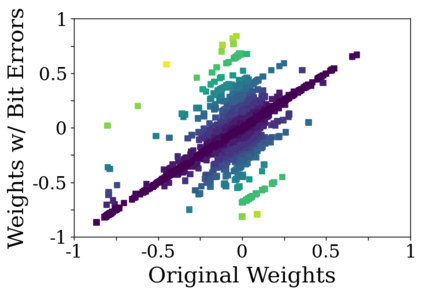
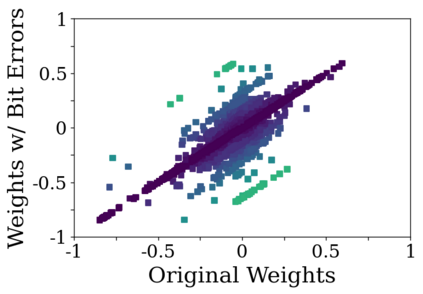
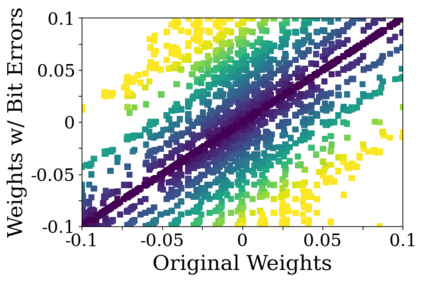
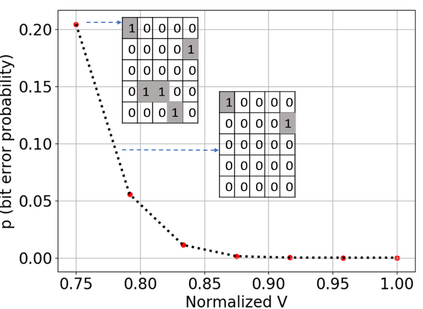
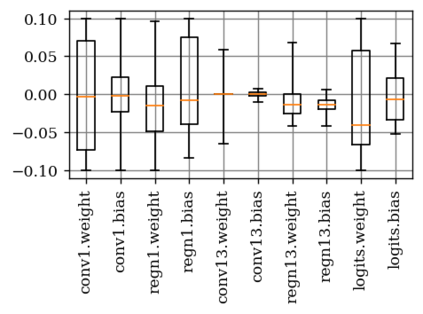
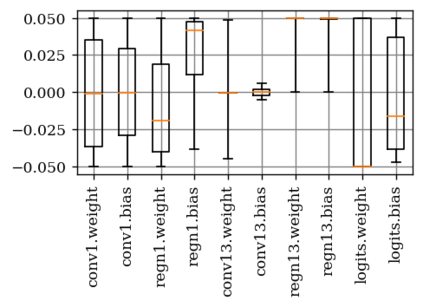
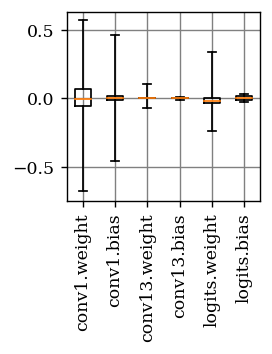
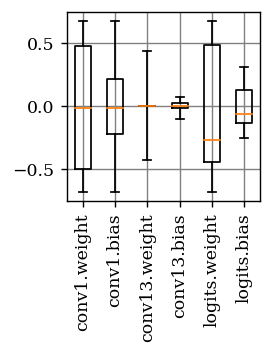
Deep neural network (DNN) accelerators received considerable attention in past years due to saved energy compared to mainstream hardware. Low-voltage operation of DNN accelerators allows to further reduce energy consumption significantly, however, causes bit-level failures in the memory storing the quantized DNN weights. In this paper, we show that a combination of robust fixed-point quantization, weight clipping, and random bit error training (RandBET) improves robustness against random bit errors in (quantized) DNN weights significantly. This leads to high energy savings from both low-voltage operation as well as low-precision quantization. Our approach generalizes across operating voltages and accelerators, as demonstrated on bit errors from profiled SRAM arrays. We also discuss why weight clipping alone is already a quite effective way to achieve robustness against bit errors. Moreover, we specifically discuss the involved trade-offs regarding accuracy, robustness and precision: Without losing more than 1% in accuracy compared to a normally trained 8-bit DNN, we can reduce energy consumption on CIFAR-10 by 20%. Higher energy savings of, e.g., 30%, are possible at the cost of 2.5% accuracy, even for 4-bit DNNs.
翻译:深海神经网络(DNN) 加速器(DNN) 与主流硬件相比,在过去几年里由于节能与主流硬件相比节省了能源而得到了相当的注意。 DNN加速器的低压操作使得能耗进一步减少能源消耗,然而,这却导致存储量化的 DNN 重量的记忆中出现位数差错。在本文中,我们展示了强力的固定点量化、减重和随机位误差训练(RandBET)的结合,提高了对(量化的) DNN 重量中随机位差错的稳健性。这导致低压操作以及低精度量化的量化都带来高节能节约。我们的方法在运行电压和加速器中的通用化点差错中造成了位数级故障。我们在剖析的 SRAM 阵列中展示了点差差差差差差,我们还探讨了为什么单点减重已经是实现稳健防止位误差错的相当有效的方法。 此外,我们具体讨论了在准确性、稳健性和精确性方面所涉及的折衷性:与通常训练的DNNNN(e-NNN) 和低精度的DNNNNNDQ 30) 节能消耗成本超过1%,我们可以降低25的准确性能源消耗成本为20。