微信公众号文章质量评分算法详解
作为一个多年的微信公众号作者,了解微信公众号文章打分的机制是十分有必要的。微信在后台其实有一整套的打分机制,今天基于腾讯的这篇Paper《Cognitive Representation Learning of Self-Media Online Ariticle Quality》为大家介绍下文章质量打分背后的算法理论。
在这篇paper中其实重点分享了两个方面,一方面是文章质量分的深度学习模型设计方法,另一方面是训练数据的构造法。
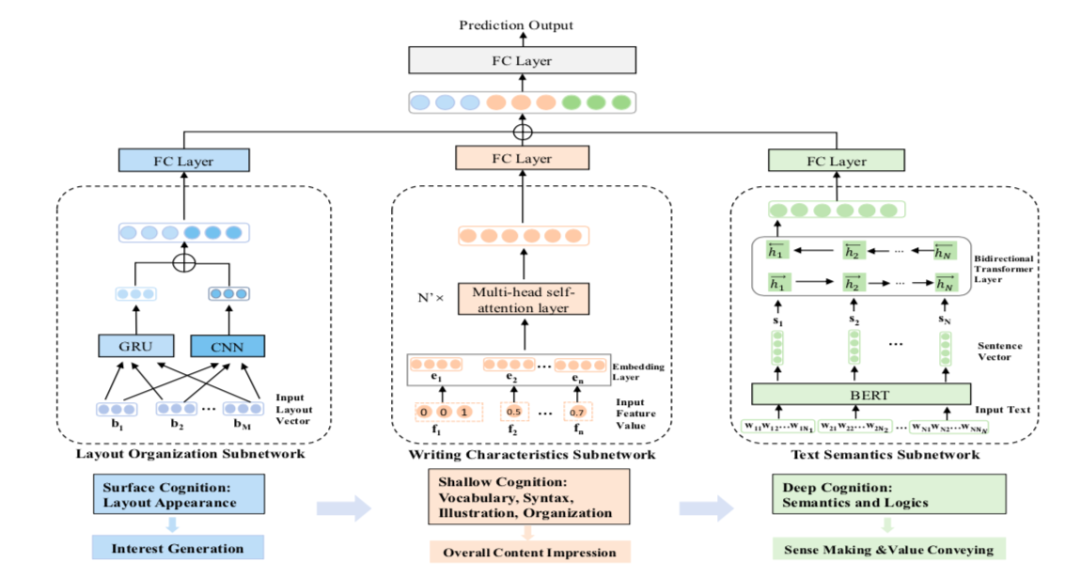
整个模型的设计分为两层,第一层是蓝、粉、绿这三个模块,作为基础的文章质量embedding生成层。第二层是最上方的FC Layer全连接层,这一层主要是做评分。
论文里把上面这个网络架构叫做CoQAN,文章质量分的训练模式被当成了二分类问题。
在模型设计上分为三个独立的模块(Subnetwork),分别是:
Layout Organization Subnetwork:布局结构判断网络,用来生成布局相关的评分
Writing Characteristics Subnetwork:写作风格判断网络,用来评估文章的写作风格
Text Semantics Subnetwork:语意深度判断网络,用来评估文章内容的质量
(1)Layout Organization Subnetwork
在布局评估网络中,主要通过循环网络算法GRU去判断图片、文本、视频的布局结构。
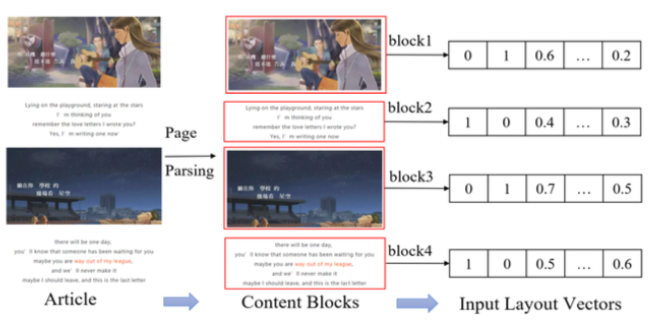
每段文章或者视频或者图片叫做一个block,GRU算法用来表述上下block结构pattern,用CNN表述block内部的布局。然后GRU和CNN综合起来
(2)Writing Characteristics Subnetwork
这个网络主要解决的是如何评估文章的协作风格,更多的是NLP方面的一些特征的挖掘,比如标题长度、核心词的个数、文章长度、n-gram、图片和文章的比例、图片数量、文章数量等。
然后利用one-hot编码就可以得到原始特征,然后还可以用一些特征交叉去生成一些交叉特征。
(3)Text Semantics Subnetwork
语意理解模型,通过优化bert模型形成hi-bert模型。hi-bert模型可以挖掘句子和词之间语意关系,找到主题和文章的语意深度。
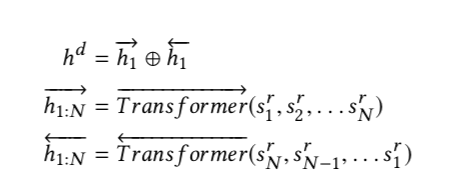
上文介绍了文章评分模型的结构,在Paper的结尾片段还介绍了训练数据的构建方式。文章质量分训练可以看作是一个二分类问题,所以需要选择正样本和负样本。
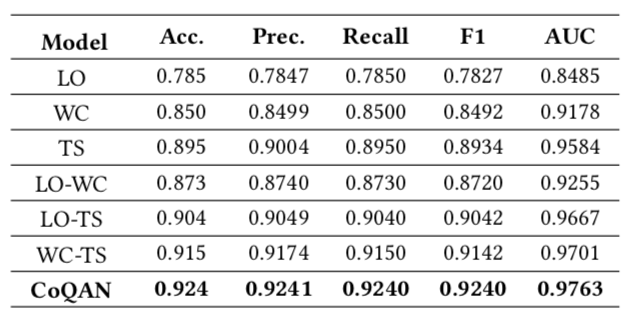
正样本的标准是高等级的账号发表,具备比较高的喜欢、分享次数,不符合标准的被作为负样本。最终Paper中的模型训练使用了22054篇文章作为正样本,16194篇文章作为负样本。
最终在与其它文章质量分模型的比较中,CoQAN取得了比较好的结果: