【强化学习落地应用】之FinRL生态系统,一种使用强化学习进行自动化交易的实践
深度强化学习实验室
“Finance serves a purpose. … Investors are lured to gamble their wealth on wide hunches originated by charlatans and encouraged by mass media. One day in the near future, ML will dominate finance, science will curtail guessing, and investing will not mean gambling.”
—-By Marcos Lopes De Prado
Advanced in Financial Machine Learning
关于FinRL生态系统(完整PDF文档见文章末尾)
Our Mission: to efficiently automate trading. We continuously develop and share codes for finance.
Our Vision: AI community has accumulated an open-source code ocean over the past decade. We believe applying these intellectual and engineering properties to finance will initiate a paradigm shift from the conventional trading routine to an automated machine learning approach, even RLOps in finance.
Materials:
AI4Finance Foundation:
FinRL, FinRL-Meta, and Website
ElegantRL and Website.
FinRL Ecosystem: Deep Reinforcement Learning to Automate Trading in Quantitative Finance. Talk at Wolfe Research 5th Annual Virtual Global Quantitative and Macro Investment Conference, Nov. 08, 2021.
Awesome_DRL4Finance_List: Awesome Deep Reinforcement Learning in Finance
Textbooks:
De Prado, M.L., 2018. Advances in financial machine learning. John Wiley & Sons.
Assessing this file on Google Doc at:
https://docs.google.com/document/d/1FxfdiwJ8L8xJeObPMIVFxi9ozykC9HujMuxYVYEmR5g/edit
关于FinRL
● Goals of FinRL
The design of a deep reinforcement learning trading strategy includes:
1. preprocessing market data,
2. building a training environment,
3. managing trading states,
4. and backtesting trading performance.
It is a very tedious debugging and error-prone programming process. The end-to-end pipeline is also pretty comprehensive.
FinRL’s Goal:
1. FinRL has a full pipeline to help quantitative traders overcome the steep learning curve.
2. FinRL implements fine-tuned state-of-the-art DRL algorithms and common reward functions, while alleviating the debugging workloads.
3. FinRL framework automatically streamlines the development of trading strategies, so as to help researchers and quantitative traders to iterate their strategies at a high turnover rate.
● Designing Principles
1. Full-stack framework. To provide a full-stack DRL framework with finance-oriented optimizations, including market data APIs, data preprocessing, DRL algorithms, and automated backtesting. Users can transparently make use of such a development pipeline.
2. Customization. To maintain modularity and extensibility in development by including state-of-the-art DRL algorithms and supporting design of new algorithms. The DRL algorithms can be used to construct trading strategies by simple configurations.
3. Reproducibility and hands-on tutoring. To provide tutorials such as step-by-step Jupyter notebooks and user guides to help users walk through the pipeline and reproduce the use cases.
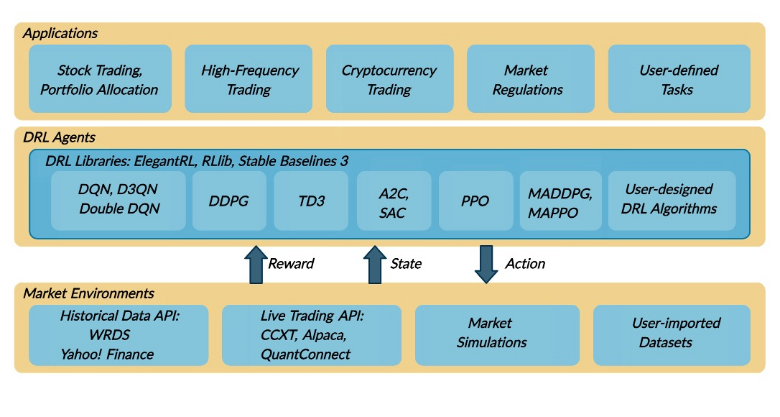
● Framework of FinRL
The FinRL framework has three layers: application layer, agent layer, and hu layer.
1. For the application layer, FinRL aims to provide hundreds of demonstrative trading tasks, serving as stepping stones for users to develop their strategies.
2. For the agent layer, FinRL supports fine-tuned DRL algorithms from DRL libraries in a plug-and-play manner, following the unified workflow.
3. For the environment layer, FinRL aims to wrap historical data and live trading APIs of hundreds of markets into training environments, following the de facto standard Gym.
关于ElegantRL
● Goals of ElegantRL
ElegantRL is designed for researchers and practitioners with finance-oriented optimizations.
1. ElegantRL implements state-of-the-art DRL algorithms from scratch, including both discrete and continuous ones, and provides user-friendly tutorials in Jupyter Notebooks.
2. The ElegantRL performs DRL algorithms under the Actor-Critic framework
3. The ElegantRL library enables researchers and practitioners to pipeline the disruptive “design, development and deployment” of DRL technology.
● Designing Principles
1. Lightweight: core codes have less than 1,000 lines, less dependable packages, only using PyTorch (train), OpenAI Gym (env), NumPy, Matplotlib (plot),
2. Efficient: in many testing cases, we find it more efficient than Ray RLlib. ElegantRL provides a cloud-native solution for RLOps in finance.
3. Stable: much more stable than Stable Baselines 3. Stable Baselines 3 can only use a single GPU, but ElegantRL can use 1~8 GPUs for stable training.
● Framework of ElegantRL
ElegantRL implements the following model-free deep reinforcement learning (DRL) algorithms:
● DDPG, TD3, SAC, PPO, PPO (GAE),REDQ for continuous actions
● DQN, DoubleDQN, D3QN, SAC for discrete actions
● QMIX, VDN; MADDPG, MAPPO, MATD3 for multi-agent environment
For the details of DRL algorithms, please check out the educational webpage OpenAI Spinning Up.
依赖包
Python:
● Confidence with Python programming, and familiar with Jupyter notebook, and Pycharm
● Familiar with Python scripts and executing them from the command line interface
● Familiar with numerical computing libraries: Numpy, and pandas.
Git and Github:
● Knowledge of basic Git commands
● Clone,fork, branch creation and checkout
● Git status, git add, git commit, git pull and git push
Software:
● Python and Anaconda Installation
● Git installation or Github desktop
Account:
● Github account
● Cloud: AWS account or Google Account
● Paper trading account: alpaca, binance
安装与初始化
Check this blog: FinRL Install and Setup Tutorial for Beginners for detailed instructions.
It includes instructions for:
● Mac OS
● AWS Ubuntu
● Windows 10
● Google Colab
书籍目录



细节内容

项目地址:
https://github.com/AI4Finance-Foundation
-----------------------------------------------------------------
pdf完整版获取方式: 点击左下方“阅读原文”,论坛中下载
-----------------------------------------------------------------





