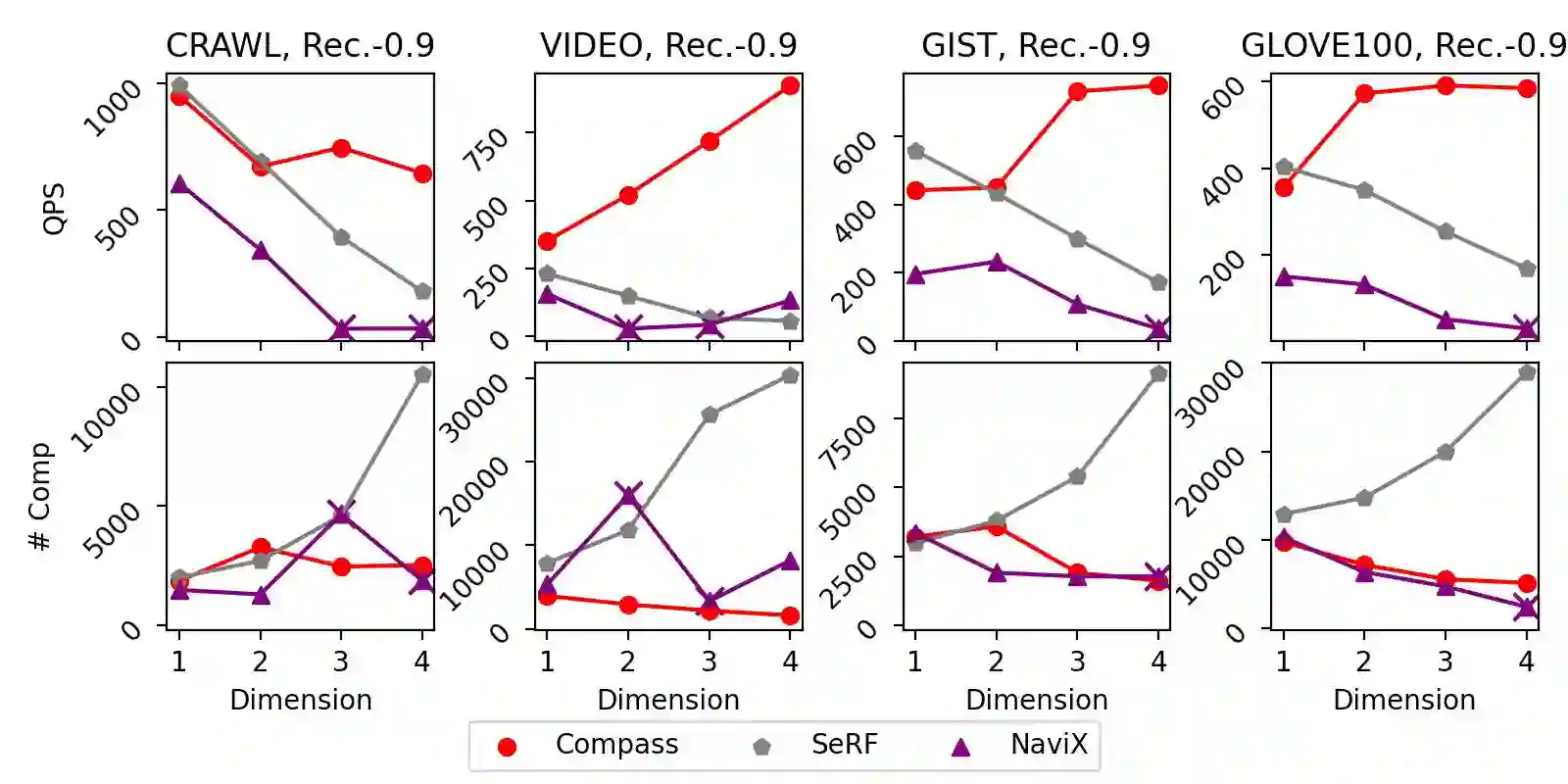
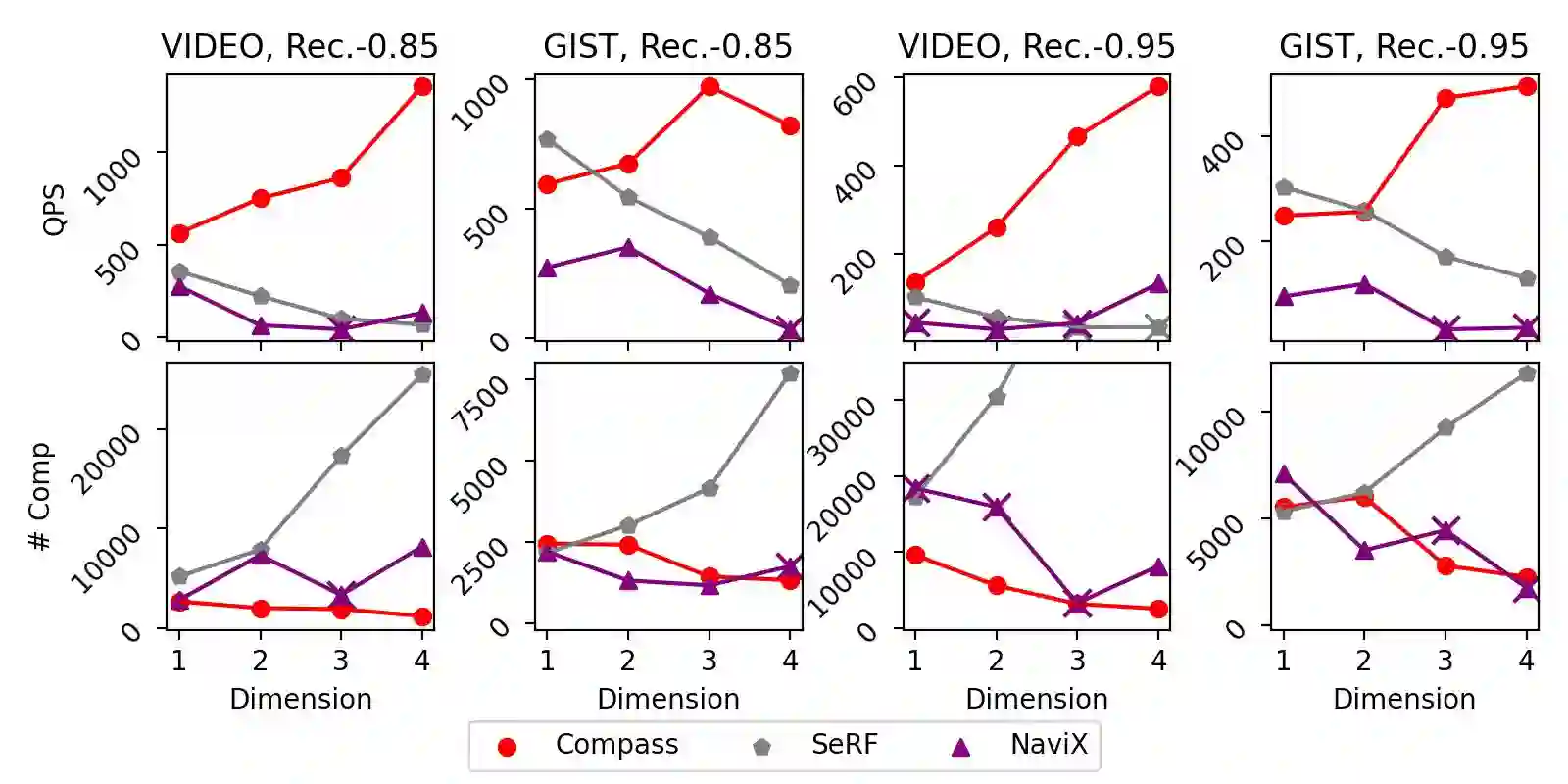
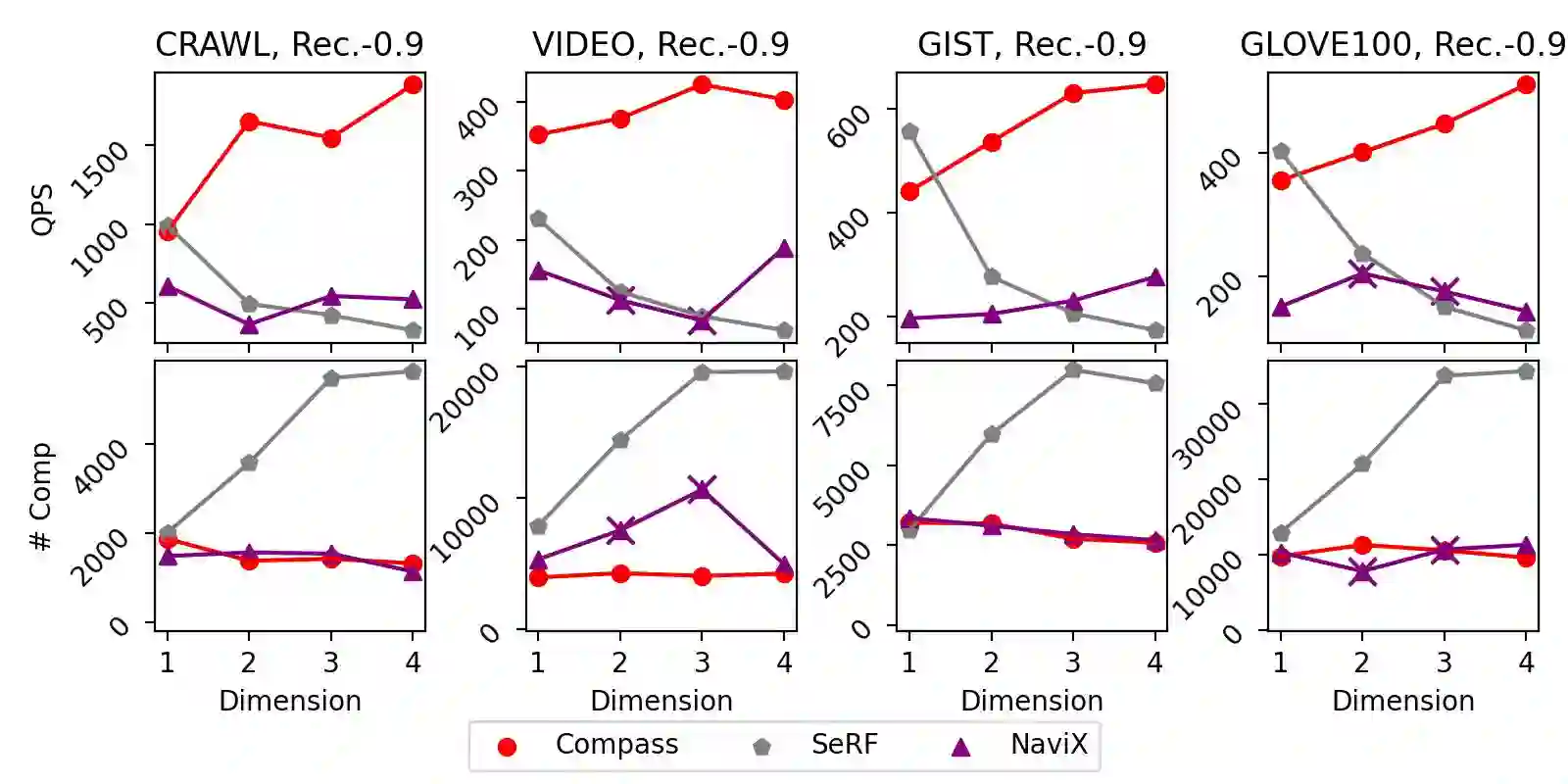
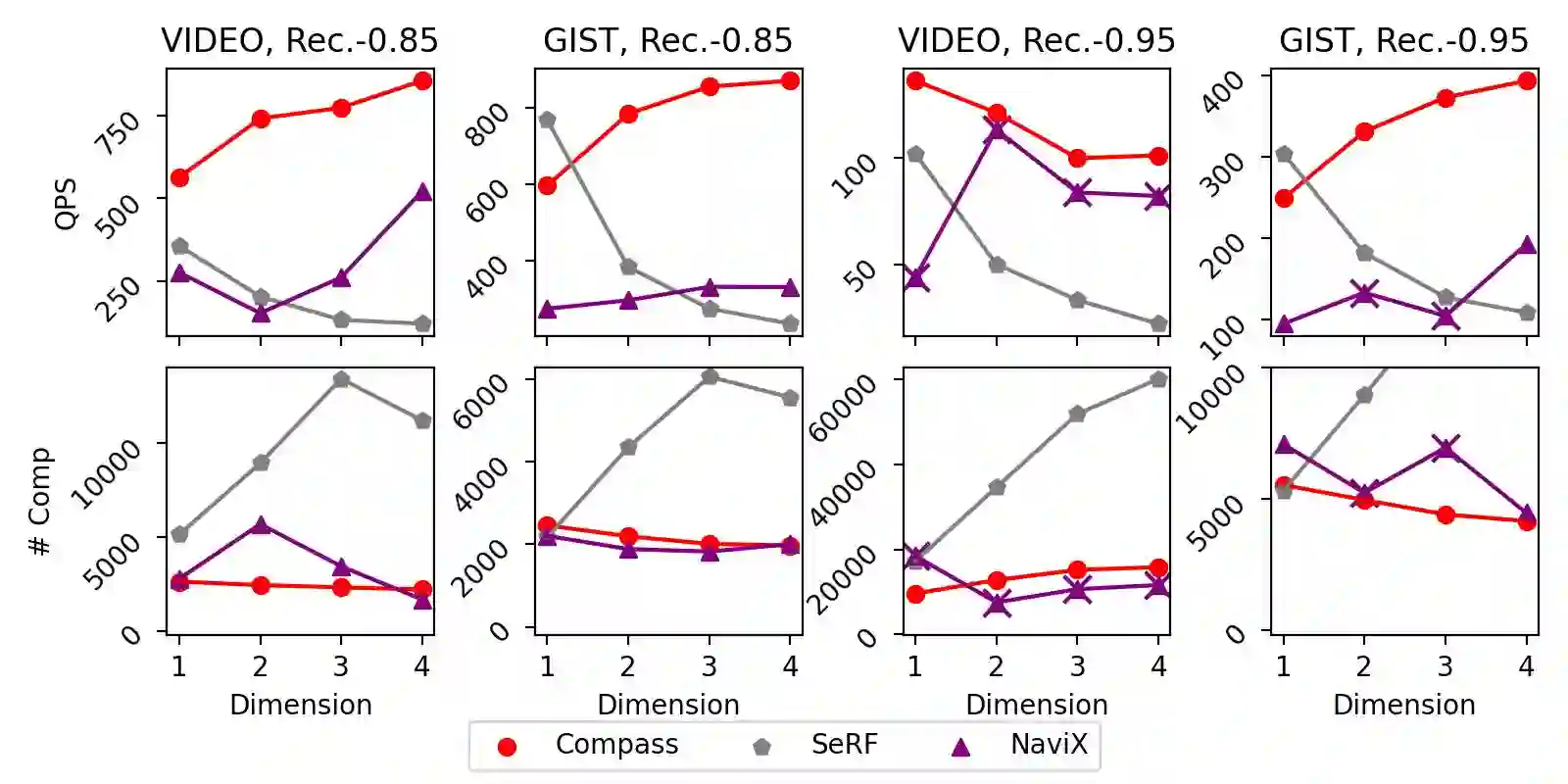
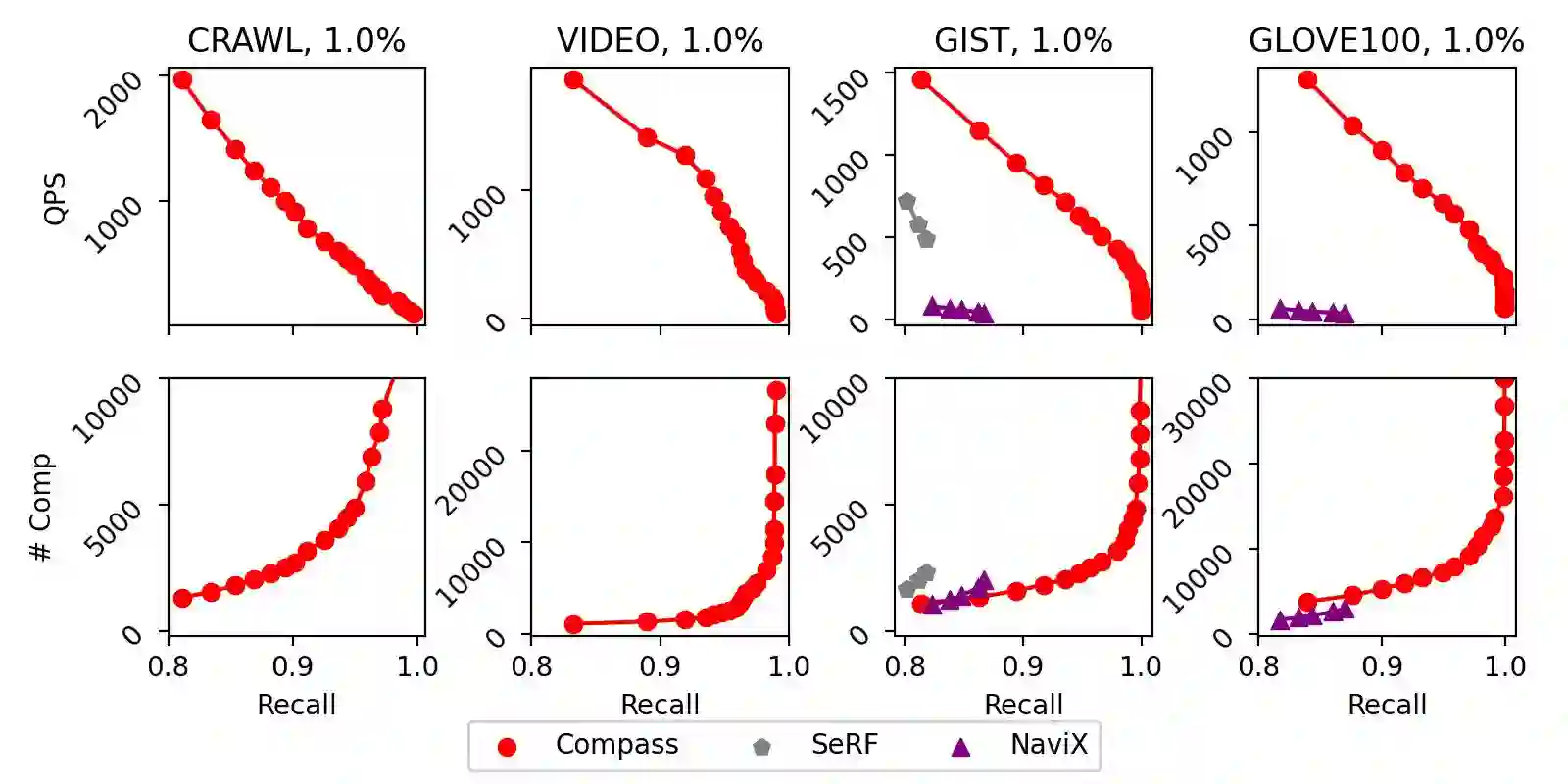
The increasing prevalence of hybrid vector and relational data necessitates efficient, general support for queries that combine high-dimensional vector search with complex relational filtering. However, existing filtered search