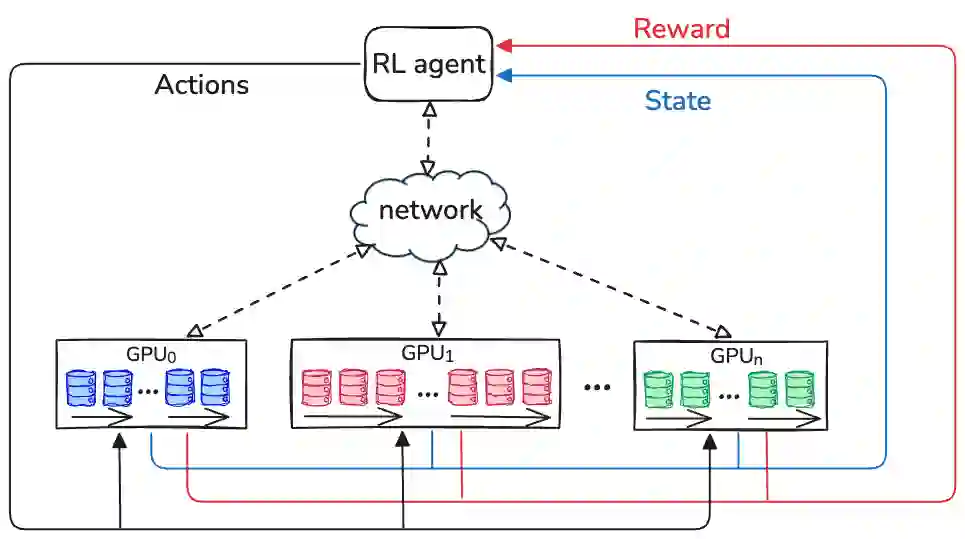
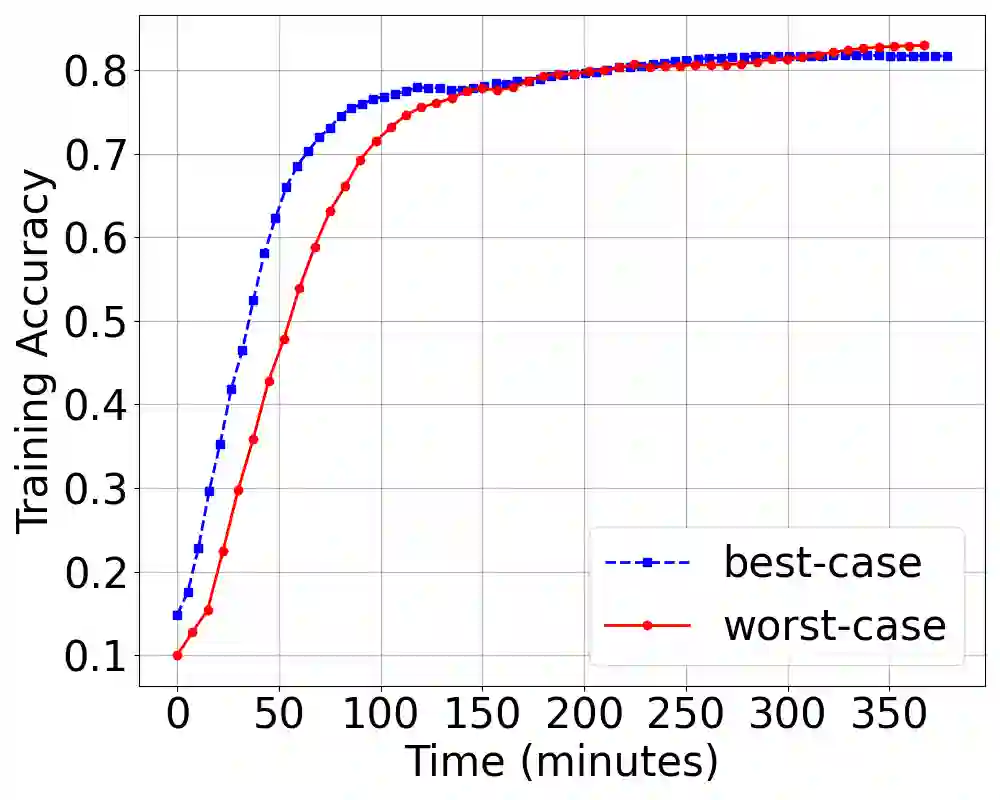
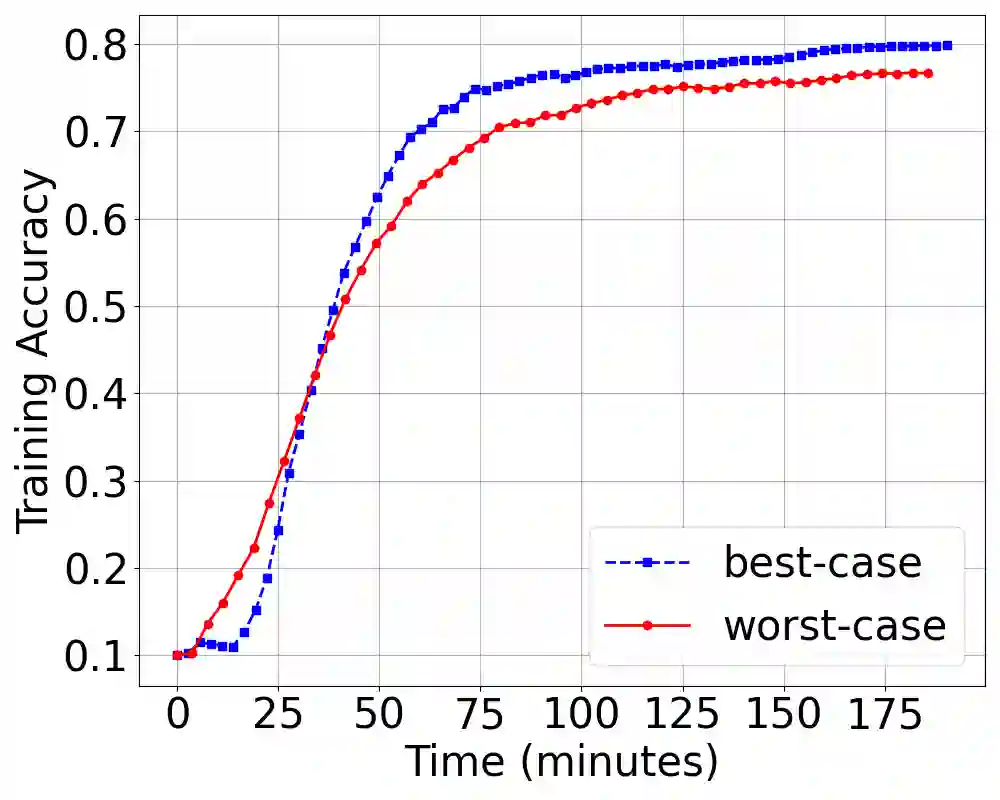
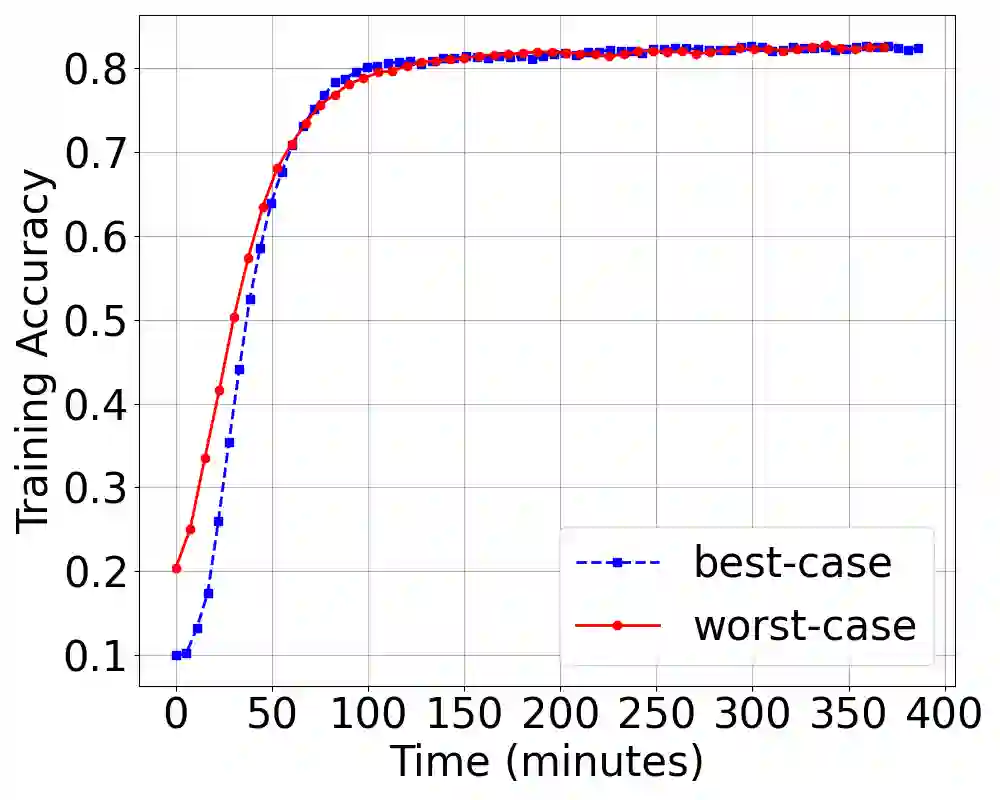
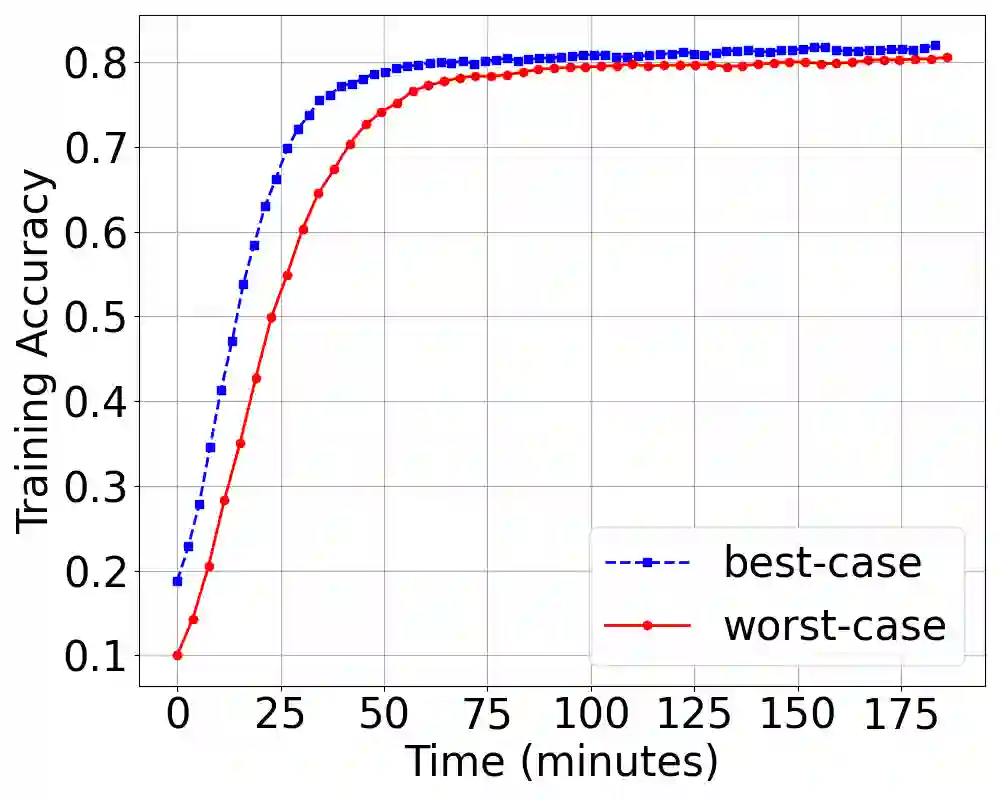
Existing batch size selection approaches in dis- tributed machine learning rely on static allocation or simplistic heuristics that fail to adapt to heterogeneous, dynamic computing environments. We present DYNAMIX, a reinforcement learning framework that formulates batch size optimization as a sequen- tial decision-making problem using Proximal Policy Optimiza- tion (PPO). Our approach