N维图像的数据增强方法概览
编者按:伦敦帝国学院计算成像PhD学生Rob Robinson介绍了图像增强的主要方法及其Python实现。
进行有效的深度学习网络训练的最大限制因素是训练数据。为了很好地完成分类任务,我们需要给我们的CNN等模型尽可能多的样本。然而,并不是所有情况下都可能做到这一点,特别是处于一些训练数据很难收集的情形,比如医学影像数据。在本文中,我们将学习如何应用数据增强策略至n维图像,以充分利用数量有限的样本。
介绍
如果我们将任何图像(比如下面的机器人)整体向右移动一个像素,视觉上几乎毫无差别。然而,数值上这是两张完全不同的图像!想象一下有一组10张这样的图像,每张相对前一张平移一个像素。现在考虑图像[20, 25]处的像素或某个任意的位置。聚焦到这一点,每个像素有不同的颜色,不同的周边平均亮度,等等。一个CNN在进行卷积和决定权重时,会将这些考虑在内。如果我们将这组10张图像传给CNN,应该能够有效地让CNN学习忽略这类平移。

原图

向右平移1像素

向右平移10像素
当然,平移不是在保证视觉上看起来一样的前提下改动图像的唯一方式。考虑下将图片旋转1度,或者5度。它仍然是机器人。用不带平移和旋转版本的图像训练CNN可能导致CNN过拟合,认为所有机器人的图像都是不偏不倚的。
给深度学习模型提供平移、旋转、缩放、改变亮度、翻转的图像,我们称之为数据增强。
在本文中,我们将查看如何应用这些变换至图像,包括3D图像,及其对深度学习模型表现的影响。我们将使用flickr用户andy_emcee拍摄的照片作为2D自然图像的样本。由于这是一幅RGB(彩色)图像,因此它的形状为[512, 640, 3],每层对应一个色彩频道。我们可以抽掉一层,将图像转为灰度图像(真2D),不过我们处理的大部分图像都是彩色图像,因此我们这里保留原样。我们将使用3D MRI扫描图作为3D图像的样本。

RGB图像
增强
我们将使用python编写数据增强函数(基于numpy和scipy)。
平移
在我们的函数中,图像是一个2D或3D数组——如果它是一个3D数组,我们需要小心地在offset参数中指定方向。我们并不想在z方向上移动,原因如下:首先,如果这是一个2D图像,第三维将是色彩频道,如果我们在这一维度上移动了-2、2或更多,整个图像将变成全红、全蓝或全黑;其次,在全3D图像中,第三维常常是最小的,例如,在大多数医学扫描图像中。在下面的平移函数中,offset是一个长度为2的数组,定义了y和x方向的平移。我们硬编码z方向为0,不过,根据你的具体情况,你可以加以改动。为了确保我们平移的像素是整数,我们强制使用int。
def translateit(image, offset, isseg=False):
order = 0 if isseg == True else 5
return scipy.ndimage.interpolation.shift(image, (int(offset[0]), int(offset[1]), 0), order=order, mode='nearest')
当我们平移图像时,会在图像边缘留下一条缝隙。我们需要找到填补这一缝隙的方式:shift默认将使用一个常量(0)。但在某些情况下,这可能无济于事,所以最好将mode设为nearest,使用邻近的像素值填充。平移值较小时,几乎难以察觉这一点。不过平移值较大时,看起来就不对劲了。所以我们需要小心,仅对我们的数据应用较小的平移。
另外,我们提供了一个布尔值选项isseg,供选择order参数的值。isseg为真时(处理分割图),order为0,也就是直接使用最近的像素值填充;isseg为假时,order为5,也就是进行5次B样条插值(综合考量目标周围的许多像素)。
原图

右移5像素

右移25像素


原图、分割图


平移[-3, 1]像素
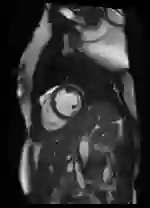

平移4, -5像素
缩放
我们根据一个特定的倍数(factor)缩放图像。倍数大于1.0时,放大图像;倍数小于1.0时,缩小图像。注意我们需要为每个维度指定倍数:其中,最后一个维度(2D图像中为色彩频道)倍数为1.0。我们使用栅格(网格)来决定结果图像每个像素的亮度(使用周围像素的亮度进行插值)。scipy提供了一个方便的函数,称为zoom。
定义大概要比你想象的复杂:
def scaleit(image, factor, isseg=False):
order = 0 if isseg == True else 3
height, width, depth= image.shape
zheight = int(np.round(factor * height))
zwidth = int(np.round(factor * width))
zdepth = depth
if factor < 1.0:
newimg = np.zeros_like(image)
row = (height - zheight) // 2
col = (width - zwidth) // 2
layer = (depth - zdepth) // 2
newimg[row:row+zheight, col:col+zwidth, layer:layer+zdepth] = interpolation.zoom(image, (float(factor), float(factor), 1.0), order=order, mode='nearest')[0:zheight, 0:zwidth, 0:zdepth]
return newimg
elif factor > 1.0:
row = (zheight - height) // 2
col = (zwidth - width) // 2
layer = (zdepth - depth) // 2
newimg = interpolation.zoom(image[row:row+zheight, col:col+zwidth, layer:layer+zdepth], (float(factor), float(factor), 1.0), order=order, mode='nearest')
extrah = (newimg.shape[0] - height) // 2
extraw = (newimg.shape[1] - width) // 2
extrad = (newimg.shape[2] - depth) // 2
newimg = newimg[extrah:extrah+height, extraw:extraw+width, extrad:extrad+depth]
return newimg
else:
return image
我们需要考虑三种可能性——放大、缩小、不变。在每种情形下,我们想要返回与输入图像尺寸相等的数组。缩小时,这牵涉创建一张大小形状和输入图像一致的空图像,并在当中相应的位置放入缩小后的图像。放大时,不需要放大整张图像,只需放大“缩放”的区域——因此我们只将数组的一部分传给zoom函数。取整可能造成最终形状中的一些误差,所以我们在返回图像前进行了一些修剪。不缩放时,我们返回原图。
原图


