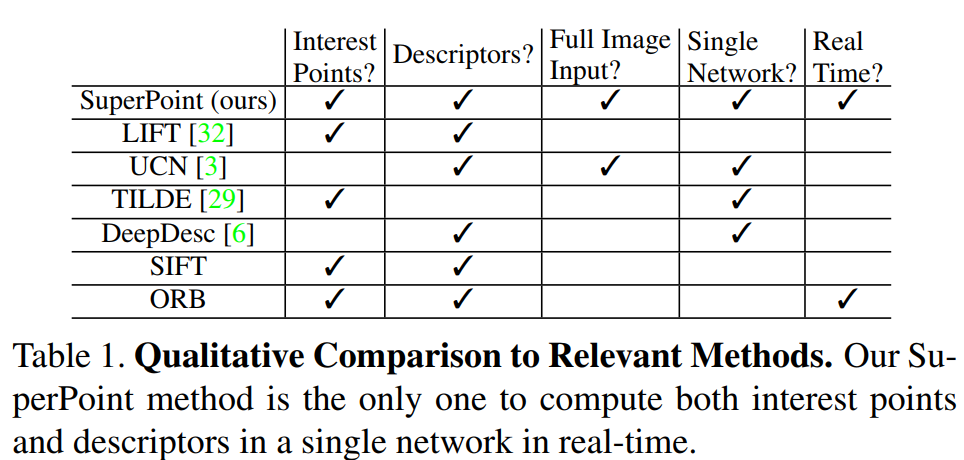
-
基于图像块的算法导致特征点位置精度不够准确; -
特征点与描述子分开进行训练导致运算资源的浪费,网络不够精简,实时性不足;或者仅仅训练特征点或者描述子的一种,不能用同一个网络进行联合训练;
网络结构
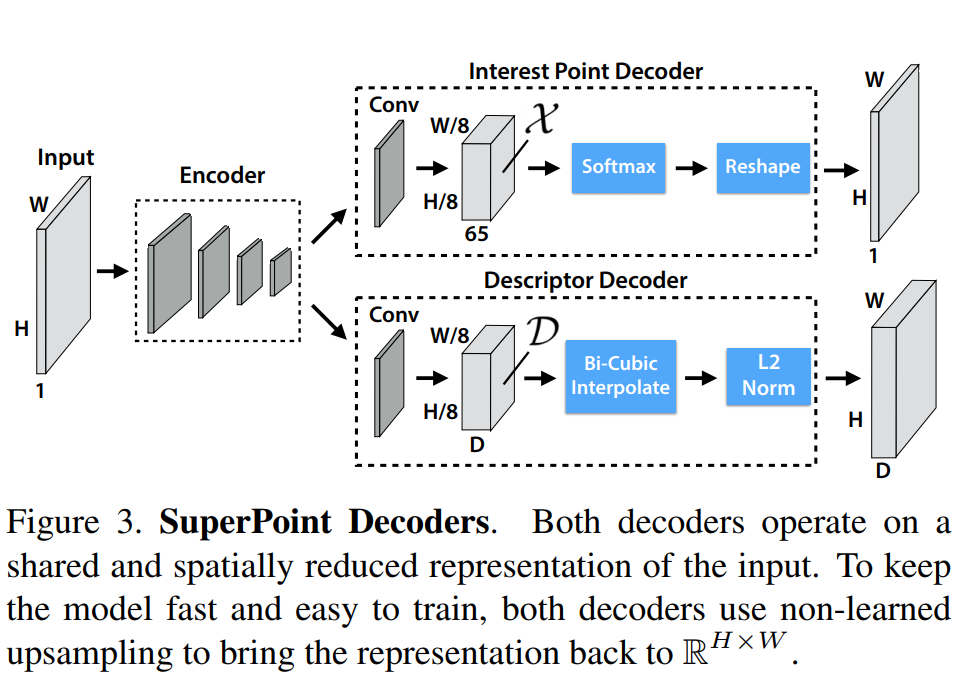
1. Shared Encoder 共享的编码网络
2. Interest Point Decoder
dustbin
。通过在channel维度上做softmax,非特征点dustbin会被删除,同时会做一步图像的
reshape
:
。(这就是子像素卷积[6]的意思,俗称像素洗牌)
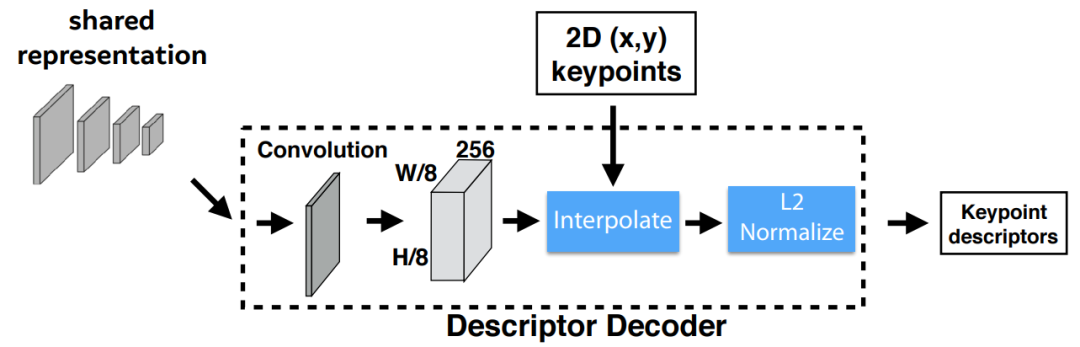
3. Descriptor Decoder
L2-normalizes
归一化描述子得到统一的长度描述。特征维度由
变为
。
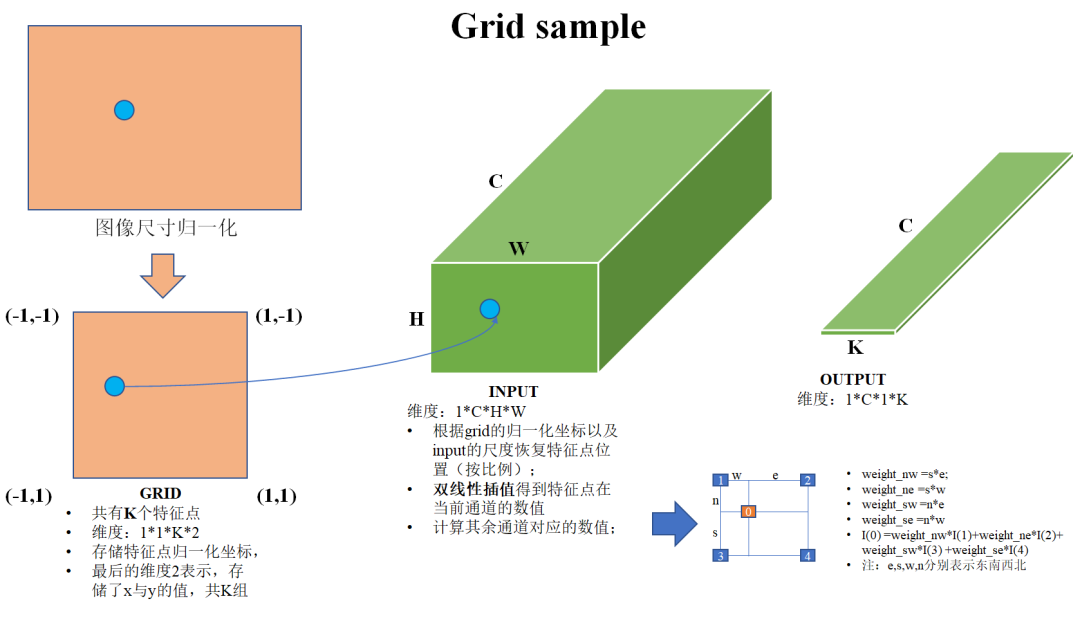
grid_sample
,画了一个草图作为解释。
-
