ICCV 2019 Oral | 三维"ZAO"脸,单张图片估计人脸几何,效果堪比真实皮肤

本文来自公众号 我爱计算机视觉 我爱计算机视觉,AI科技评论 获授权转载,如需转载请联系原公众号。
本文为52CV群友上海科技大学陈安沛同学投稿,介绍了他们ICCV 2019最新人脸3D重建的工作。效果非常赞,代码也已开源,欢迎大家参考~
引言
相比于最近几天刷遍朋友圈的“ZAO-缝脸造戏“和 "DeepFake" ,今天我们提升一个维度,为给大家介绍如何从2D图片,"ZAO"出超逼真的3D人脸 。
这项工作已经被ICCV'19接收为Oral paper。
摘要
如何通过单张图片恢复高质量的三维人脸是计算机视觉和图形学的重要研究领域,高质量的3D人脸通常指准确的几何、完整的纹理和真实的材质。
在本文中,我们使用单张图片恢复带有皱纹细节的人脸几何,我们的算法可以分成proxy estimation(基础参数化模型估计)和details synthesis两个部分。
对于proxy estimation,我们使用表情特征作为先验来应对3DMM参数估计时的ambiguity问题;
对于details synthesis,我们采集了366个高精度三维人脸作为监督学习样本,同时结合基于重渲染误差的无监督学习来恢复人脸细节的displacement map。

相关工作
前人在三维人脸几何估计方面已经做有很多非常出色的工作,大致分为以下三个流派:
以视频为输入的facial performance capture。这类人脸估计的主要侧重点在于人脸pose和表情的准确性与连续性。
单张图片估计proxy。这类方法又可分为基于landmark和基于appearance的,这部分研究主要追求脸型与表情的准确性。
人脸细节的估计。对于高频信息的恢复,传统算法往往是利用Photometric Stereo对人脸多次采样计算法向或使用Shape from Shading计算表面凹凸得到。而对基于深度学习的细节估计方法来说,一大难题在于目前较少有公开的图片(特别是in-the-wild)与高精度模型相对应的样本数据。
这篇文章在对前人proxy估计算法做了一定改进的同时把重点放在人脸细节估计上。对于proxy估计,我们发现目前众多算法估计出来的人脸不能充分表现输入图片中的人脸表情特征。而针对人脸细节估计的研究则相对较少。
算法流程
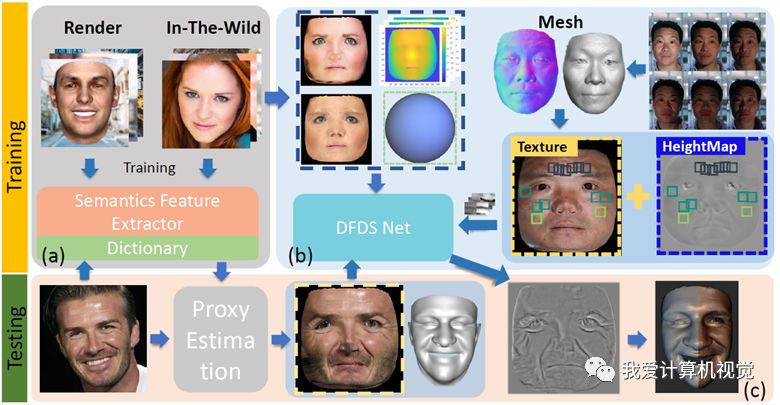
此项工作的思路是:
Proxy生成部分,我们使用emotion和Facial Action Coding System(FACS)表情特征作为先验来辅助基于facial landmark重投影误差的迭代优化。这部分的创新点在于表情特征可以有效捕捉到landmark无法表达的信息(比如法令纹),因此可以更好的约束proxy的估计。为了将表情特征与3DMM表情参数建立映射,如上图(a)所示,我们先用in-the-wild数据训练表情特征网络,然后通过3DMM渲染图片(表情参数已知)输入网络并获得对应的表情特征向量,以此建立feature dictionary。在inference的时候可以直接查找表情特征向量的nearest neighbor。
细节预测部分,我们的网络输入是一些小的patch,输出是这个patch对应的displacement map。训练的过程分为supervised和unsupervised两个部分:supervised部分我们使用采集的366个高精度人脸并提取细节displacement map作为训练样本;unsupervised部分我们使用in-the-wild图片首先离线地估计proxy,albedo和environment lighting,然后训练的时候构造一个re-rendering loss。
具体的算法,大家可以下载文章来读一下。
实验
实验这一小节我将按训练数据采集,proxy估计和details预测三个部分进行。
1. 数据采集
为了采集数据我们搭建了一套同时结合multi-view和photometric算法的高精度人脸重建系统,我们对122个人采集了他们三个不同的表情下的3D人脸,每一次拍摄我们会采集6张multi-view图片和5张偏振光照下的photometric图片,拍摄过程大概会花费两秒,而重建则需要五分时间。

