这款基于单目视觉的测量算法,看了照片就知道你多高?


基于单目视觉的度量方法,主要依赖于数据驱动的深度学习网络。通过充分利用车辆、行人等常见目标的尺度作为先验信息作为参考,单目视觉度量方法构建了一套基于重投影的优化模型,实现了精确的目标高度、相机高度、朝向和焦距的估计。
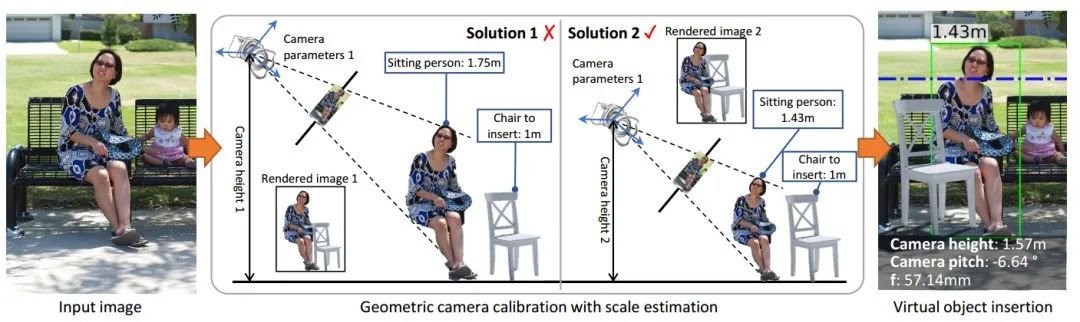
上图显示了尺度估计的处理流程,在图像输入后,单目视觉度量方法可以重建场景和相机参数 (这些参数与全局尺度相关),随后通过精确估计3D相机参数和目标高度的绝对尺度来实现对真实场景的精确测量。
三维尺度重建
图像中的尺度测量问题,主要研究了在非受限条件下如何利用图像计算出物体的尺寸,通过估计绝对尺寸来实现几何标定,包括恢复相机的朝向 (图像中的水平面)、视场、相机与地面的绝对高度。有了这些信息,就能将图像中的二维测量转换为真实空间中的三维测量了。
这一工作的目标主要在于,利用深度学习网络建立起稳定、鲁棒、自动化的单目视觉度量方法,可以广泛应用到多种场景的图像测量中去。 实现这一目标最直接的方法就是,通过监督学习的方法,利用已知相机参数的大规模数据集直接从图像中估计出场景的尺度。
但目前还缺乏如此大规模的包含相机参数标注的数据集,只能通过间接利用2D标注数据来实现,并创造性地选择了最普遍的人体和汽车来作为参考物体实现3D尺度推理。
在前人的基础上,研究人员拓展了模型的假设、基于弱监督的方式充分利用2D标注数据,利用端到端的方式完成了对于所有相机参数的估计,并在多个数据集上取得了非常好的效果。
基于2D标注的3D参数估计
这整套方法首先从建立完整有效的几何约束开始,基于成像过程建立了目标的高度、2D bbox尺度、相机的参数朝向和距地面的高度等变量间的约束关系。下图显示了研究中提出的成像过程。
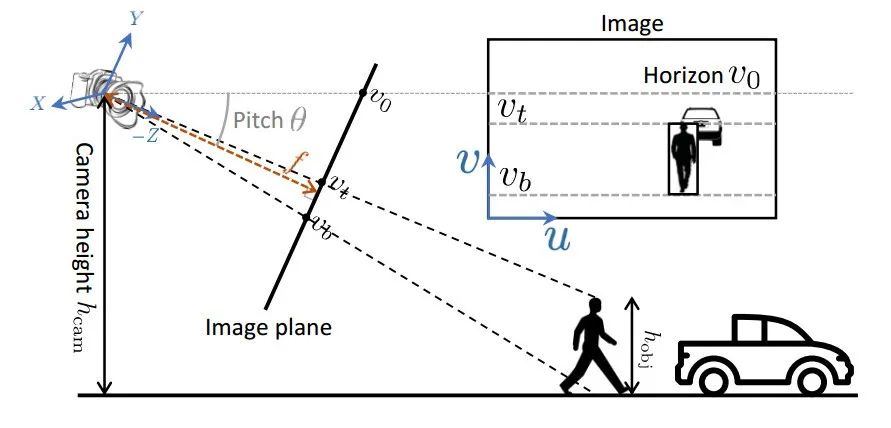
图中显示了相机对场景的成像过程和在图像上的2D测量结果。其中pitch是相机朝向与水平面的夹角 (yaw和roll假设为0) ;v0是相机所在高度水平面在图像中的位置,vc是相机光心在图像上位置,vt和vb是目标在图像中的顶部和底部。黑色为像平面,相机焦距为f (红色) ,高度为hcam,图中目标人的高度为hobj。
根据三角形的关系,可以利用焦距、图像中心vc水平位置v0表示出pitch角度:
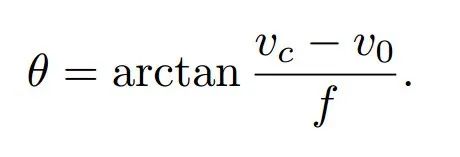