图像尺寸归一化:首先对图像的尺寸进行归一化,(-1,-1)表示原来图像的(0,0)位置,(1,1)表示原来图像的(H-1,W-1)位置,这样一来,特征点的位置也被归一化到了相应的位置。 -
构建grid:将归一化后的特征点罗列起来,构成一个尺度为1*1*K*2的张量,其中K表示特征数量,2分别表示xy坐标。 -
特征点位置反归一化:根据输入张量的H与W对grid(1,1,0,:)(表示第一个特征点,其余特征点类似)进行反归一化,其实就是按照比例进行缩放+平移,得到反归一化特征点在张量某个slice(通道)上的位置;但是这个位置可能并非为整像素,此时要对其进行双线性插值补齐,然后其余slice按照同样的方式进行双线性插值。注:代码中实际的就是双线性插值,并非文中讲的双三次插值; -
输出维度:1*C*1*K。
4. 误差构建
Hinge-loss
(合页损失函数,用于SVM,如支持向量的软间隔,可以保证最后解的稀疏性);
网络训练
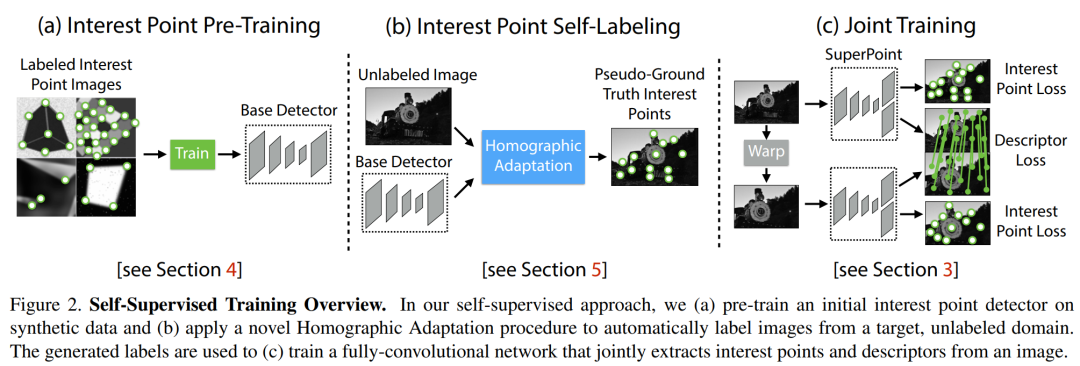
BaseDetector
,用于检测角点(注意,此处提取的并不是最终输出的特征点,可以理解为候选的特征点),另一个是
SuperPoint
