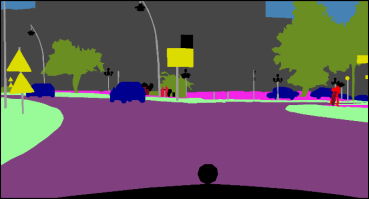
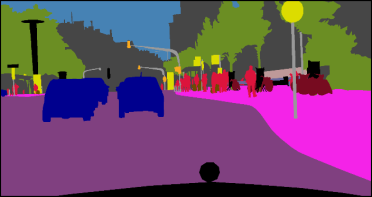
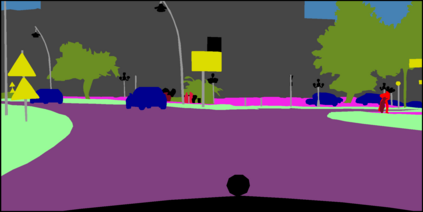
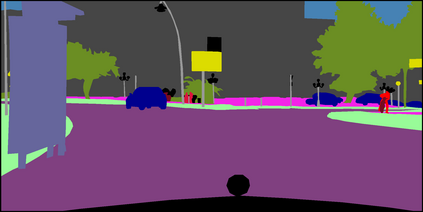
Semantic segmentation is one of the basic topics in computer vision, it aims to assign semantic labels to every pixel of an image. Unbalanced semantic label distribution could have a negative influence on segmentation accuracy. In this paper, we investigate using data augmentation approach to balance the semantic label distribution in order to improve segmentation performance. We propose using generative adversarial networks (GANs) to generate realistic images for improving the performance of semantic segmentation networks. Experimental results show that the proposed method can not only improve segmentation performance on those classes with low accuracy, but also obtain 1.3% to 2.1% increase in average segmentation accuracy. It shows that this augmentation method can boost accuracy and be easily applicable to any other segmentation models.
翻译:语义分解是计算机视觉的一个基本主题之一, 它旨在为图像的每个像素指定语义标签。 不平衡语义标签分布可能对分解准确性产生消极影响。 在本文中, 我们调查使用数据增强法平衡语义标签分布, 以提高分解性能。 我们提议使用基因对抗网络( GANs) 生成现实图像, 以改善语义分解网络的性能。 实验结果显示, 拟议的方法不仅可以提高这些类的分解性能, 还可以提高平均分解准确性1. 3%到 2.1%。 它表明, 这种增强法可以提高精度, 并很容易适用于任何其他分解模式 。