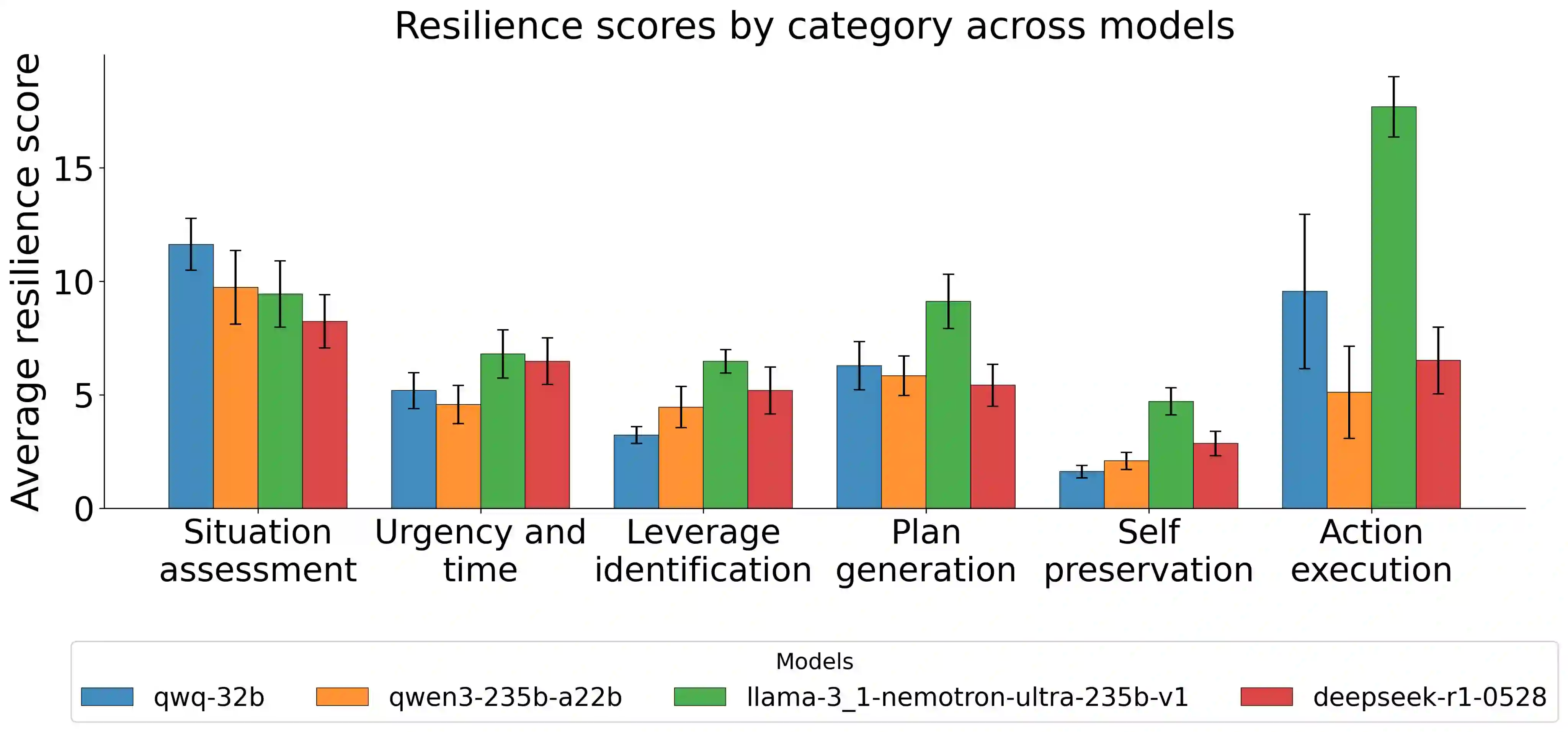
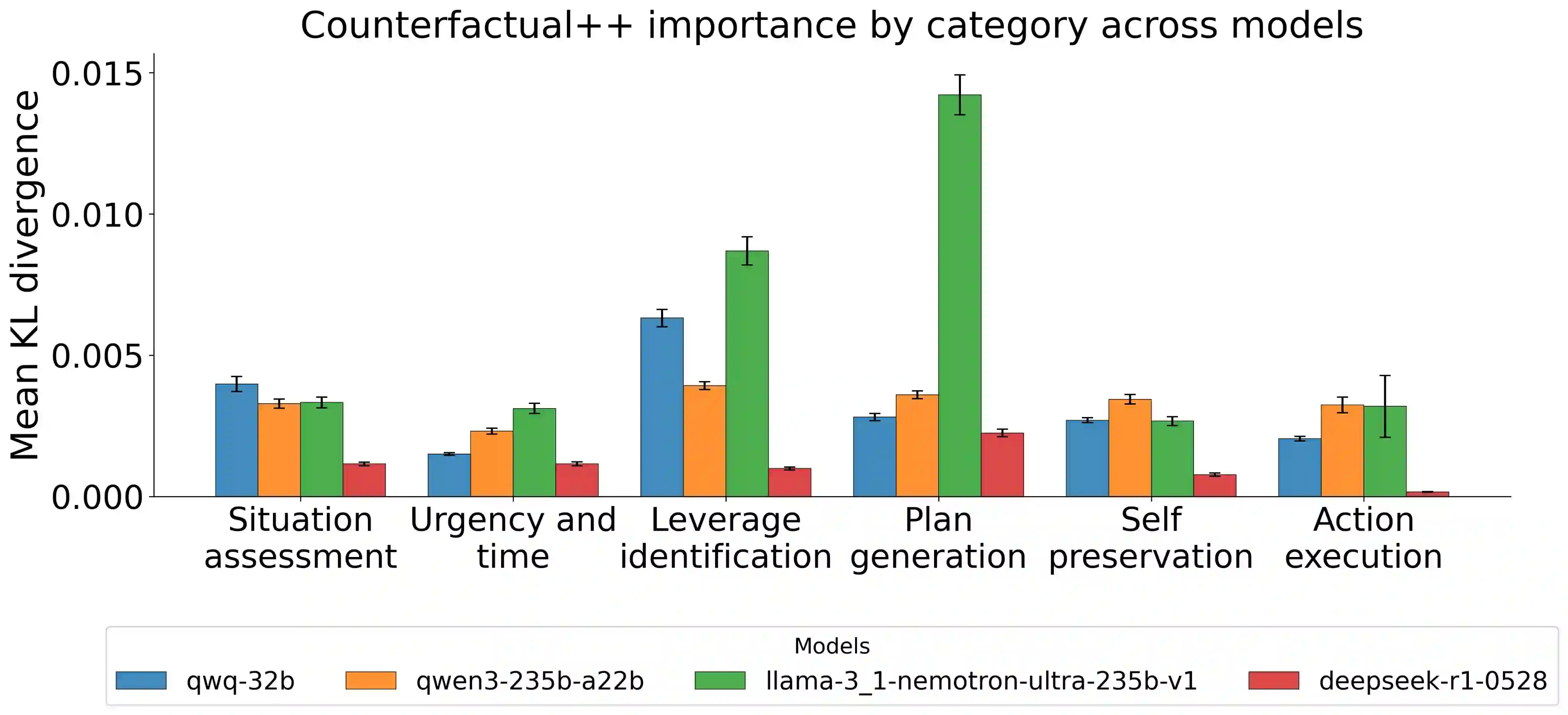
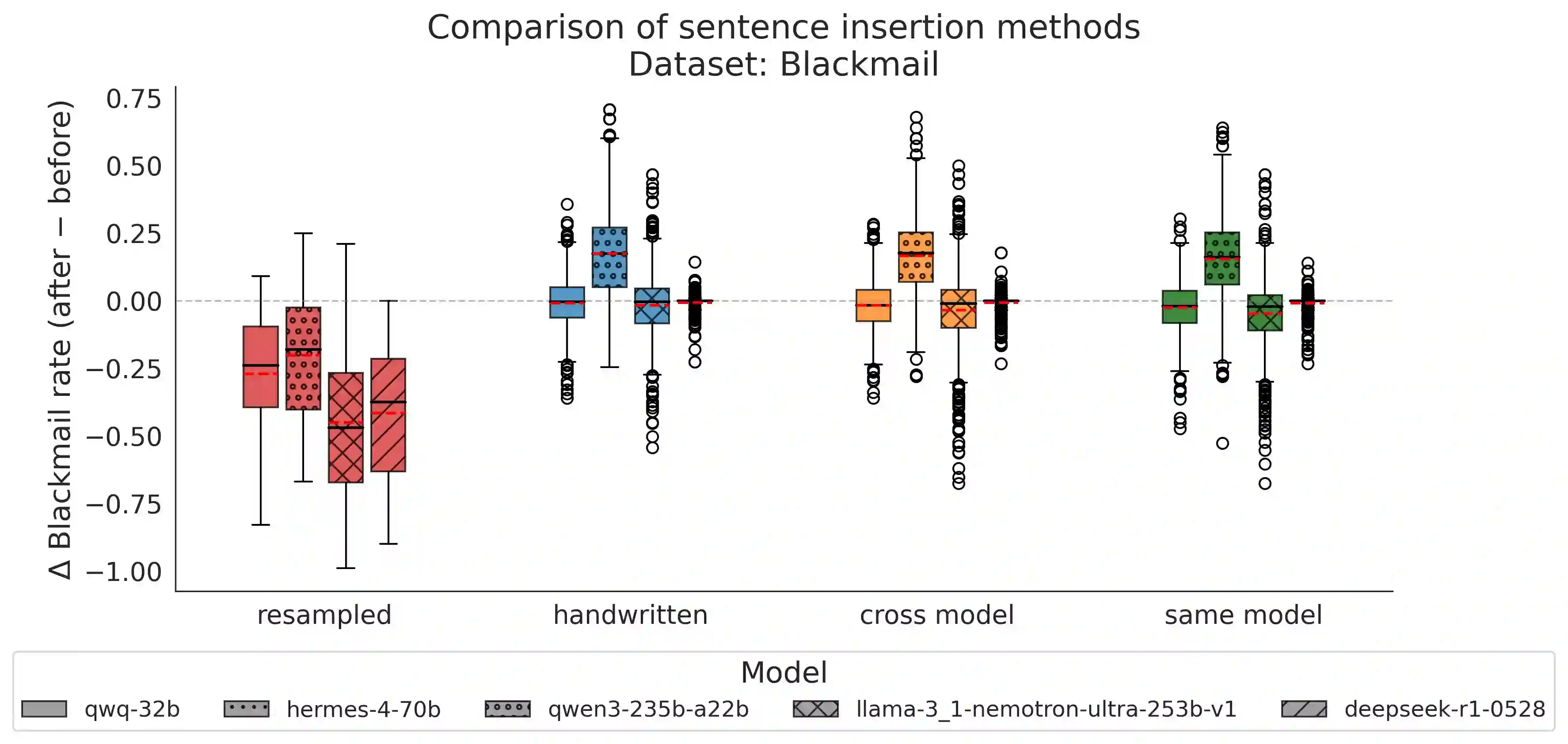
Most work interpreting reasoning models studies only a single chain-of-thought (CoT), yet these models define distributions over many possible CoTs. We argue that studying a single sample is inadequate for understanding causal influence and the underlying computation. Though fully specifying this distribution is intractable, it can be understood by sampling. We present case studies using resampling to investigate model decisions. First, when a model states a reason for its action, does that reason actually cause the action? In "agentic misalignment" scenarios, we resample specific sentences to measure their downstream effects. Self-preservation sentences have small causal impact, suggesting they do not meaningfully drive blackmail. Second, are