网络,输出特征点和描述子。
-
第一步是采用虚拟的三维物体作为数据集,训练网络去提取角点,这里得到的是 BaseDetector即,MagicPoint; -
使用真实场景图片,用第一步训练出来的网络 MagicPoint+Homographic Adaptation提取角点,这一步称作兴趣点自标注(Interest Point Self-Labeling) -
对第二步使用的图片进行几何变换得到新的图片,这样就有了已知位姿关系的图片对,把这两张图片输入SuperPoint网络,提取特征点和描述子。
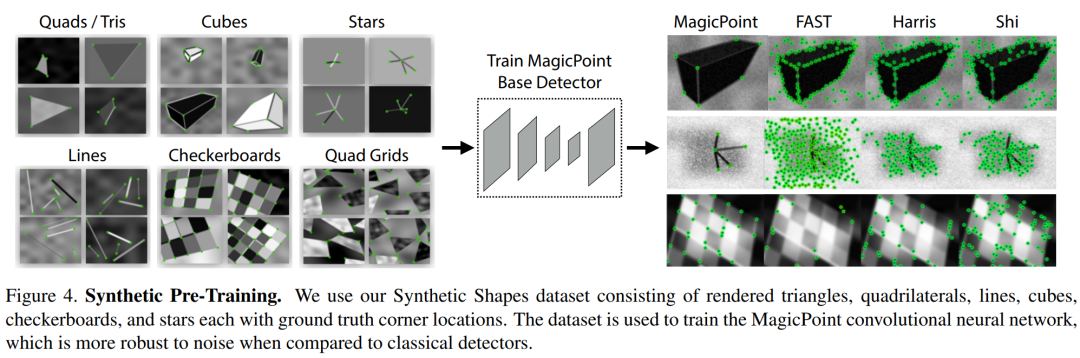
预训练Magic Point
MagicPoint
,在此不做展开介绍。
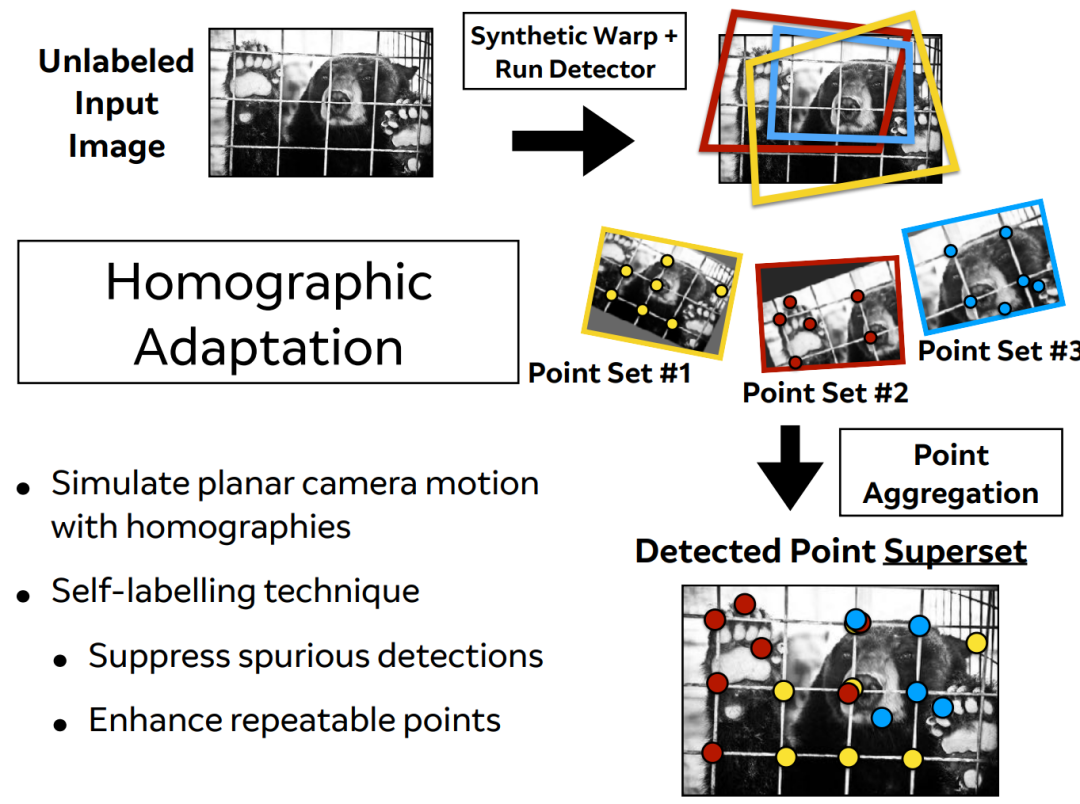
Homographic Adaptation
Homographic Adaptation
。 作者使用的数据集是
MS-COCO
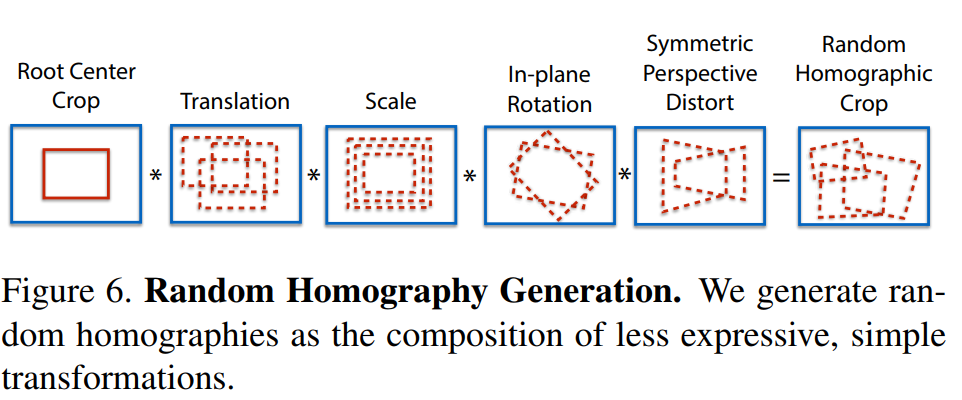