原图、分割图


缩放倍数1.07


缩放倍数0.95
重采样
有时我们需要修改图像,使其符合CNN的输入格式要求。例如,对大多数图像和照片而言,一个维度比另一个维度大,或者分辨率参差不齐。而大多数CNN需要尺寸一致的正方形输入。我们同样可以使用scipy函数interpolation.zoom办到这一点:
def resampleit(image, dims, isseg=False):
order = 0 if isseg == True else 5
image = interpolation.zoom(image, np.array(dims)/np.array(image.shape, dtype=np.float32), order=order, mode='nearest')
if image.shape[-1] == 3: # rgb图像
return image
else:
return image if isseg else (image-image.min())/(image.max()-image.min())
这里的关键部分是我们将factor参数替换为类型为列表的dims参数。dims的长度应当和图像的维度相等,即,2或3. 我们计算每个维度需要改变的倍数以将整个图像变动到dims目标。
在这一步中,当图像不是分割图时,我们同时将图像的亮度转换至0.0至1.0区间,以确保所有图像的亮度位于同一区间。
旋转
我们利用了另一个scipy函数rotate。它的theta参数接受一个浮点数,用来指定旋转的角度(负数表示逆时针旋转)。我们想要返回和输入图像大小和形状相同的图像,因此使用了reshape = False。同样,我们需要指定order决定插值方法。rotate函数支持3D图像,使用相同的theta值旋转每个切片。
def rotateit(image, theta, isseg=False):
order = 0 if isseg == True else 5
return rotate(image, float(theta), reshape=False, order=order, mode='nearest')
原图

theta = -10.0





亮度变动
我们还可以缩放像素的亮度,也就是加亮或压暗图像。我们指定一个倍数:倍数小于1.0将压暗图像;倍数大于1.0将加亮图像。注意倍数不能为0.0,否则会得到全黑的图像。
def intensifyit(image, factor):
return image*float(factor)
翻转
对自然图像(狗、猫、风景等)而言,最常见的图像增强过程是翻转。其依据是不管狗朝向哪一边,始终是狗。不管树在右边还是在左边,它仍然是一棵树。
我们可以进行左右翻转,也可以进行上下翻转。有可能只有一种翻转有意义(比如,我们知道狗不能通过它们的头行走)。我们通过由2个布尔值组成的列表指定如何进行翻转:如果每个值都是1,那么同时进行两种翻转。我们使用numpy函数fliplr和flipup。
def flipit(image, axes):
if axes[0]:
image = np.fliplr(image)
if axes[1]:
image = np.flipud(image)
return image
剪切
这可能是一个小众的函数,但在我的案例中很重要。处理自然图像时,常常在图像上进行随机剪切,以得到补丁——这些补丁常常包含大部分图像数据,例如,基于299 x 299图像得到的224 x 224补丁。这不过是另一种给网络提供视觉上非常相似而数值上完全不同的图像的方法。同时也进行中央剪切。我的案例有一个不同的需求,我希望提供给网络的图像中,分割永远是完全可见的(我处理的是3D心脏MRI分割)。
所以下面的函数查找分割,然后创建一个包围盒。我们将生成“正方形”分割,边长等于图像的宽度(最短边之长,不计入深度)。在这一情形下,创建了包围盒之后,如有必要,上下移动窗口以确保整个分割可见。函数同时确保输出总是正方形的,即使包围盒部分移出图像数组的界限。
def cropit(image, seg=None, margin=5):
fixedaxes = np.argmin(image.shape[:2])
trimaxes = 0 if fixedaxes == 1 else 1
trim = image.shape[fixedaxes]
center = image.shape[trimaxes] // 2
print image.shape
print fixedaxes
print trimaxes
print trim
print center
if seg is not None:
hits = np.where(seg!=0)
mins = np.argmin(hits, axis=1)
maxs = np.argmax(hits, axis=1)
if center - (trim // 2) > mins[0]:
while center - (trim // 2) > mins[0]:
center = center - 1
center = center + margin
if center + (trim // 2) < maxs[0]:
while center + (trim // 2) < maxs[0]:
center = center + 1
center = center + margin
top = max(0, center - (trim //2))
bottom = trim if top == 0 else center + (trim//2)
if bottom > image.shape[trimaxes]:
bottom = image.shape[trimaxes]
top = image.shape[trimaxes] - trim
if trimaxes == 0:
image = image[top: bottom, :, :]
else:
image = image[:, top: bottom, :]
if seg is not None:
if trimaxes == 0:
seg = seg[top: bottom, :, :]
else:
seg = seg[:, top: bottom, :]
return image, seg
else:
return image
注意,即使在不给定分割的情况下,该函数仍能剪切出正方形图像。
原图

