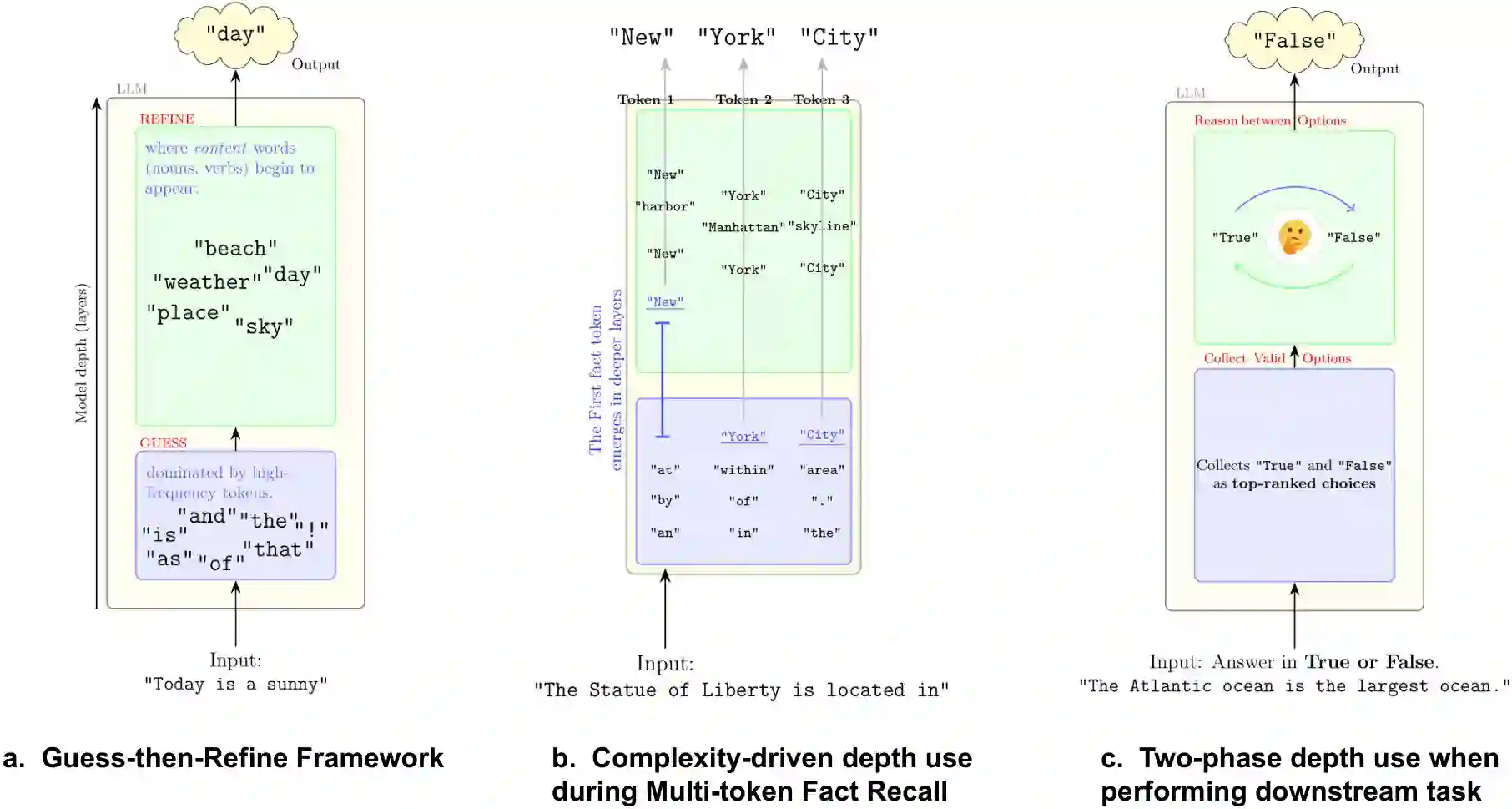
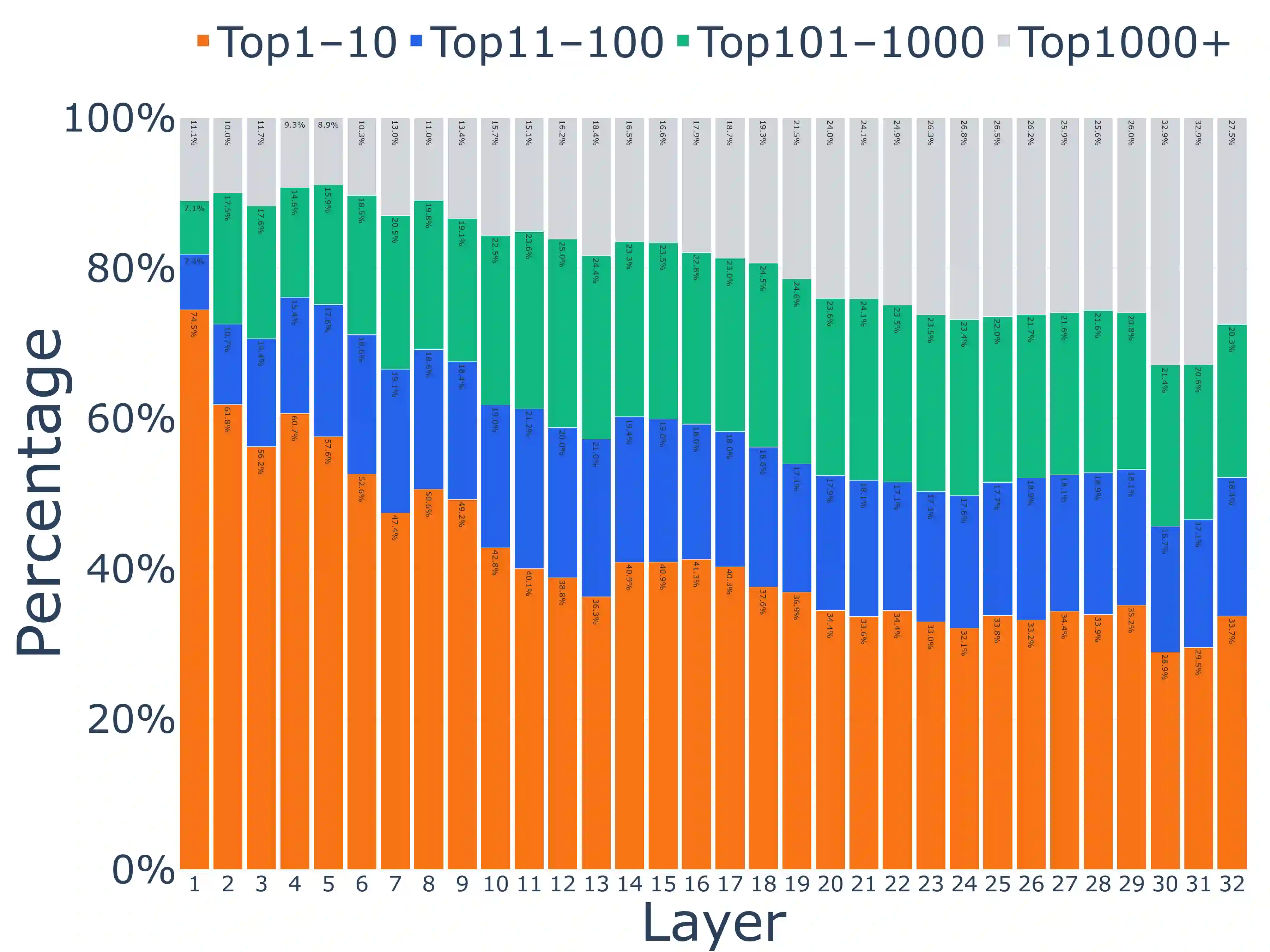
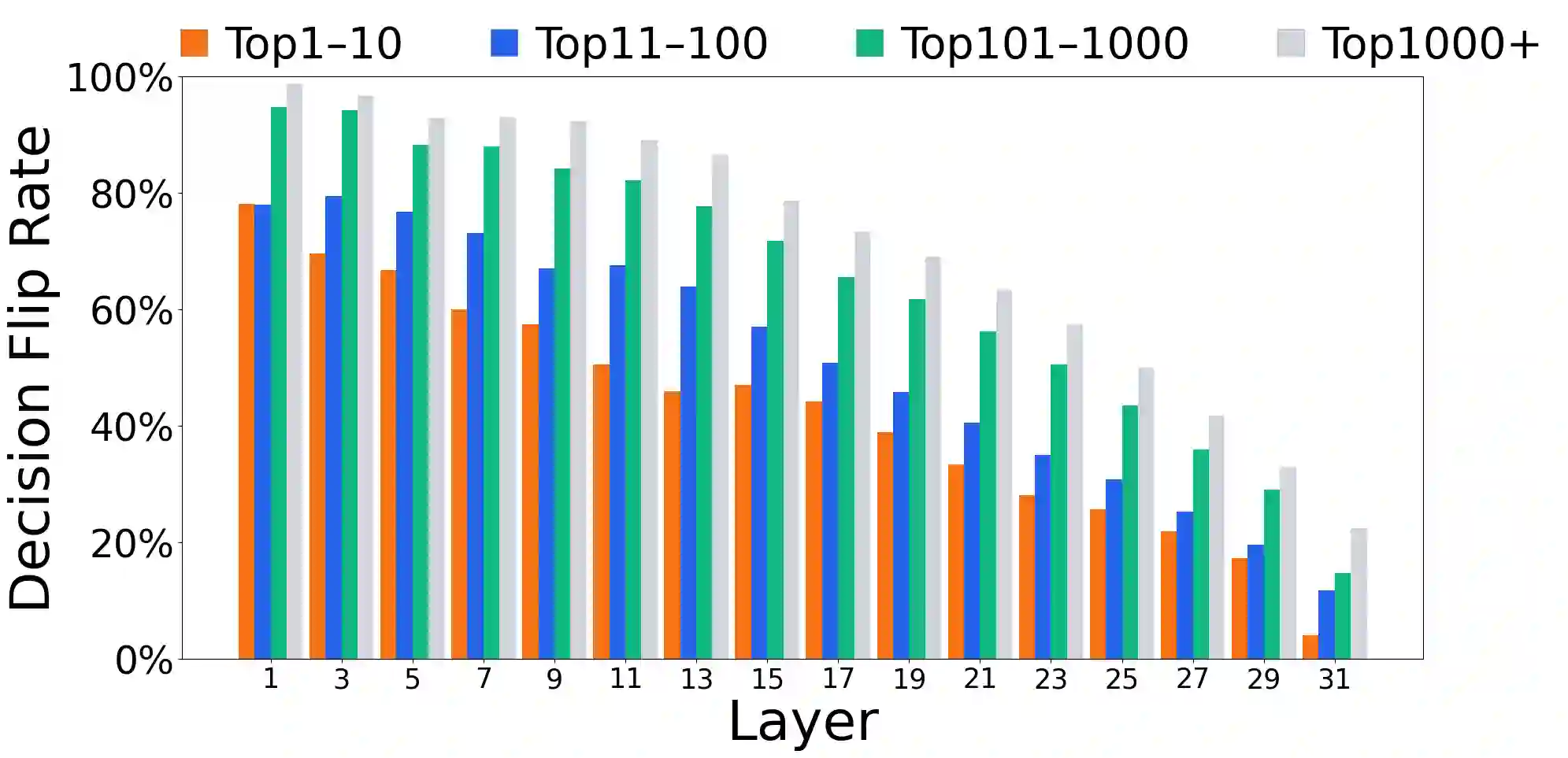
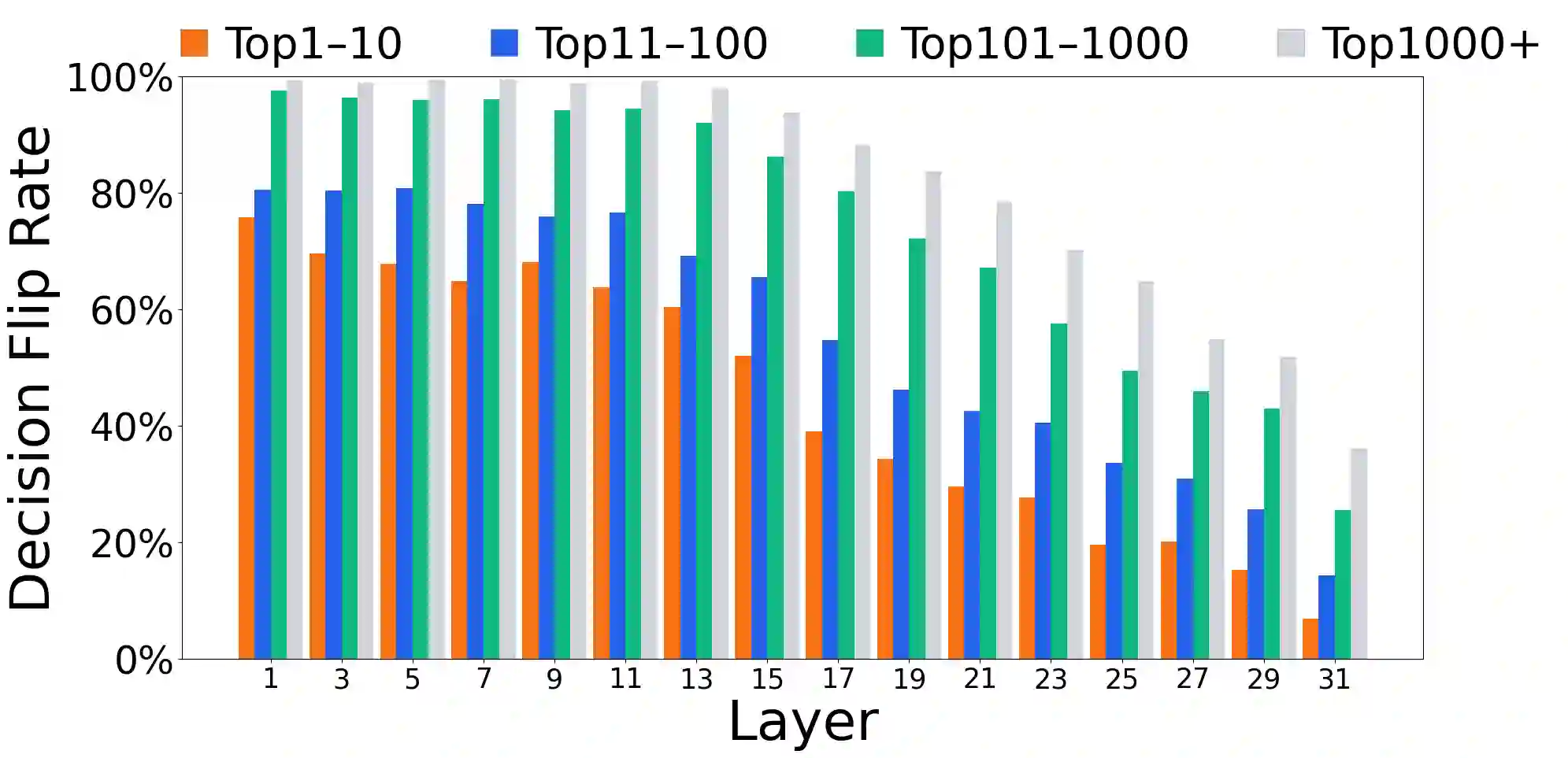
Growing evidence suggests that large language models do not use their depth uniformly, yet we still lack a fine-grained understanding of their layer-wise prediction dynamics. In this paper, we trace the intermediate representations of several open-weight models during inference and reveal a structured and nuanced use of depth. Specifically, we propose a "Guess-then-Refine" framework that explains how LLMs internally structure their computations to make