solutions are fundamentally limited by specialized indices, which restrict arbitrary filtering and hinder integration with general-purpose DBMSs. This work introduces \textsc{Compass}, a unified framework that enables general filtered search across vector and structured data without relying on new index designs. Compass leverages established index structures -- such as HNSW and IVF for vector attributes, and B+-trees for relational attributes -- implementing a principled cooperative query execution strategy that coordinates candidate generation and predicate evaluation across modalities. Uniquely, Compass maintains generality by allowing arbitrary conjunctions, disjunctions, and range predicates, while ensuring robustness even with highly-selective or multi-attribute filters. Comprehensive empirical evaluations demonstrate that Compass consistently outperforms NaviX, the only existing performant general framework, across diverse hybrid query workloads. It also matches the query throughput of specialized single-attribute indices in their favorite settings with only a single attribute involved, all while maintaining full generality and DBMS compatibility. Overall, Compass offers a practical and robust solution for achieving truly general filtered search in vector database systems.
翻译:随着混合向量与关系数据的日益普及,亟需高效、通用地支持将高维向量搜索与复杂关系过滤相结合的查询。然而,现有过滤搜索方案受限于专用索引设计,无法支持任意过滤条件,且难以与通用数据库管理系统集成。本文提出\\textsc{Compass},一个不依赖新型索引的统一框架,实现跨向量与结构化数据的通用过滤搜索。Compass利用成熟的索引结构——如用于向量属性的HNSW与IVF,以及用于关系属性的B+树——通过一种原则性的协同查询执行策略,协调跨模态的候选生成与谓词评估。其独特之处在于,通过支持任意合取、析取与范围谓词保持通用性,即使面对高选择性或多属性过滤时仍确保鲁棒性。综合实验评估表明,在不同混合查询负载下,Compass始终优于现有唯一高性能通用框架NaviX。在仅涉及单属性的理想场景中,其查询吞吐量可与专用单属性索引相媲美,同时保持完全通用性与数据库兼容性。总体而言,Compass为向量数据库系统实现真正通用的过滤搜索提供了实用且鲁棒的解决方案。