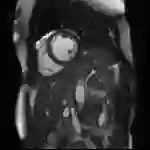

应用
应用转换函数时需要小心。例如,如果我们对同一图像应用多种转换,我们需要确保不在“改变亮度”后进行“重采样”,否则将重置图像的亮度区间,抵消“改变亮度”的效果。不过,由于我们通常希望数据处于同一区间,全图亮度平移很少见。我们同时也希望确保我们对数据增强不过分狂热——倍数和其他参数需要设定限制。
当我实现数据增强时,我将所有转换函数放在一个脚本transform.py中,之后在其他脚本中调用该脚本的函数。
我们在一定范围内随机抽取增强参数(避免过于极端的增强参数),以及需要进行的增强类型(我们并不打算每次应用所有增强)。
np.random.seed()
numTrans = np.random.randint(1, 6, size=1)
allowedTrans = [0, 1, 2, 3, 4]
whichTrans = np.random.choice(allowedTrans, numTrans, replace=False)
我们每次分配一个新的random.seed,以确保每次运行和上次运行不同。共有5种可能的增强类型,所以numTrans是1到5之间的随机整数。我们不想重复应用相同类型的增强,所以replace设为False。
经过一些试错,我发现以下参数比较好:
旋转 theta ∈ [−10.0,10.0]度
缩放 factor ∈ [0.9,1.1],即,10%的放大或缩小
亮度 factor ∈ [0.8,1.2],即,20%的增减
平移 offset ∈ [−5,5]像素
边缘 我倾向于设置为5到10个像素
来看一个例子吧。假设图像为thisim,分割为thisseg:
if 0 in whichTrans:
theta = float(np.around(np.random.uniform(-10.0,10.0, size=1), 2))
thisim = rotateit(thisim, theta)
thisseg = rotateit(thisseg, theta, isseg=True) if withseg else np.zeros_like(thisim)
if 1 in whichTrans:
scalefactor = float(np.around(np.random.uniform(0.9, 1.1, size=1), 2))
thisim = scaleit(thisim, scalefactor)
thisseg = scaleit(thisseg, scalefactor, isseg=True) if withseg else np.zeros_like(thisim)
if 2 in whichTrans:
factor = float(np.around(np.random.uniform(0.8, 1.2, size=1), 2))
thisim = intensifyit(thisim, factor)
# 不改变分割图的亮度
if 3 in whichTrans:
axes = list(np.random.choice(2, 1, replace=True))
thisim = flipit(thisim, axes+[0])
thisseg = flipit(thisseg, axes+[0]) if withseg else np.zeros_like(thisim)
if 4 in whichTrans:
offset = list(np.random.randint(-5,5, size=2))
currseg = thisseg
thisim = translateit(thisim, offset)
thisseg = translateit(thisseg, offset, isseg=True) if withseg else np.zeros_like(thisim)
在每种情形下,寻找一组随机参数,传给转换函数。图像和分割图分别传给转换函数。在我的例子中,我只通过随机选择0或1进行水平翻转,并附加[0]使转换函数忽略第二轴。另外加入了一个布尔值变量withseg,其为真时增强分割图,否则返回一张空图像。
最后,我们剪切图像为正方形,然后重采样至所需dims。
thisim, thisseg = cropit(thisim, thisseg)
thisim = resampleit(thisim, dims)
thisseg = resampleit(thisseg, dims, isseg=True) if withseg else np.zeros_like(thisim)
将这些都放在同一脚本中,以便于测试增强。关于这个脚本,有一些需要说明的地方:
脚本接受一个必选参数(图像文件名)和一个可选分割图文件名
脚本中包含一点检测错误的逻辑——文件能否加载?它是rgb图像还是全3D图像(第三维大于3)?
我们指定最终图像的维度,例如[224, 224, 8]
我们同时为参数声明了一些默认值……
……以便在最后打印出应用的转换及其参数
定义了一个plotit函数,该函数创建一个2 x 2矩阵,其中上面两张图像是原图,下面两张为增强图像
注释掉的部分是我用来保存本文创建的图像的代码
在一个在线设定下,我们希望即时进行数据增强。基本上,我们将调用这一脚本,接受一些待增强的文件名或图像矩阵,然后创建我们想要的增强。
原文地址:https://mlnotebook.github.io/post/dataaug/





