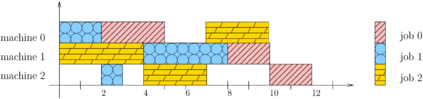
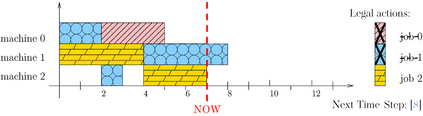
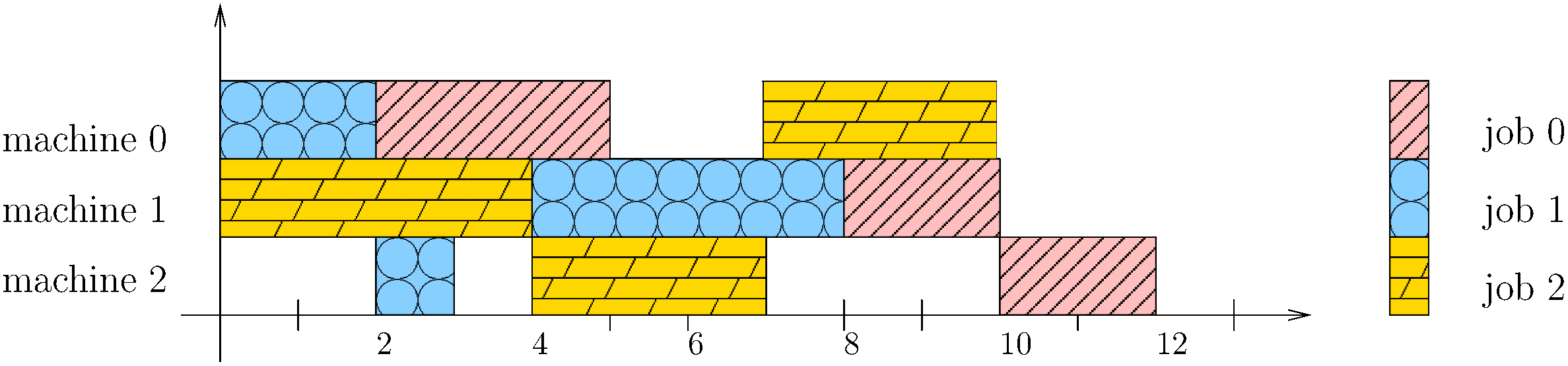
Scheduling is a fundamental task occurring in various automated systems applications, e.g., optimal schedules for machines on a job shop allow for a reduction of production costs and waste. Nevertheless, finding such schedules is often intractable and cannot be achieved by Combinatorial Optimization Problem (COP) methods within a given time limit. Recent advances of Deep Reinforcement Learning (DRL) in learning complex behavior enable new COP application possibilities. This paper presents an efficient DRL environment for Job-Shop Scheduling -- an important problem in the field. Furthermore, we design a meaningful and compact state representation as well as a novel, simple dense reward function, closely related to the sparse make-span minimization criteria used by COP methods. We demonstrate that our approach significantly outperforms existing DRL methods on classic benchmark instances, coming close to state-of-the-art COP approaches.
翻译:时间安排是各种自动化系统应用中出现的一项根本任务,例如,工作场所机器的最佳时间安排可以降低生产成本和浪费,然而,找到这种时间安排往往是棘手的,无法在一定时限内通过混合优化问题(COP)方法实现,深强化学习在学习复杂行为方面的最新进展使得新的缔约方会议应用可能性成为可能。本文件为工作-休闲时间安排提供了一个高效的DRL环境 -- -- 实地的一个重要问题。此外,我们设计了一种有意义和紧凑的国家代表制,以及一种与缔约方会议方法所使用的稀有的制造宽度最小化标准密切相关的新的、简单密集的奖励功能。我们证明,我们的方法大大超越了传统基准实例的现有DRL方法,接近于最先进的COP方法。