中科院团队推出开源神经形态芯片「文曲星」(附源代码)
机器之心专栏
来自中科院计算所、北京邮电大学、上海科技大学和中国科学院大学的六位同学和一位教师组成的研究团队在arXiv上提出了一种功耗极低的神经形态处理器「文曲星 22A」,结合了通用 CPU 和 SNN 计算的功能,并通过 RISC-V SNN 扩展指令集完成了高效计算。
几十年来,旨在模仿大脑行为的神经形态计算已得到广泛发展。人工神经网络(ANN)是人工智能(AI)中一个重要的概念,在识别和分类任务上取得了出色的性能。为了在硬件上更好地模拟大脑的行为,研究人员开发了一种既快速又节能的新方法——神经形态计算。
在神经形态计算中,脉冲神经网络(Spiking Neural Network,SNN) 是硬件实现的最佳选择。因此,近来一些研究把工作重点放在了加速 SNN 计算上。然而,大多数加速器解决方案都基于 CPU 加速器架构,这种结构因为复杂的控制流程而能源效率低下。
来自中科院计算所、北京邮电大学、上海科技大学和中国科学院大学的六位同学和一位教师组成的研究团队在arXiv上提出了一种功耗极低的神经形态处理器「文曲星 22A」,结合了通用 CPU 和 SNN 计算的功能,并通过 RISC-V SNN 扩展指令集完成了高效计算。文曲星 22A 通过自定义 RISC-V SNN 指令集 1.0(RV-SNN 1.0)将 SNN 计算单元集成到通用 CPU 的 pipeline 中,实现了低功耗计算。

论文链接:http://arxiv.org/abs/2210.00562
