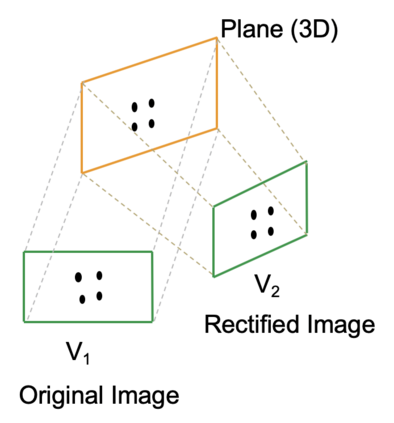
In this paper, we focus on the question: how might mobile robots take advantage of affordable RGB-D sensors for object detection? Although current CNN-based object detectors have achieved impressive results, there are three main drawbacks for practical usage on mobile robots: 1) It is hard and time-consuming to collect and annotate large-scale training sets. 2) It usually needs a long training time. 3) CNN-based object detection shows significant weakness in predicting location. We propose a novel approach for the detection of planar objects, which rectifies images with geometric information to compensate for the perspective distortion before feeding it to the CNN detector module, typically a CNN-based detector like YOLO or MASK RCNN. By dealing with the perspective distortion in advance, we eliminate the need for the CNN detector to learn that. Experiments show that this approach significantly boosts the detection performance. Besides, it effectively reduces the number of training images required. In addition to the novel detection framework proposed, we also release an RGB-D dataset for hazmat sign detection. To the best of our knowledge, this is the first public-available hazmat sign detection dataset with RGB-D sensors.
翻译:在本文中,我们侧重于一个问题:移动机器人如何利用负担得起的 RGB-D 传感器进行天体探测?虽然目前CNN 的物体探测器取得了令人印象深刻的成果,但移动机器人的实际使用有三大缺点:(1) 收集和说明大型训练成套材料十分困难和耗时。(2) 通常需要很长的培训时间。(3) CNN 的物体探测显示在预测位置方面存在着重大弱点。我们建议采用新颖的方法探测平板物体,用几何信息校正图像,以弥补观点扭曲,然后将其输入CNN 探测器模块,通常是YOLO 或MASK RCN。我们通过预先处理观点扭曲,消除了CNN探测器了解这一点的必要性。实验表明,这一方法极大地提高了探测性能。此外,它有效地减少了所需培训图像的数量。除了提出新的探测框架外,我们还发布了一套RGB-D 数据集,用于检测光子信号。我们最了解的是,这是第一个公共可获取的雷达探测器,用RGB 信号设置。