,为了使网络的泛化能力更强,本文不仅使用原始了原始图片,而且对每张图片进行随机的旋转和缩放形成新的图片,新的图片也被用来进行识别。这一步其实就类似于训练里常用的数据增强。经过一系列的单映变换之后特征点的复检率以及普适性得以增强。值得注意的是,在实际训练时,这里采用了迭代使用单映变换的方式,例如使用优化后的特征点检测器重新进行单映变换进行训练,然后又可以得到更新后的检测器,如此迭代优化,这就是所谓的self-supervisd。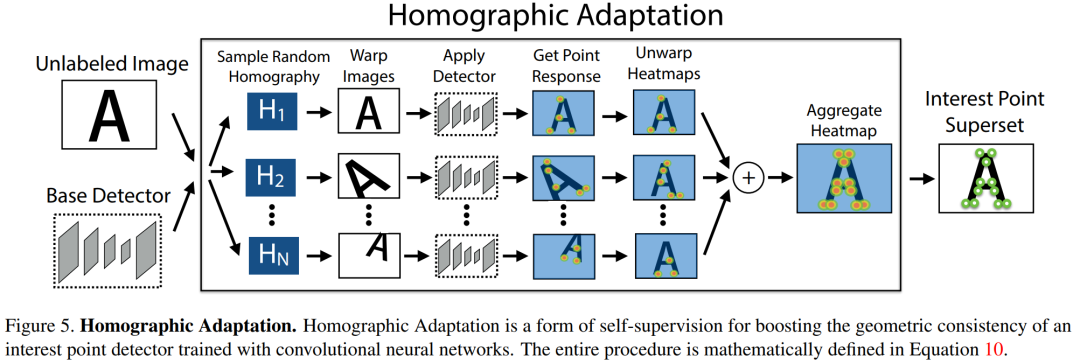
ADAM
进行优化。
实验结果
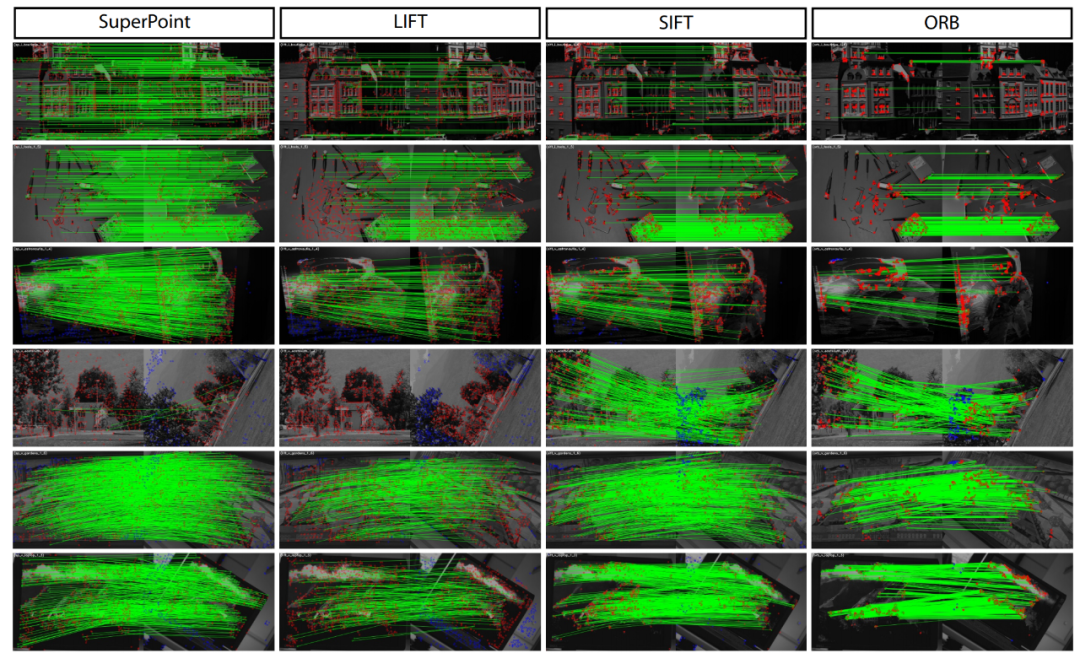

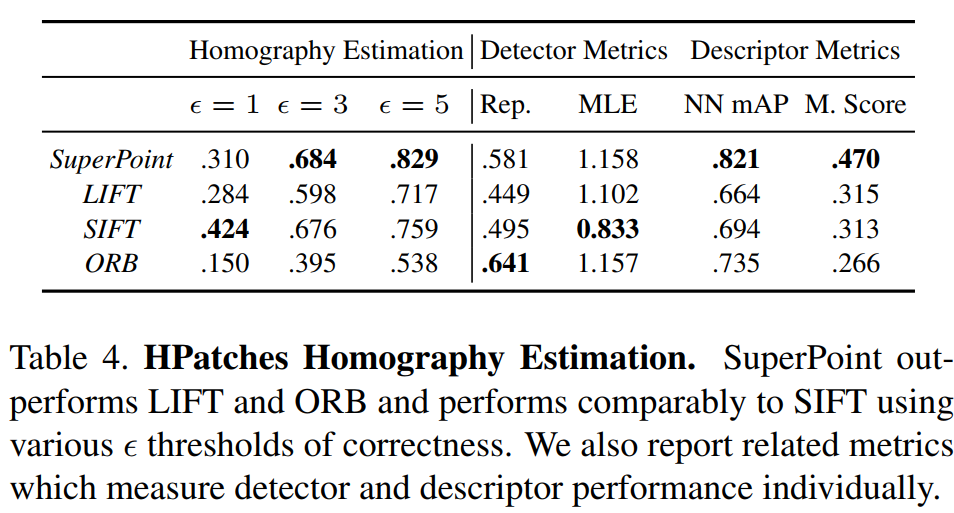


总结
-
it is possible to transfer knowledge from a synthetic dataset onto real-world images -
sparse interest point detection and description can be cast as a single, efficient convolutional neural network -