GitHub: https://github.com/openmantianxing/Wenquxing22A
Gitee: https://gitee.com/openmantianxing/wenquxing22a
研究者使用中国科学院大学 OSCPU 团队设计的 9 级顺序 RISC-V 处理器 Nutshell 作为基准,并将其执行单元扩展为该研究自行设计的 RISC-V SNN 扩展指令集。NutShell 本身具有 RV64IMACSU 指令集,可以运行 Linux 等现代操作系统,也是一种高性能的 RISC-V 开源处理器。
研究团队基于 RISC-V 自定义的 SNN 指令集具有高计算粒度,可防止 pipeline 因执行一条指令而长时间停滞。该研究利用带泄漏整合发放模型(LIF)和基于顺序的二进制随机 STDP 来执行基于事件的 SNN 计算。神经元和突触模型均对硬件友好且节能。
总的来说,该研究对实现低功耗 SNN 计算的贡献包括:
基于 RISC-V ISA 设计了高计算粒度的自定义 SNN 扩展指令集 RV-SNN 1.0;
精简了标准 LIF 模型,以降低在处理器中计算和集成神经元模型的难度;
修改了二进制随机 STDP,以适应突触权重的单周期更新;
研究团队开源了文曲星 22A 的源代码,以助力未来的芯片研究。
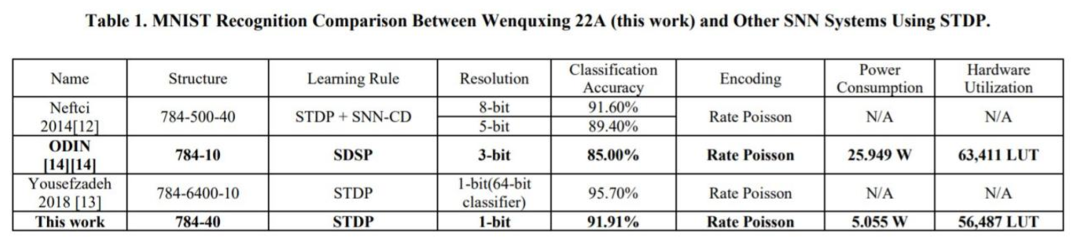
