
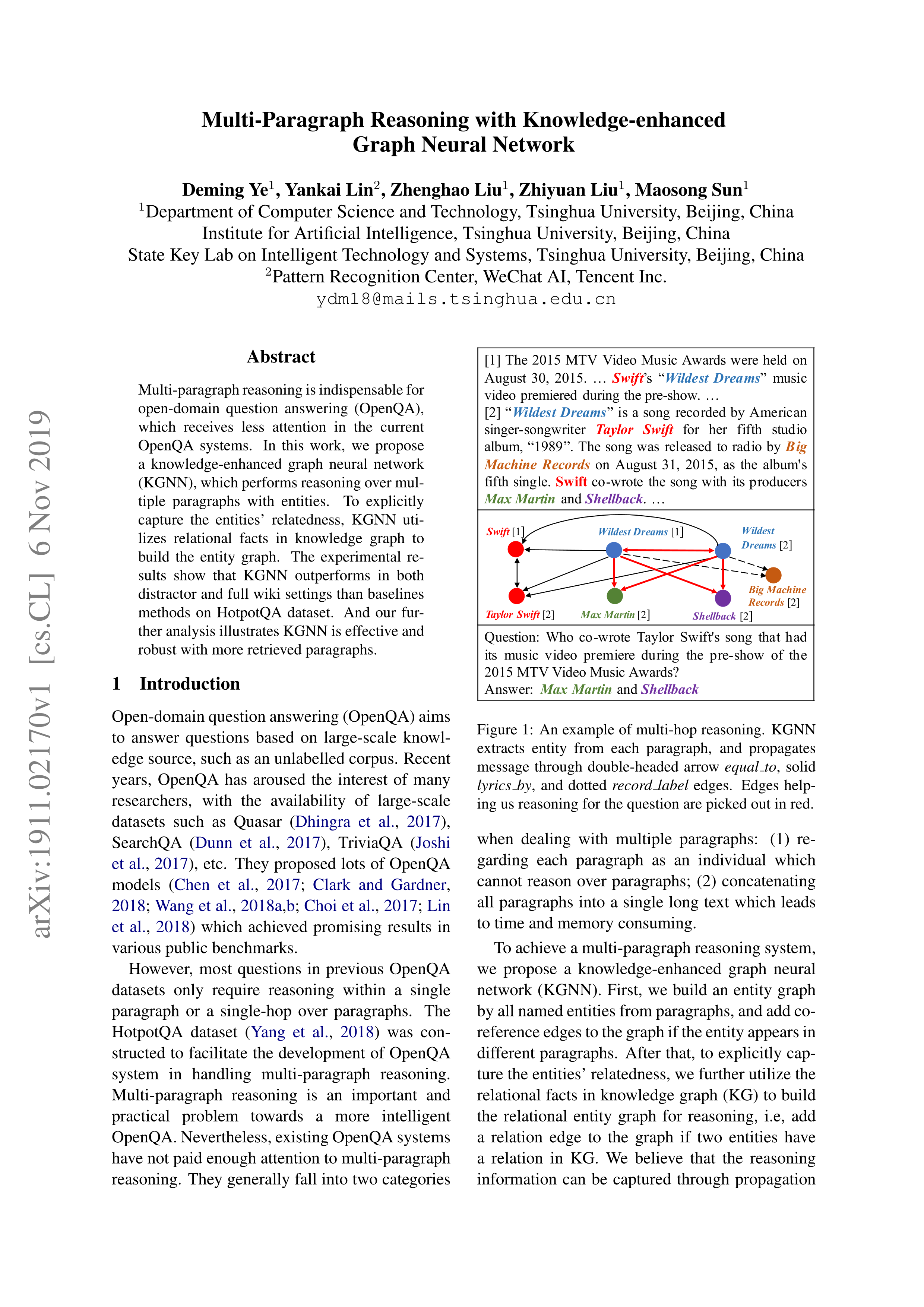
论文摘要: Multi-paragraph推理对于open-domain问答(OpenQA)是必不可少的,尽管在当前的OpenQA系统中受到的关注较少。在这项工作中,我们提出一个知识增强图神经网络(KGNN),使用实体对多个段落进行推理。为了显式地捕捉到实体的关系,KGNN利用关系事实知识图谱构建实体图谱。实验结果表明,与HotpotQA数据集上的基线方法相比,KGNN在分散注意力和完整的wiki设置方面都有更好的表现。我们进一步的分析表明,KGNN在检索更多的段落方面是有效和具有鲁棒性的。
成为VIP会员查看完整内容
相关内容

知识图谱(Knowledge Graph),在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。
知识图谱是通过将应用数学、图形学、信息可视化技术、信息科学等学科的理论与方法与计量学引文分析、共现分析等方法结合,并利用可视化的图谱形象地展示学科的核心结构、发展历史、前沿领域以及整体知识架构达到多学科融合目的的现代理论。它能为学科研究提供切实的、有价值的参考。
专知会员服务
99+阅读 · 2020年7月3日
专知会员服务
108+阅读 · 2020年3月29日
专知会员服务
113+阅读 · 2020年1月29日
专知会员服务
52+阅读 · 2020年1月20日
Arxiv
19+阅读 · 2019年11月20日
相关主题




相关VIP内容
专知会员服务
99+阅读 · 2020年7月3日
专知会员服务
108+阅读 · 2020年3月29日
专知会员服务
113+阅读 · 2020年1月29日
专知会员服务
52+阅读 · 2020年1月20日
相关资讯
相关论文
Arxiv
19+阅读 · 2019年11月20日