employs a multi-dimensional state representation encompassing network-level metrics, system-level resource utilization, and training statistical efficiency indicators to enable informed decision-making across diverse computational resources. Our approach eliminates the need for explicit system modeling while integrating seamlessly with existing distributed training frameworks. Through evaluations across diverse work- loads, hardware configurations, and network conditions, DY- NAMIX achieves up to 6.3% improvement in the final model accuracy and 46% reduction in the total training time. Our scalability experiments demonstrate that DYNAMIX maintains the best performance as cluster size increases to 32 nodes, while policy transfer experiments show that learned policies generalize effectively across related model architectures.
翻译:现有的分布式机器学习批量大小选择方法依赖于静态分配或简单的启发式策略,这些方法无法适应异构、动态的计算环境。本文提出DYNAMIX,一个基于强化学习的框架,该框架使用近端策略优化(PPO)将批量大小优化问题建模为序列决策问题。我们的方法采用多维状态表示,涵盖网络级指标、系统级资源利用率以及训练统计效率指标,从而能够在多样化的计算资源上实现基于信息的决策。该方法无需显式系统建模,并可无缝集成到现有的分布式训练框架中。通过在多样化工作负载、硬件配置和网络条件下的评估,DYNAMIX实现了最终模型精度最高提升6.3%,总训练时间减少46%。我们的可扩展性实验表明,当集群规模扩展至32个节点时,DYNAMIX仍能保持最佳性能;策略迁移实验则表明,学习到的策略能够有效泛化至相关的模型架构。