为了评估文曲星 22A 的性能,该研究将其用于 MNIST 数据集的识别任务,并和其他 SNN 系统进行了比较。实验结果表明,与加速器解决方案 ODIN 相比,在分类准确率相当的情况下,文曲星 22A 的功耗仅为 ODIN 的 1/5。
源代码描述
文曲星 22A 相关文件如下图所示:

SNN 单元
文曲星 22A 改编自 Nutshell(果壳)处理器,但是两者的不同点在于文曲星 22A 有一个 SNN 单元,可用于脉冲(spike)处理、神经更新和突触(synaptic)计算。而这些不同点又是文曲星 22A 的核心代码部分,存在于函数单元的 (fu) 目录下。
SNN 单元包含 4 个部分,分别是脉冲处理单元、LTD(Long-Term Depression )单元、神经元单元和 STDP( Long-Term Potential)单元。
脉冲处理单元:这个单元控制执行着输入脉冲和突触之间的 AND 操作,有效脉冲的数量被计算出来,并将其提交给下一个组件;
神经元单元:神经元单元根据来自脉冲处理单元的有效脉冲数量、先前状态和神经元的 leakage 电压来更新神经元的当前状态;
LTP 和 LTD 单元:神经元更新后,来自神经元的脉冲信号将被发送到 LTP 单元。该信号决定突触权重是否为 1(on)。之后 LTD 单元开始根据 LTD 概率降低突触权重。一个 16 位的 LFSR 将生成一个随机的 10 位数字 x,以与 LTD 概率进行比较。如果 x ≤ LTD 概率,则突触权重将设置为 0。
文曲星 22A 整体架构
