加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
就在明天,极市直播第64期:非受控环境下的表情识别。来自中国科学院深圳先进技术研究院的彭小江副研究员和王锴将为我们介绍分享自注意力策略在这些问题上的两个探索工作,详情点这里。在极市平台后台回复“64”,即可获取直播链接。
来源|kid丶@知乎,https://zhuanlan.zhihu.com/p/163676138
这篇文章发自2020年的ICML,脑洞很大,居然只有一行代码?
论文链接
:
https://arxiv.org/pdf/2002.08709.pdf
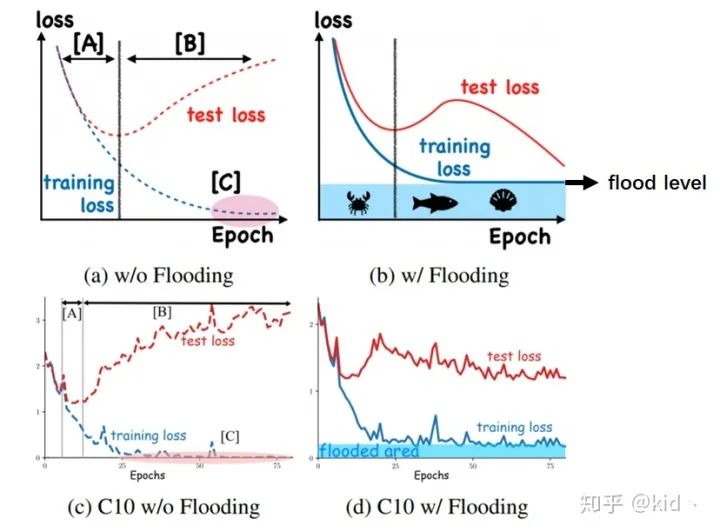
上图可以大致描述整篇文章干了一件啥事。
先看
左边一列,是一个正常的训练过程,对于阶段A,随着training loss的降低,test loss也会跟着降低;但是到阶段B后,我们继续在训练集上训练,会让test loss上升。
右边一列是本文提出的 flooding方法,当training loss大于一个阈值(flood level)时,进行正常的梯度下降;当training loss低于阈值时,会反过来进行梯度上升,让training loss保持在一个阈值附近,让模型持续进行“random walk”,并期望模型能被优化到一个平坦的损失区域,这样发现test loss进行了double decent!一个简单的理解是,这和early stop类的方法类似,防止参数被优化到一个不好的极小值出不来。
本文也是十分的“嚣张”,
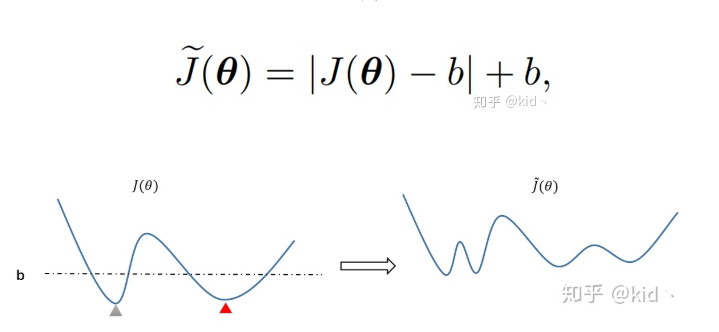
直接在文章introduction部分贴出了pytorch代码,仅仅增加了一行代码,真是好气!整个的损失从
被改成了
。
接下来是自己的一些思考,假设我们的损失
一开始如由左图所示,横坐标是参数
,纵坐标是损失
,此时有两个极小值点(灰色三角形和红色三角形),首先试问哪一个极小值要好一些(这个后面再做分析)。另外,假设虚线代表
,那么使用 flooding 方法相当于把低于阈值部分翻上来,二维的情况也类似。可以发现,整个目标多了很多极小值,二维平面的情况则是多了一圈极小值,是否可以说右边的损失要比左边的损失更加“平坦”,然后泛化能力会越好。
接下来是我的一些分析,首先是前面提到的灰色三角形和红色三角形两个极小值点,分别由上述两个损失代替,右边的损失比左边的损失看起来更“平坦”。我们从对抗样本的角度来理解,蓝色的笑脸代表正常被分对的样本,对抗样本是通过优化样本使得损失变大,从而让模型对该样本分错(黄色的难过脸)。直观来看,越平坦的损失会让对抗样本的生成越困难(
越大),因此越平坦的损失会让模型对对抗扰动越鲁棒。
其实,一般的鲁棒性和泛化性也如此,一般的鲁棒性是指模型对样本进行一些诸如高斯模糊、椒盐噪声等等鲁棒。换句话说,对样本进行一定的扰动(
),模型对扰动后样本的损失不要太大才行,越平坦的损失,一般鲁棒性也会越好。另一方面,泛化性也是一样,模型的预测一般满足相似的输入有相似的输出(假设损失对
光滑),也就是说,模型对样本学到的模式是某种特征左右的样本应该属于为某一类。换句话说,对于一个未见过的样本
(黄色难过脸)和样本
(蓝色笑脸)属于相同类,模型能将其分对的必要条件是损失不要过大,则此时“平坦”的损失能够满足这一条件,且泛化性会越好。
最后我们再来从svm的角度来思考这个问题。对于一个线性可分的二分类问题,有无数条分类面能将其分开,而svm是去挑选能满足“最大间隔”的分类器。从另一个角度来理解是,越平坦的损失,是不是能越尽可能地将不同类给分开,因为样本进行些许扰动,损失的变化不会太大,相当于进行细微扰动后的样本不会跑到分类面的另一边去!
上述的分析存在着一个问题是,横坐标应该是参数
,而我却一直把横坐标当作
,但其实认真想想,换成
也好像成立。因为神经网络参数
和
是乘积的形式,对参数
的细微变化能否等价于对样本
的细微变化!
![]()
添加极市小助手微信
(ID : cv-mart)
,备注:
研究方向-姓名-学校/公司-城市
(如:目标检测-小极-北大-深圳),即可申请加入
极市技术交流群
,更有
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、
干货资讯汇总、行业技术交流
,
一起来让思想之光照的更远吧~
觉得有用麻烦给个在看啦~
![]()