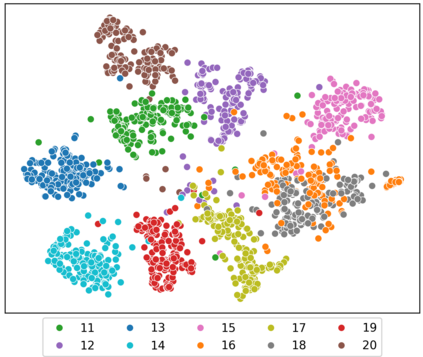
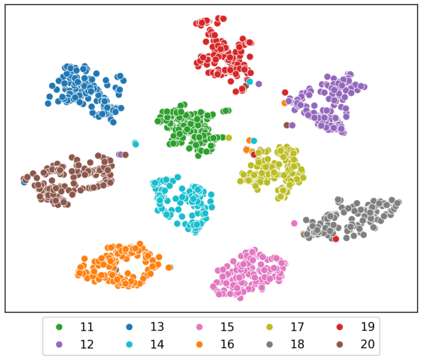
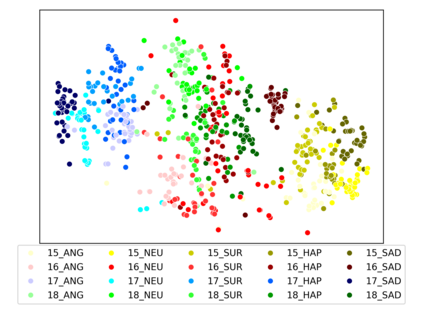
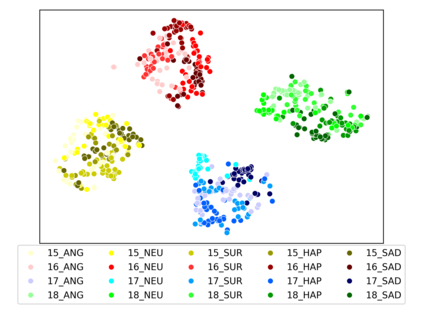
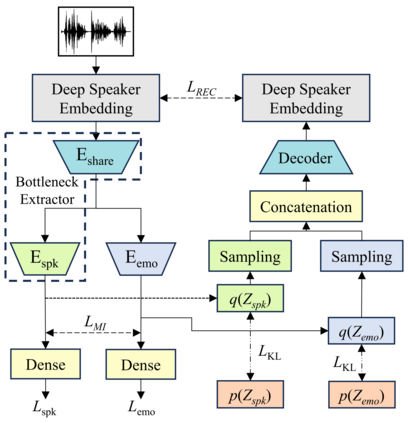
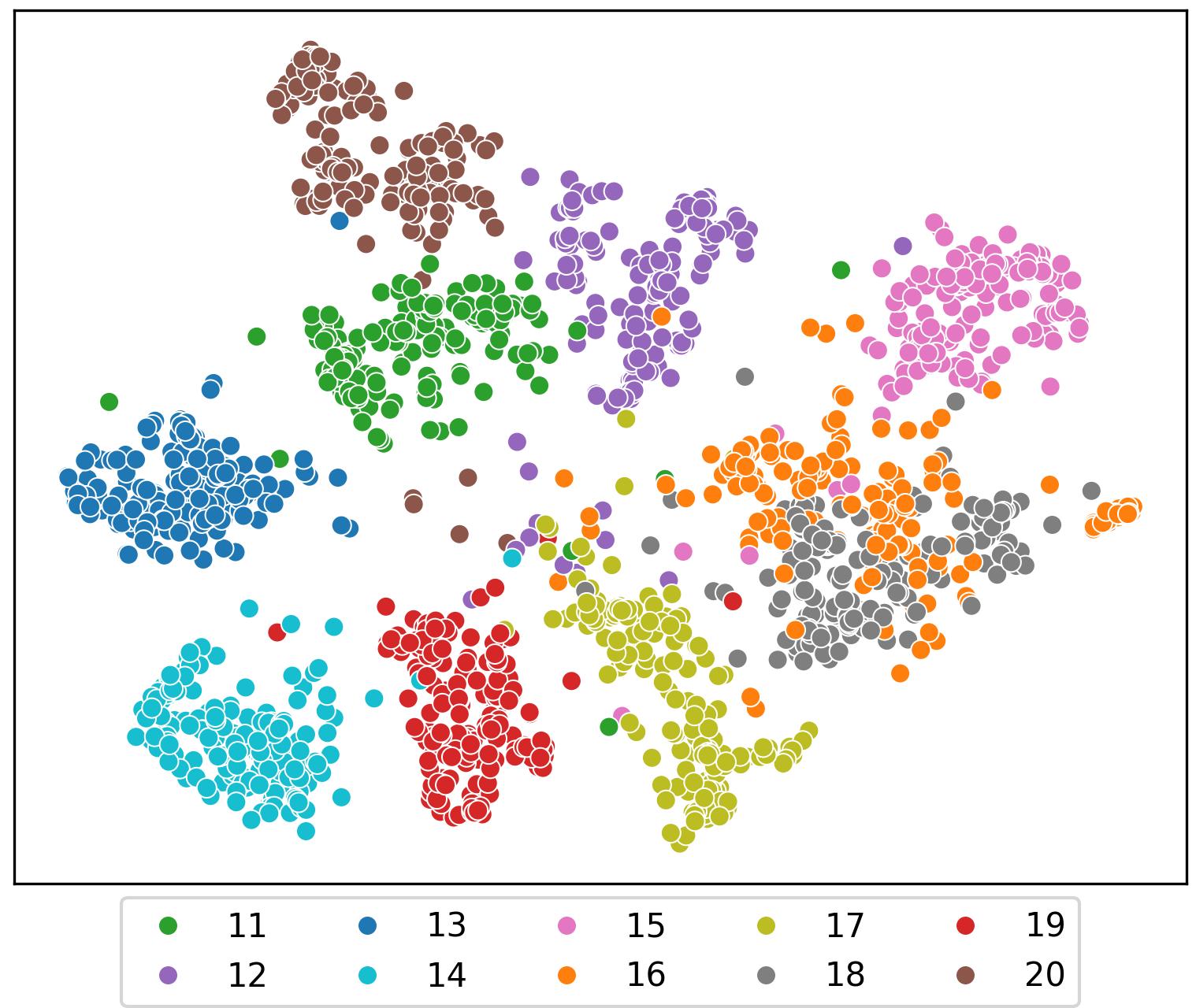
Speaker clustering is the task of identifying the unique speakers in a set of audio recordings (each belonging to exactly one speaker) without knowing who and how many speakers are present in the entire data, which is essential for speaker diarization processes. Recently, off-the-shelf deep speaker embedding models have been leveraged to capture speaker characteristics. However, speeches containing emotional expressions pose significant challenges, often affecting the accuracy of speaker embeddings and leading to a decline in speaker clustering performance. To tackle this problem, we propose DTG-VAE, a novel disentanglement method that enhances clustering within a Variational Autoencoder (VAE) framework. This study reveals a direct link between emotional states and the effectiveness of deep speaker embeddings. As demonstrated in our experiments, DTG-VAE extracts more robust speaker embeddings and significantly enhances speaker clustering performance.
翻译:暂无翻译