该研究采用基准 NutShell 处理器来支持 SNN 的计算。下图 2 显示了文曲星 22A 的微架构。SNN 单元(显示为 SNNU)被添加到 pipeline 中,为执行阶段。SNN 工作流程中的三个阶段由 SPU(Spiking Process Unit)、NU(Neuron Unit)和 SU(Synapse Unit)处理组成。所有这些组件都集成到 SNNU 中。SNN 特殊寄存器堆与通用寄存器堆一起被定义,ISU(Issue Unit)控制指令发布,避免数据冒险。
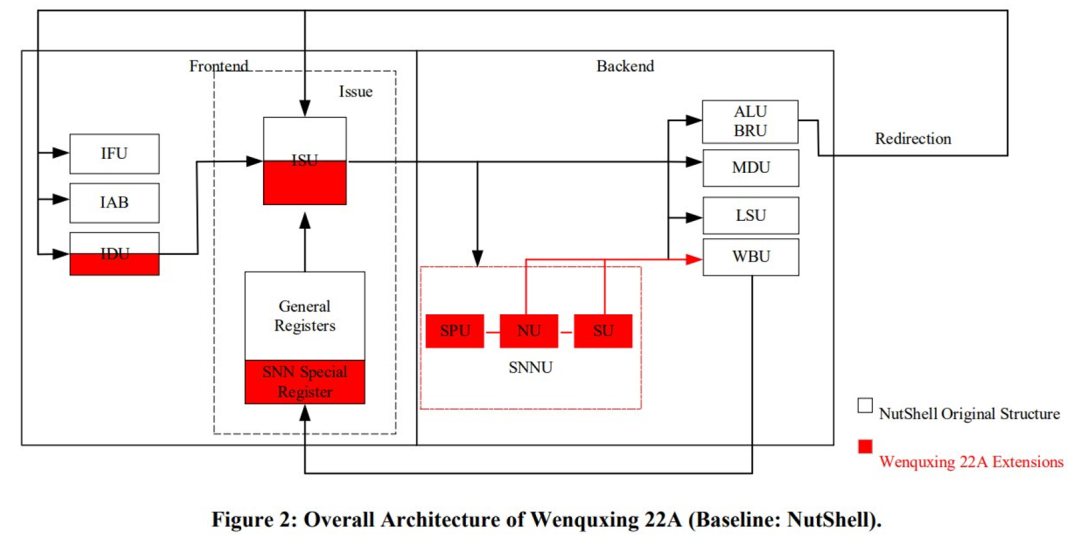
实验结果
MNIST 数据集有 70000 个从 0 到 9 的手写数字样本,其中 60000 个用于训练,10000 个用于测试。每个数字样本是一个 28×28 灰度图像,最大值为 255。该研究使用文曲星 22A,并利用二元随机 STDP 学习规则对该数据集进行分类。
网络架构
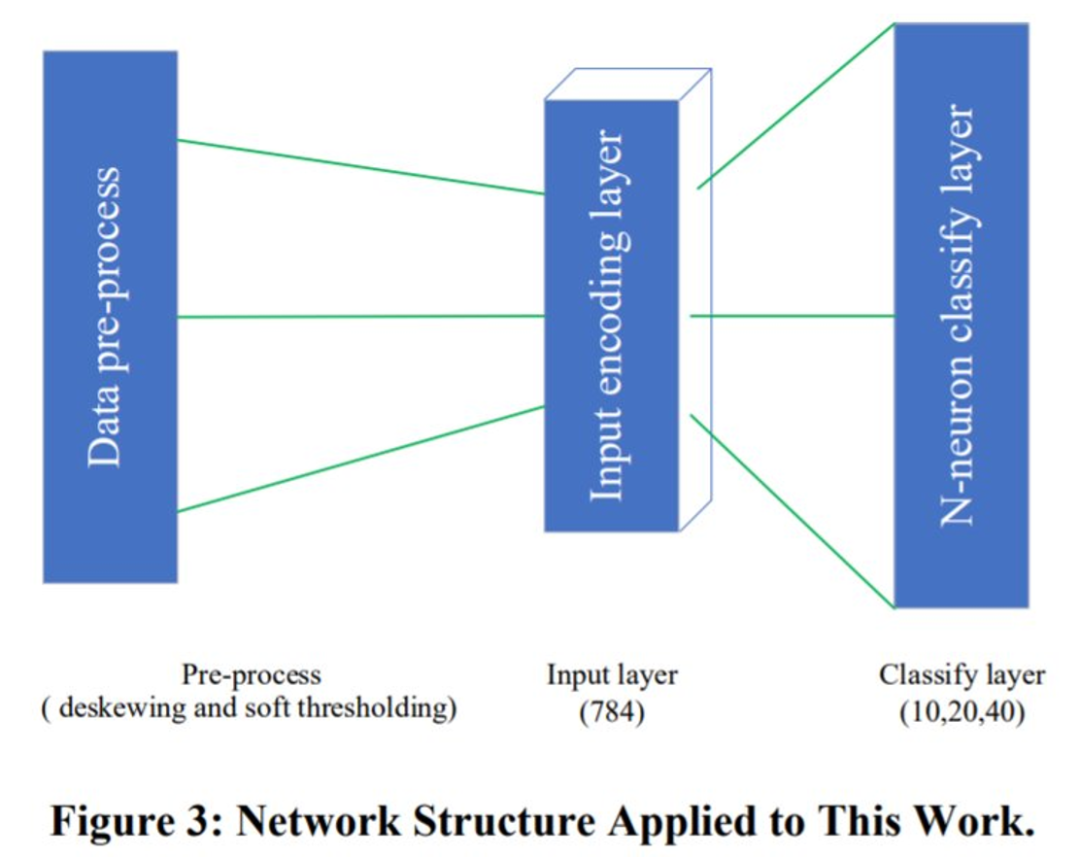
该研究将每个神经元的突触数设置为 28×28,以匹配图像格式。为了将这些样本提供给文曲星 22A 的 SNN,该研究使用泊松编码器(Poisson encoder)生成基于速率的泊松分布脉冲来激发输入层。该编码器将输入数据转换为具有相同形状的脉冲数据。为了生成脉冲,该研究设置了一个时间周期发射概率:p=x,其中 x 需要归一化到[0,1]。所有这些预处理步骤都在文曲星 22A 中执行。
比较结果
表 1 为文曲星 22A 与其他基于 STDP 的 SNN 系统的 MNIST 识别比较结果。由实验结果可得,在使用的低于 8 位 STDP 的系统中,文曲星 22A 与其他分类准确率相差不大,甚至更好。