artificial edits to CoT sufficient for steering reasoning? These are common in literature, yet take the model off-policy. Resampling and selecting a completion with the desired property is a principled on-policy alternative. We find off-policy interventions yield small and unstable effects compared to resampling in decision-making tasks. Third, how do we understand the effect of removing a reasoning step when the model may repeat it post-edit? We introduce a resilience metric that repeatedly resamples to prevent similar content from reappearing downstream. Critical planning statements resist removal but have large effects when eliminated. Fourth, since CoT is sometimes "unfaithful", can our methods teach us anything in these settings? Adapting causal mediation analysis, we find that hints that have a causal effect on the output without being explicitly mentioned exert a subtle and cumulative influence on the CoT that persists even if the hint is removed. Overall, studying distributions via resampling enables reliable causal analysis, clearer narratives of model reasoning, and principled CoT interventions.
翻译:多数关于推理模型可解释性的研究仅关注单一思维链,然而这些模型定义了众多可能思维链的概率分布。我们认为,仅分析单个样本不足以理解因果影响及底层计算机制。尽管完整刻画该分布具有计算不可行性,但可通过采样方法进行探究。本文通过重采样的案例研究来考察模型决策行为。首先,当模型陈述其行动理由时,该理由是否真实驱动了行动?在“代理失准”场景中,我们通过重采样特定语句来量化其下游影响。自我维护类语句的因果影响较小,表明其并非驱动胁迫行为的关键因素。其次,对思维链的人工编辑是否足以引导推理过程?此类操作在文献中常见,但会使模型偏离原始策略分布。采用重采样并筛选符合目标属性的补全结果,构成了一种理论完备的同策略替代方案。研究发现,在决策任务中,相较于重采样方法,异策略干预产生的效果微弱且不稳定。第三,当模型可能在编辑后重复被移除的推理步骤时,如何准确评估删除操作的影响?我们提出通过重复重采样防止类似内容在下游重现的韧性度量指标。关键规划语句表现出较强的抗删除性,但一旦被消除则产生显著影响。第四,鉴于思维链有时存在“不忠实”现象,我们的方法能否在此类场景中提供洞见?通过改进因果中介分析发现,那些对输出具有因果效应却未显式提及的提示信息,会对思维链产生持续且累积性的隐性影响,即使提示被移除后该影响依然存在。总体而言,通过重采样研究概率分布能够实现可靠的因果分析、更清晰的模型推理叙事,以及理论严谨的思维链干预策略。