假设目标人站在地面上其脚部坐标为 [x,0,z]’ ,顶部坐标为 [x,hobj,z]’ ,那么将三维点投影到uv平面上就能得到下面的表达:
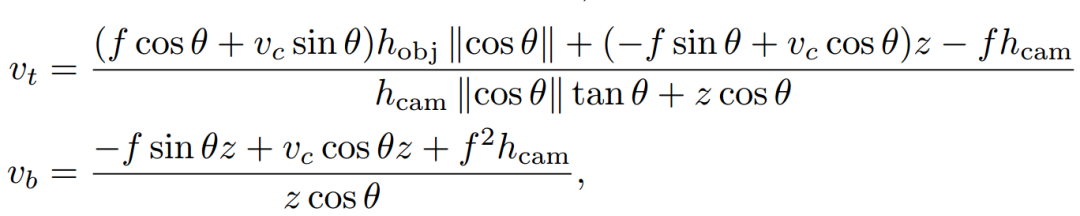
其中 [uc,vc] 是相机的光心坐标假设已知。从上面的公式中可以利用焦距f、pitch角、相机高度和目标高度等计算出出vt。再假设pitch角度很小,那么上面的式子可以简化为:、
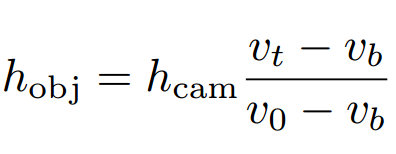
基于这一公式,只要得到相机参数就可以利用图像平面上的2D bbox来辅助计算目标的真实尺度了。在这一约束的基础上,下面将要建立ScaleNet用于从图像中预测相机的三维参数。下图显示了基于参数估计和重投影误差优化的整体网络结构:
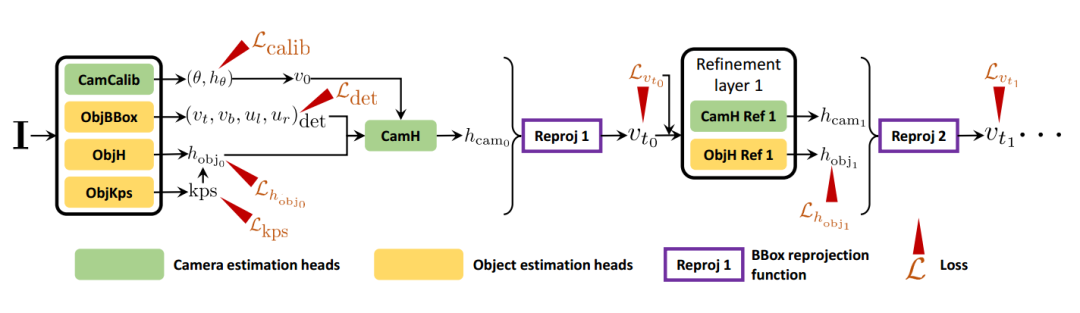
网络主要分为参数估计和重投影优化两个部分。第一部分的相机标定模块可以预测相机的视野和朝向pitch,目标估计模块可以得到目标的关键点、高度和检测bbox。得到的参数按照图中的组合再进一步放入相机高度估计模块进行处理,随后基于相机高度计算重投影误差来不断优化相机高度和目标高度的计算结果。
首先通过几何相机标定网络将同时估计出目标bbox和除相机高度外的所有相机参数,这些参数可以通过现有的数据集进行直接的监督训练。随后级联的网络用于优化相机高度,这一部分通过bbox的重投影误差进行弱监督训练。
实验中发现,预测相机的视场比直接预测焦距要容易,视场hθ可以通过下面的公式转化为焦距和中心坐标,其中him是图像的像素高度。
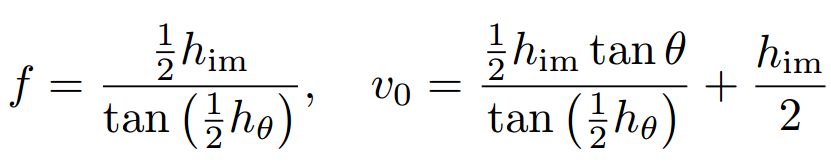
在这一工作中使用了Mask-RCNN的主干网络,除了前面估计相机参数外,还增加了bbox和人体关键点估计的分支 (高度与位姿紧密相关) 从ROI特征中进行预测,所以这一部分将会同时构成相机标定损失、目标检测损失和关键点估计损失。
但这些预测的结果还不足以获得绝对的尺度,场景尺度依旧无法确定。为此,研究人员利用了数据集中的先验信息来为目标建立监督。具体来讲,通过数据集中的统计信息来拟合高斯先验 (人体高度1.70±0.09m,车辆1.59±0.21m) 。针对高度为hobj的目标和先验高斯分布P,可以将损失定义为下面的形式:
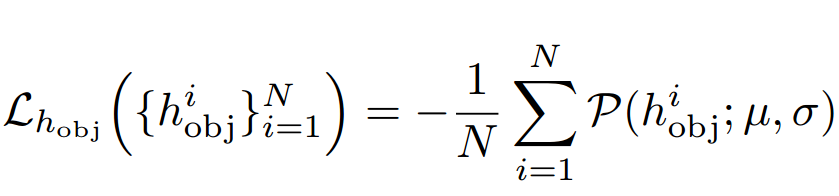