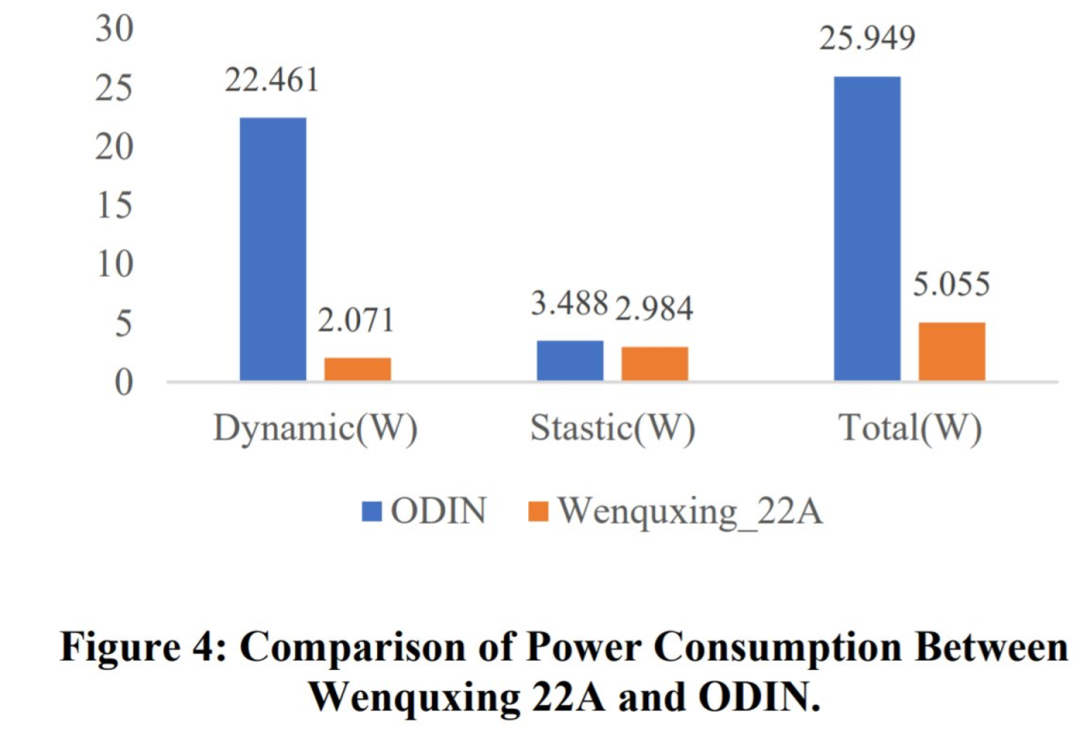
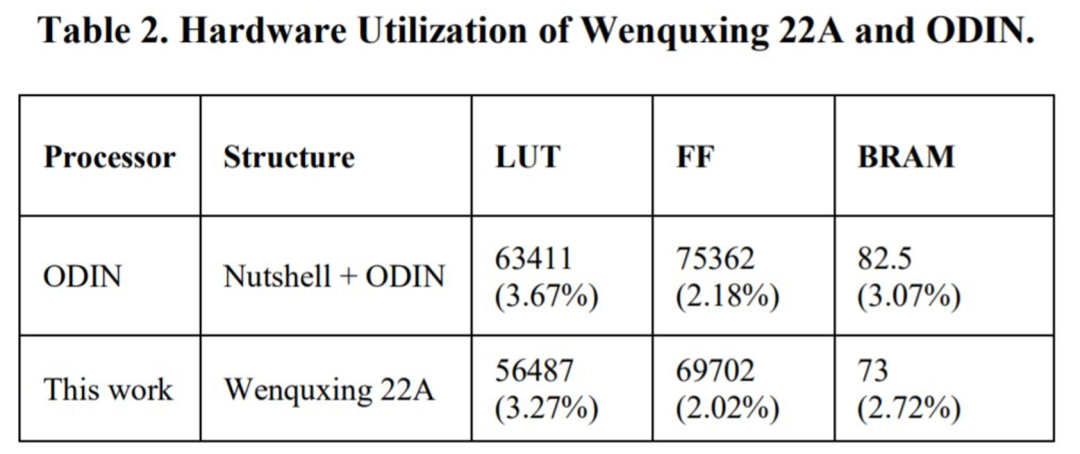
为了比较功耗,该研究将文曲星 22A 和 ODIN 都综合到同一个 FPGA 平台上,以对比这两款芯片的功耗。结果如图 4 所示。从图 4 可以看出,总功耗从 25.949 W(ODIN)降低到 5.055 W(文曲星 22A),具体硬件资源利用率如表 2 所示,比 ODIN 处理器低约 5 倍。
下表 2 为文曲星 22A 与 ODIN 的硬件利用比较:结果表明,文曲星 22A 消耗的硬件资源更少。
文曲星 22A 性能
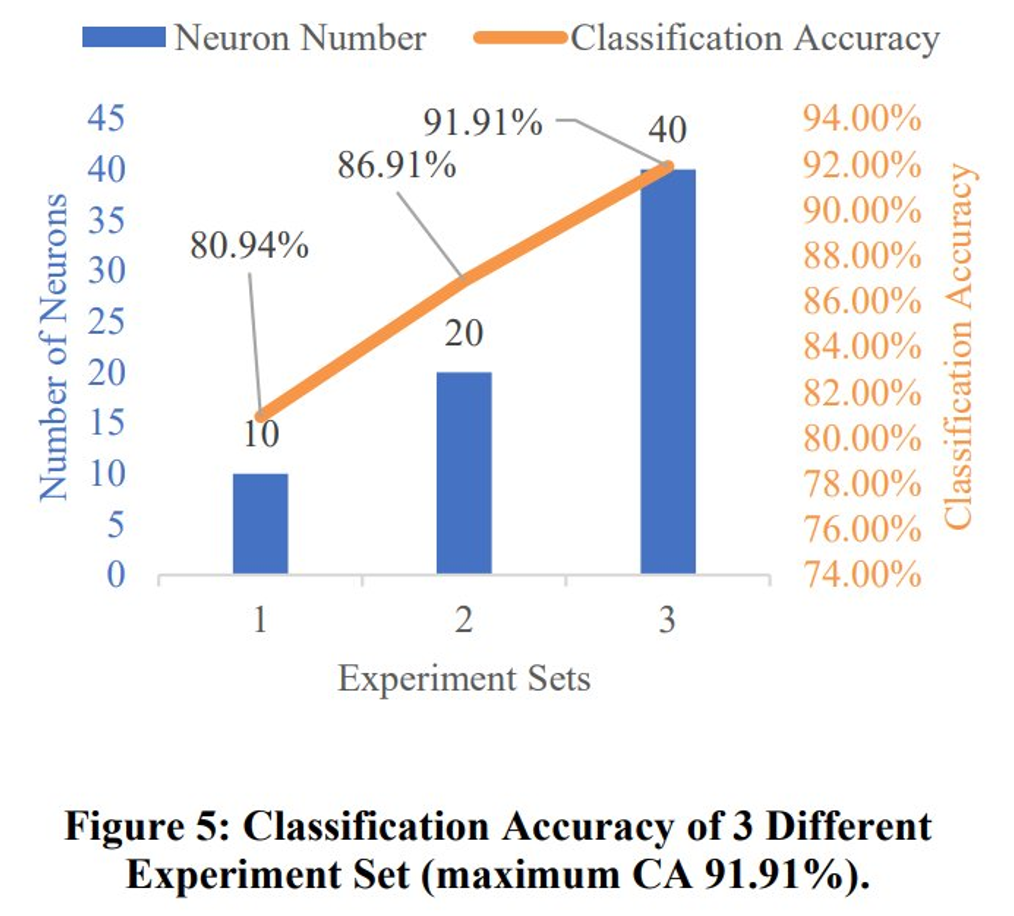
该研究用不同数量的神经元训练 SNN,在二进制随机 STDP 中为 (10,20,40) 个神经元。图 5 展示了在 10000 个 MNIST 测试样本的分类准确率 (CA),结果显示在文曲星 22A 上 10、20 和 40 个神经元的二进制权重 SNN 的最大准确率分别为 80.94%、86.91% 和 91.91%。CA 的增加表明难以用少量的神经元对一些相似度高的数字进行分类。虽然输出层中的神经元数量随着 w_exp 的增加而增加,但配置更多的神经元可以产生更高的识别准确率。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com


