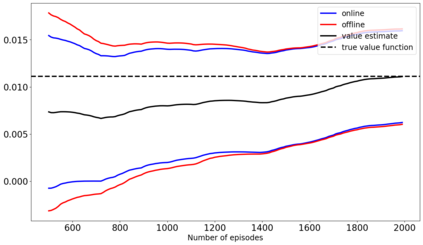
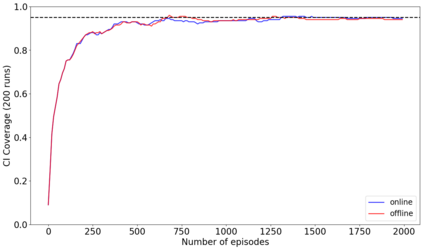
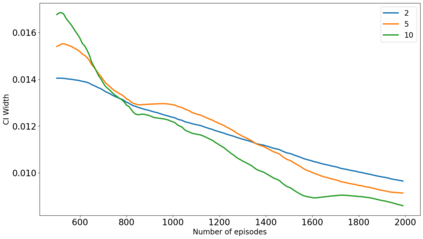
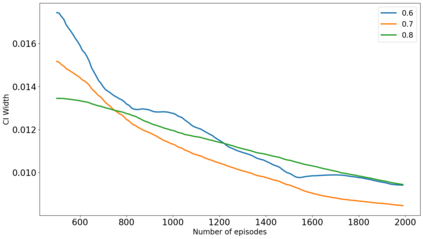
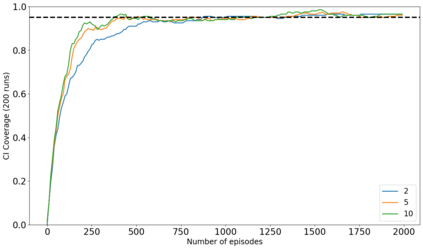
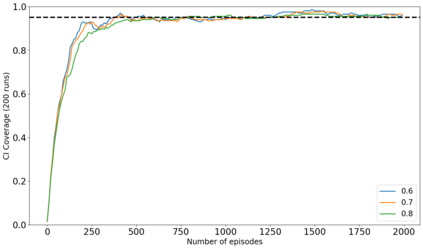
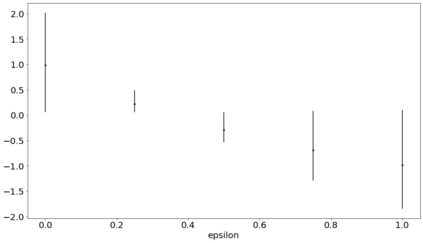
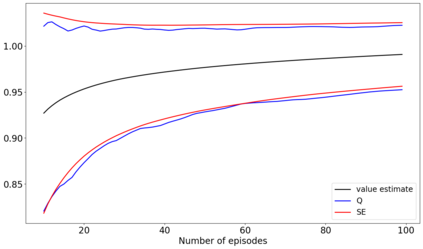
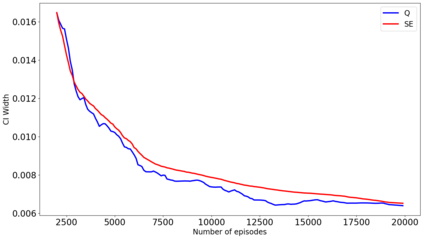
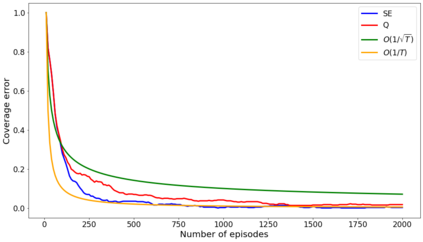
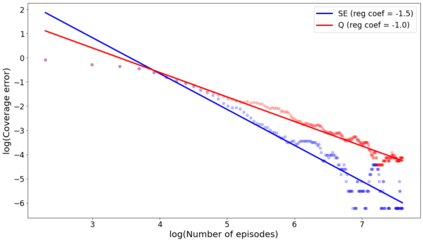
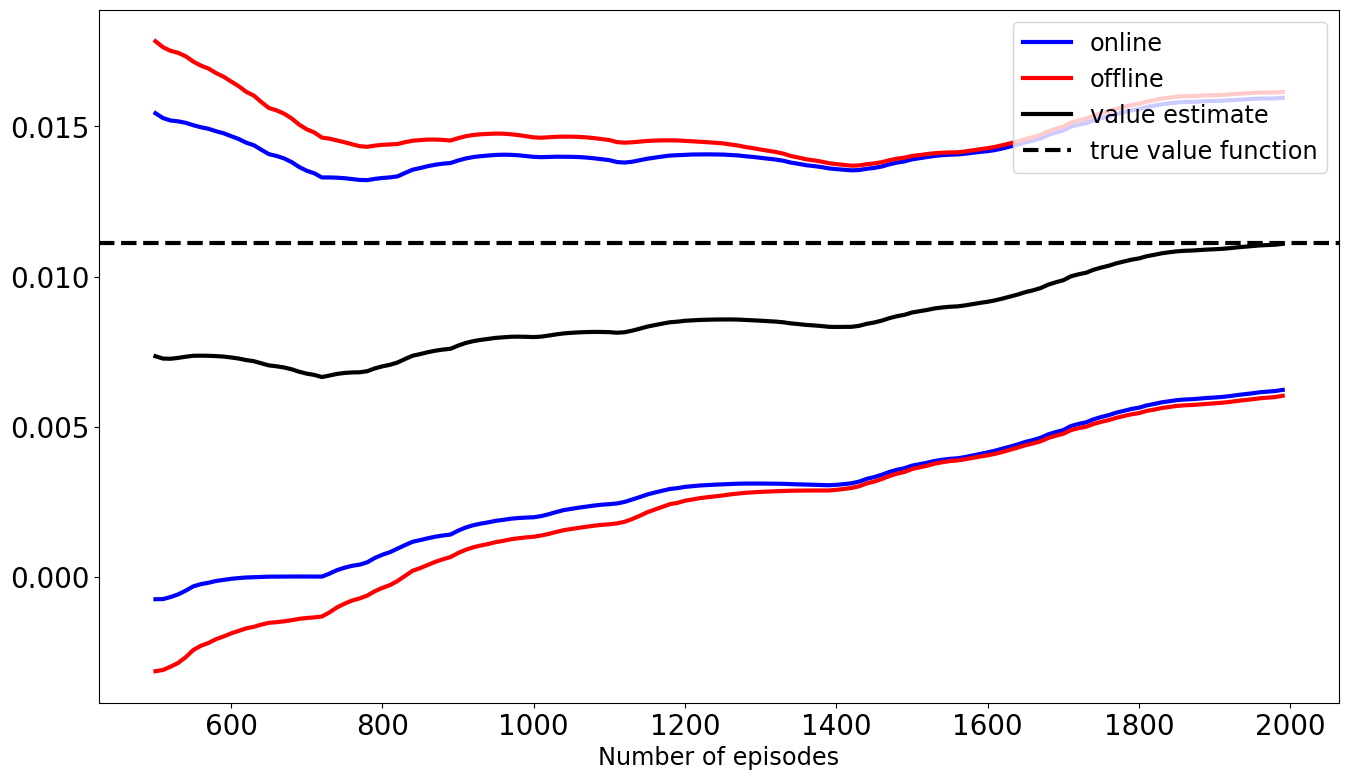
The recent emergence of reinforcement learning has created a demand for robust statistical inference methods for the parameter estimates computed using these algorithms. Existing methods for statistical inference in online learning are restricted to settings involving independently sampled observations, while existing statistical inference methods in reinforcement learning (RL) are limited to the batch setting. The online bootstrap is a flexible and efficient approach for statistical inference in linear