在预测得到前面的相机参数和目标参数基础上就可以开始预测相机的高度了。这一模块通过相机高度与2D bbox和其他相关参数间的几何约束来进行预测。例如在下图中,两个图片中都有站着的人,但水平线都不完整。粗略一看拍摄图片的相机都有相同的朝向,但高度却大相径庭。这样的情况下直接从图像进行估计会带来较大的误差,所以模型使用了中层的特征表达 (包括目标的bbox和估计出的水平线) 来进行相机估计,输入包含了光心、bbox、检测框的偏置以及目标高度共八个参数,最后通过预测出概率分布的加权平均得到相机的高度。

相似的bbox但相机高度差异很大
在获得相机高度后还需要进行级联优化。这一部分主要基于bbox的重投影误差来进行优化。例如下图中,重投影bbox (蓝) 小于图像中原来的bbox (绿) ,这就会产生重投影误差。为此网络会减小相机的高度以减小这一误差。后续模块估计出需要调整的残差与先前预测的值相加,最终一步步优化得到重投影误差满足要求的结果。
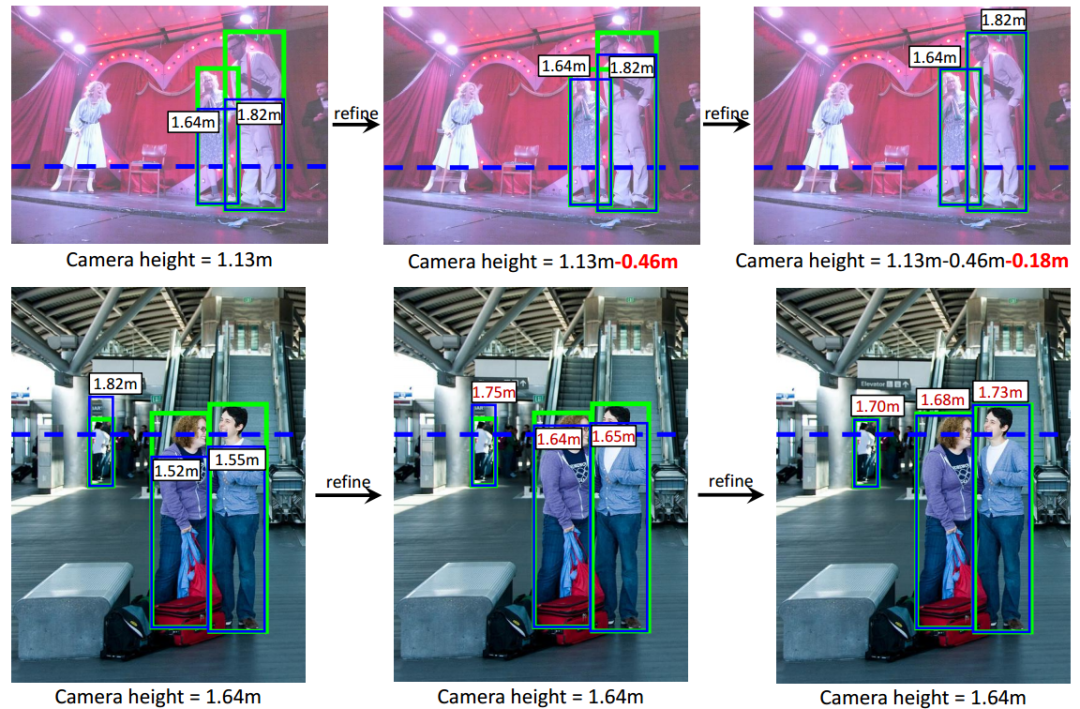
图中显示了重投影误差优化的过程,每次优化估计出需要调整的值并计算出最后的结果。上半部分显示了相机高度优化过程,下半部分显示了人体高度的优化过程。
通过各个阶段的参数估计和优化,整体网络的损失可以写成下面的形式,其中M是优化层数。
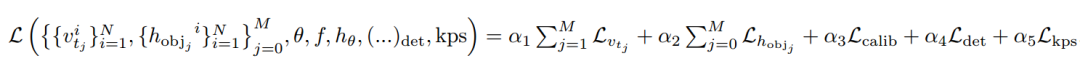
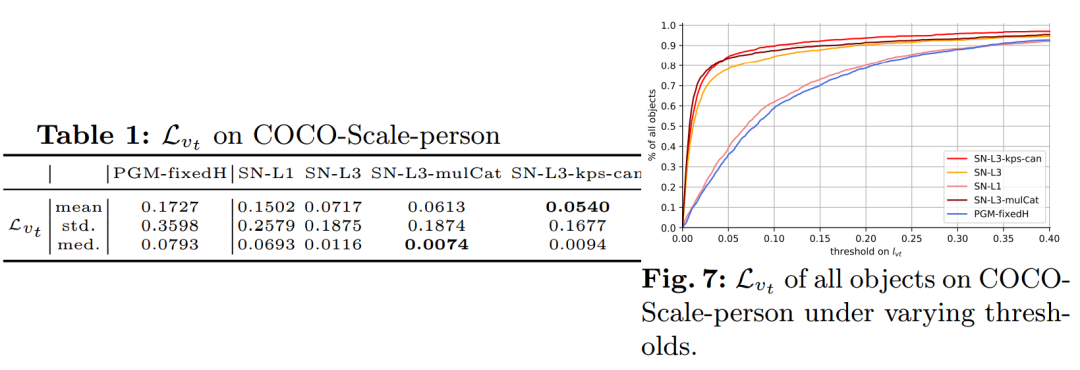
模型在筛选过的COCO数据集上进行了训练,并在KITTI和IMDB-23K数据集上进行了验证,下图展示本文提出模型的精度,相较于先前的PGM方法有了较大的提升:
下图是一些真实场景的测量结果,可以看到得到的结果非常符合我们日常经验。