predictions. We first show that the top-ranked predictions in early LLM layers are composed primarily of high-frequency tokens, which act as statistical guesses proposed by the model early on due to the lack of appropriate contextual information. As contextual information develops deeper into the model, these initial guesses get refined into contextually appropriate tokens. Even high-frequency token predictions from early layers get refined >70% of the time, indicating that correct token prediction is not "one-and-done". We then go beyond frequency-based prediction to examine the dynamic usage of layer depth across three case studies. (i) Part-of-speech analysis shows that function words are, on average, the earliest to be predicted correctly. (ii) Fact recall task analysis shows that, in a multi-token answer, the first token requires more computational depth than the rest. (iii) Multiple-choice task analysis shows that the model identifies the format of the response within the first half of the layers, but finalizes its response only toward the end. Together, our results provide a detailed view of depth usage in LLMs, shedding light on the layer-by-layer computations that underlie successful predictions and providing insights for future works to improve computational efficiency in transformer-based models.
翻译:越来越多的证据表明,大型语言模型并非均匀地利用其深度,然而我们仍缺乏对其逐层预测动态的细粒度理解。本文追踪了多个开源权重模型在推理过程中的中间表示,揭示了其深度使用具有结构化和细致化的特征。具体而言,我们提出了一个"猜测-优化"框架,用以解释LLM如何内部组织其计算以进行预测。我们首先证明,LLM早期层中的高排名预测主要由高频词元构成,这些词元由于缺乏适当的上下文信息而在模型早期作为统计猜测被提出。随着上下文信息在模型更深层中逐渐发展,这些初始猜测会被优化为符合上下文的词元。即使是早期层的高频词元预测,其优化比例也超过70%,这表明正确的词元预测并非"一蹴而就"。随后,我们超越基于频率的预测分析,通过三个案例研究探讨了层深度的动态使用情况。(i) 词性分析表明,功能词平均而言最早被正确预测。(ii) 事实回忆任务分析显示,在多词元答案中,第一个词元需要比其余部分更多的计算深度。(iii) 多项选择任务分析表明,模型在前半部分层中识别出回答的格式,但仅在接近末尾时才最终确定其回答。综合来看,我们的结果为LLM中的深度使用提供了详细视图,揭示了支撑成功预测的逐层计算过程,并为未来工作提升基于Transformer模型的计算效率提供了见解。