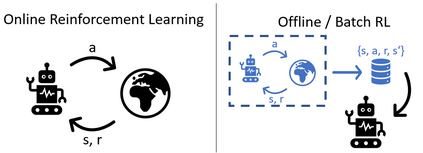
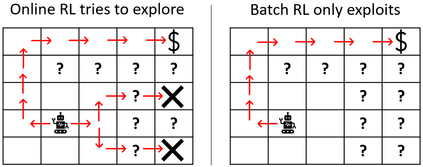
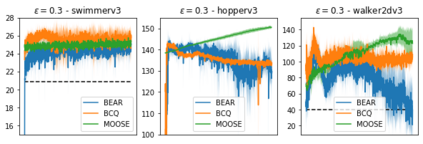
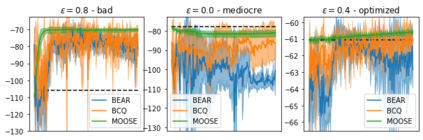
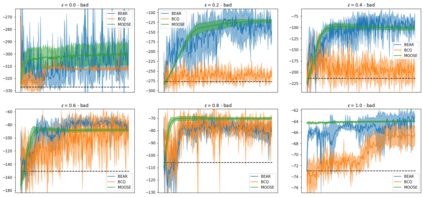
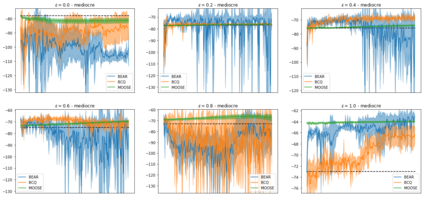
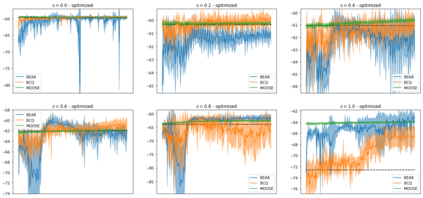
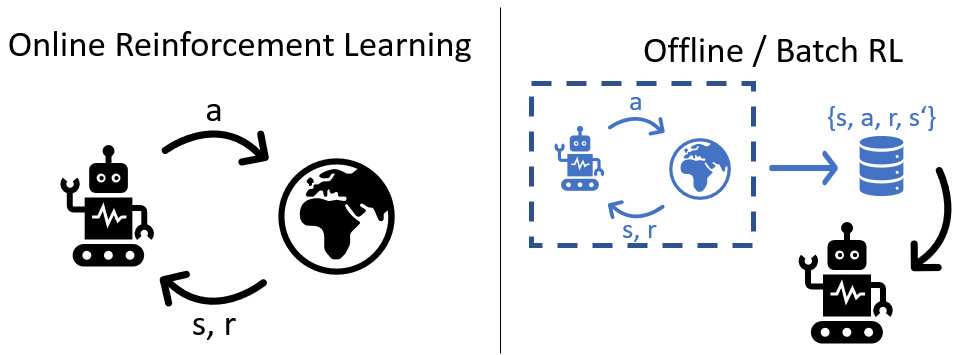
State-of-the-art reinforcement learning algorithms mostly rely on being allowed to directly interact with their environment to collect millions of observations. This makes it hard to transfer their success to industrial control problems, where simulations are often very costly or do not exist, and exploring in the real environment can potentially lead to catastrophic events. Recently developed, model-free, offline RL algorithms, can learn from a single dataset (containing limited exploration) by mitigating extrapolation error in value functions. However, the robustness of the training process is still comparatively low, a problem known from methods using value functions. To improve robustness and stability of the learning process, we use dynamics models to assess policy performance instead of value functions, resulting in MOOSE (MOdel-based Offline policy Search with Ensembles), an algorithm which ensures low model bias by keeping the policy within the support of the data. We compare MOOSE with state-of-the-art model-free, offline RL algorithms BEAR and BCQ on the Industrial Benchmark and MuJoCo continuous control tasks in terms of robust performance, and find that MOOSE outperforms its model-free counterparts in almost all considered cases, often even by far.
翻译:最先进的强化学习算法主要依靠被允许与其环境直接互动,以收集数以百万计的观测结果。这使得很难将其成功转移到工业控制问题,因为模拟往往费用高昂或不存在,而在实际环境中进行探索有可能导致灾难性事件。 最近开发的无模型的离线RL算法可以通过减少价值功能方面的外推误,从单一数据集(包含有限的探索)中学习。然而,培训过程的稳健性仍然相对较低,这是使用价值函数的方法所知道的一个问题。为了提高学习过程的稳健性和稳定性,我们使用动态模型来评估政策绩效,而不是评估价值函数,结果产生了MOOSE(以离线为基础的离线政策搜索与Ensembles),这种算法通过在数据支持范围内保持政策,确保了较低的模式偏差。我们把MOSE与最先进的无模型、离线的RL算法在工业基准和穆乔科连续控制任务中进行对比,发现即使业绩稳健,MOOSE也常常在考虑的所有情况下超越模型。