stochastic approximation algorithms, but its efficacy in settings involving Markov noise, such as RL, has yet to be explored. In this paper, we study the use of the online bootstrap method for statistical inference in RL. In particular, we focus on the temporal difference (TD) learning and Gradient TD (GTD) learning algorithms, which are themselves special instances of linear stochastic approximation under Markov noise. The method is shown to be distributionally consistent for statistical inference in policy evaluation, and numerical experiments are included to demonstrate the effectiveness of this algorithm at statistical inference tasks across a range of real RL environments.
翻译:最近出现的强化学习产生了对使用这些算法计算参数估计的可靠统计推断方法的需求。现有的在线学习统计推断方法仅限于涉及独立抽样观察的环境,而现有的强化学习统计推断方法(RL)仅限于批量环境。在线靴子是一种灵活而有效的方法,用于线性随机近似算法中的统计推断,但其在涉及Markov噪音(如RL)的环境中的效力仍有待于探索。在本文中,我们研究了使用在线靴套方法进行RL的统计推断。特别是,我们侧重于时间差异(TD)学习和梯度TD(GTD)学习算法,这些算法本身就是Markov噪音下线性随机近似的特殊例子。该方法在政策评估中的统计推论中分布一致,并包含数字实验,以在一系列真实的RL环境中的统计推论任务中证明这一算法的有效性。