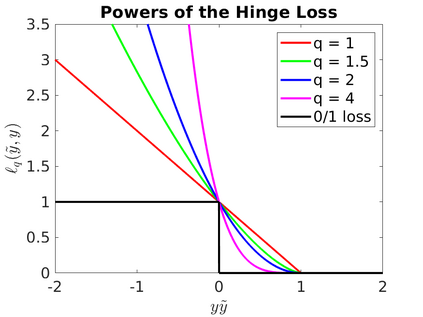
In this monograph, I introduce the basic concepts of Online Learning through a modern view of Online Convex Optimization. Here, online learning refers to the framework of regret minimization under worst-case assumptions. I present first-order and second-order algorithms for online learning with convex losses, in Euclidean and non-Euclidean settings. All the algorithms are clearly presented as instantiation of Online Mirror Descent or Follow-The-Regularized-Leader and their variants. Particular attention is given to the issue of tuning the parameters of the algorithms and learning in unbounded domains, through adaptive and parameter-free online learning algorithms. Non-convex losses are dealt through convex surrogate losses and through randomization. The bandit setting is also briefly discussed, touching on the problem of adversarial and stochastic multi-armed bandits. These notes do not require prior knowledge of convex analysis and all the required mathematical tools are rigorously explained. Moreover, all the proofs have been carefully chosen to be as simple and as short as possible.
翻译:在本专著中,我通过在线隐形优化的现代观点,介绍了在线学习的基本概念。这里,在线学习指的是在最坏假设下尽量减少遗憾的框架。我介绍了在Euclidean和非Euclidean设置中,以隐形损失进行在线学习的第一阶和第二阶算法。所有算法都明显地以在线光源即时化或跟踪Regulized-Leader及其变体的形式呈现。特别注意调整算法参数和在无约束域的学习参数的问题,通过适应性和无参数在线学习算法。非隐形损失是通过Convex代谢损失和随机化处理的。还简要地讨论了土匪问题。这些说明并不需要事先了解Convex分析,而是严格地解释所有所需的数学工具。此外,所有证据都经过仔细选择,以便尽可能简单和简短。