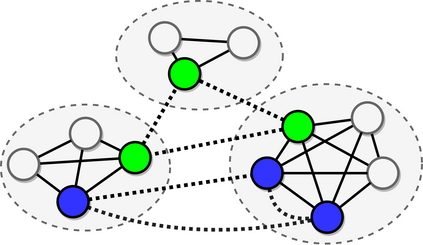
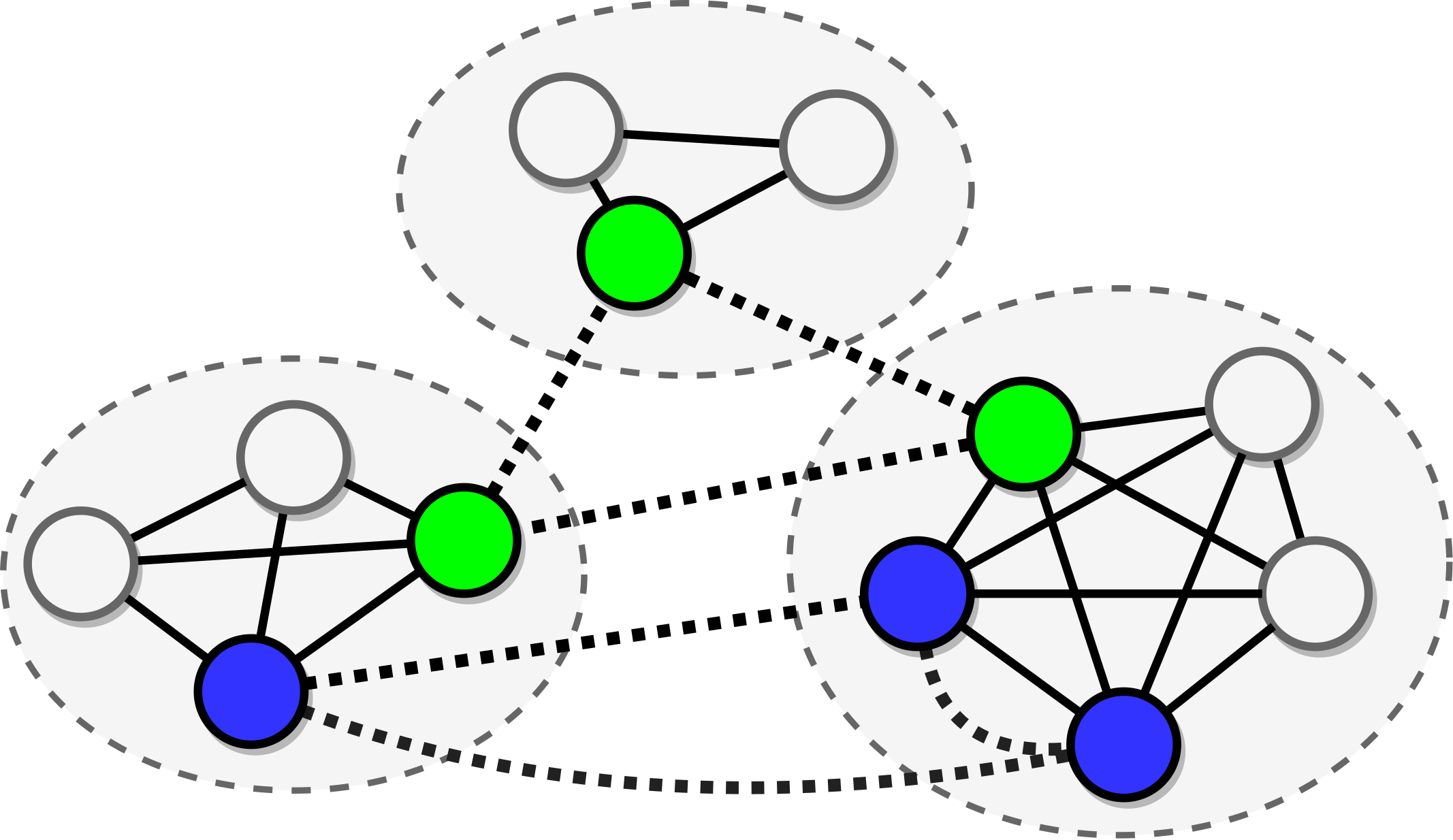
Most research in reading comprehension has focused on answering questions based on individual documents or even single paragraphs. We introduce a method which integrates and reasons relying on information spread within documents and across multiple documents. We frame it as an inference problem on a graph. Mentions of entities are nodes of this graph where edges encode relations between different mentions (e.g., within- and cross-document co-references). Graph convolutional networks (GCNs) are applied to these graphs and trained to perform multi-step reasoning. Our Entity-GCN method is scalable and compact, and it achieves state-of-the-art results on the WikiHop dataset (Welbl et al. 2017).
翻译:阅读理解方面的多数研究侧重于根据单个文件或甚至单个段落回答问题。我们采用了一种方法,根据在文件内部和多个文件之间传播的信息整合信息并给出理由。我们把它作为图表中的一个推论问题。提到实体是该图的节点,其中显示不同提及(例如,内部和交叉文件共同参考)之间的关系。图集网络(GCN)应用到这些图表中,并经过培训以进行多步推理。我们的实体-GCN方法可以缩放和紧凑,在WikiHop数据集(Welbl等人,2017年)上取得了最新结果。