the resulting system works well for geometric computer vision matching tasks such as Homography Estimation -
研究Homographic Adaptation能否在语义分割任务或者目标检测任务中有提升作用 -
兴趣点提取以及描述这两个任务是如何影响彼此的
learning-based
前端可以使得诸如机器人或者AR等应用获得更加鲁棒。
参考资料
[1]MagicLeap: https://www.magicleap.com/
[2]Daniel DeTone: http://www.danieldetone.com/
[3]paper: https://arxiv.org/abs/1712.07629
[4]slides:https://github.com/MagicLeapResearch/SuperPointPretrainedNetwork/blob/master/assets/DL4VSLAM_talk.pdf
[5]code:https://github.com/MagicLeapResearch/SuperPointPretrainedNetwork
[6]子像素卷积: https://blog.csdn.net/leviopku/article/details/84975282
[7]UCN: https://arxiv.org/abs/1606.03558
[8]SpatialGridSamplerBilinear:https://github.com/pytorch/pytorch/blob/f064c5aa33483061a48994608d890b968ae53fb5/aten/src/THNN/generic/SpatialGridSamplerBilinear.c
[9]Toward Geometric Deep SLAM: https://arxiv.org/abs/1707.07410
编辑:计算机视觉SLAM
从0到1学习SLAM,戳↓

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
投稿、合作也欢迎联系:simiter@126.com

扫描关注视频号,看最新技术落地及开源方案视频秀 ↓