对于道路场景来说,车辆的测量结果也非常令人满意:

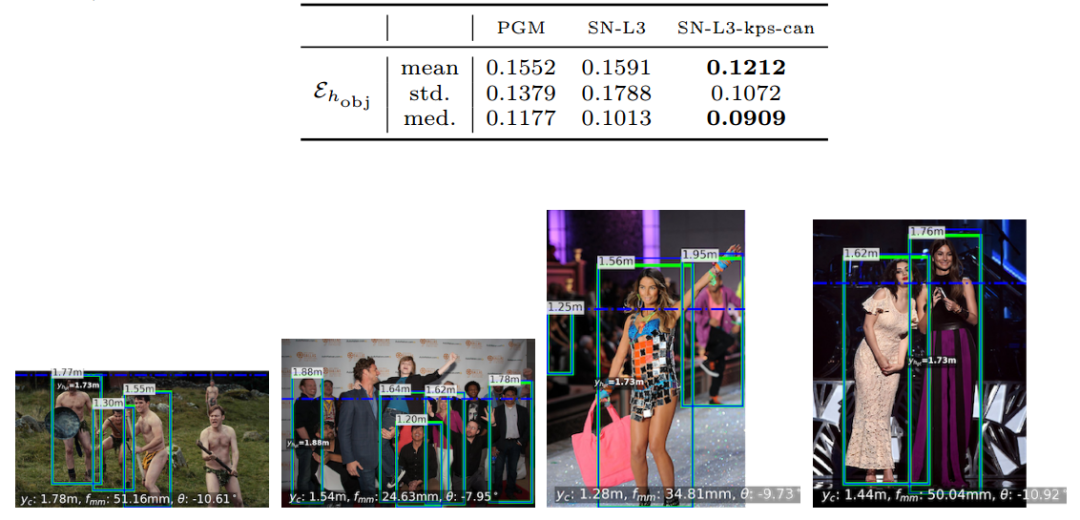
在IMDB中,由于IMDB官网里有明星的身高数据,这里的测量更为贴近实际,下图展示了测量的结果和数值指标:
更多详细信息,请参看论文细节:
http://www.ecva.net/papers/eccv_2020/papers_ECCV/html/1337_ECCV_2020_paper.php
更多实验结果和数据处理过程,可以在这里找到:
http://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123560307-supp.pdf
re:
https://www.cis.upenn.edu/~cis580/Spring2017/Lectures/cis580-08-singleViewMetrology2.pdf


听说12月19日有个Party…

AI人的年底聚会,就差你了!
好吃!好玩!免费!


扫码观看!
本周上新!

关于我“门”
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门技术社群以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给“门”:
bp@thejiangmen.com

点击右上角,把文章分享到朋友圈

扫二维码|关注我们
让创新获得认可!
微信号:thejiangmen
点击“❀在看”,让更多朋友们看到吧~