重建出来的人脸模型是这样的:

2. Proxy
我们将使用比较多的eos人脸proxy估计算法作为baseline,分析对比了有和没有expression prior的效果,同时我们也和最近的一些基于人脸appearance信息估计3DMM的算法进行了对比,如下图:

准确的表情可以很大程度上提升人脸的辨识度和特征化,如上图所示,使用表情先验的几何看上去和原图更像,而without prior的结果更像平均脸。
3. Details
我们和一些现有的包含有细节的人脸几何估计算法进行视觉效果上的对比,为了让看的更加清楚,结果部分我们使用局部放大图如下,更多整体结果以及量化分析可以到论文以及附加材料里查看。
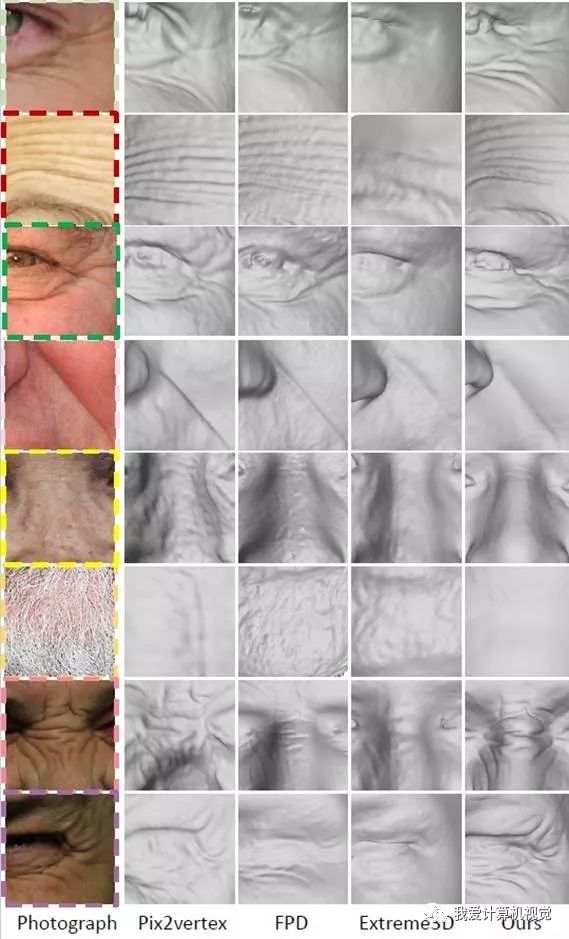
现有生成细节的算法大多基于shape from shading,这些方法的一个主要缺陷是生成的细节很像一般的物体而不考虑皮肤的spatial distribution。
而上述算法通过结合了光照模型和真实采集的细节数据,生成更接近真实的皮肤的结果。


附加材料里面提供了更多的结果:
Photo-Realistic Facial Details Synthesis from Single Image
https://arxiv.org/abs/1903.10873
这项工作已经在GitHub上开源!
这项工作已经在GitHub上开源!
这项工作已经在GitHub上开源!
https://github.com/apchenstu/Facial_Details_Synthesis
一点想法
做完这篇文章,一个比较深刻的体会是,不管人脸还是人体都很缺乏几何模型和in-the-wild图片的对应关系。
因为获取这样的数据是一个很难的问题,准确的几何往往需要特定的采集环境而没法采集到in-the-wild图片。
比较好的背景是,现在有好多生成非常高质量的人脸图片算法,同时也有很多几何合成算法。
如何在无标注样本情况下建立他们之间的联系(图片到几何和几何到in-the-wile图片)将是一个很有意义的方向。
最后非常感谢导师和队友们时常一起做实验和修改文章到深夜,也感谢大家愿意花时间读到这里。
很是惭愧,就做了一点微小的贡献,希望对大家有所帮助。
点击下方 阅读原文 查看CVPR 2019 计算机视觉最新趋势





