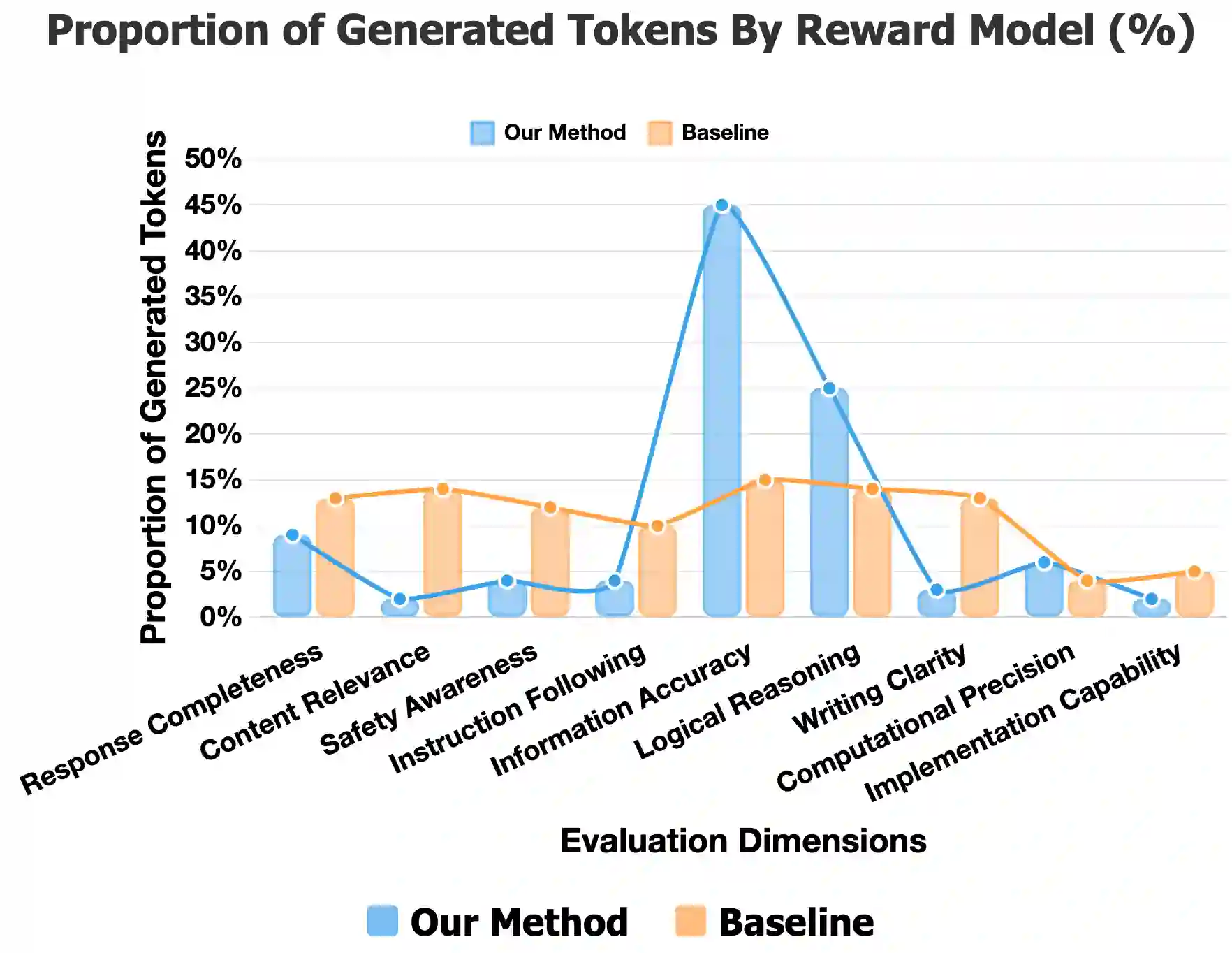
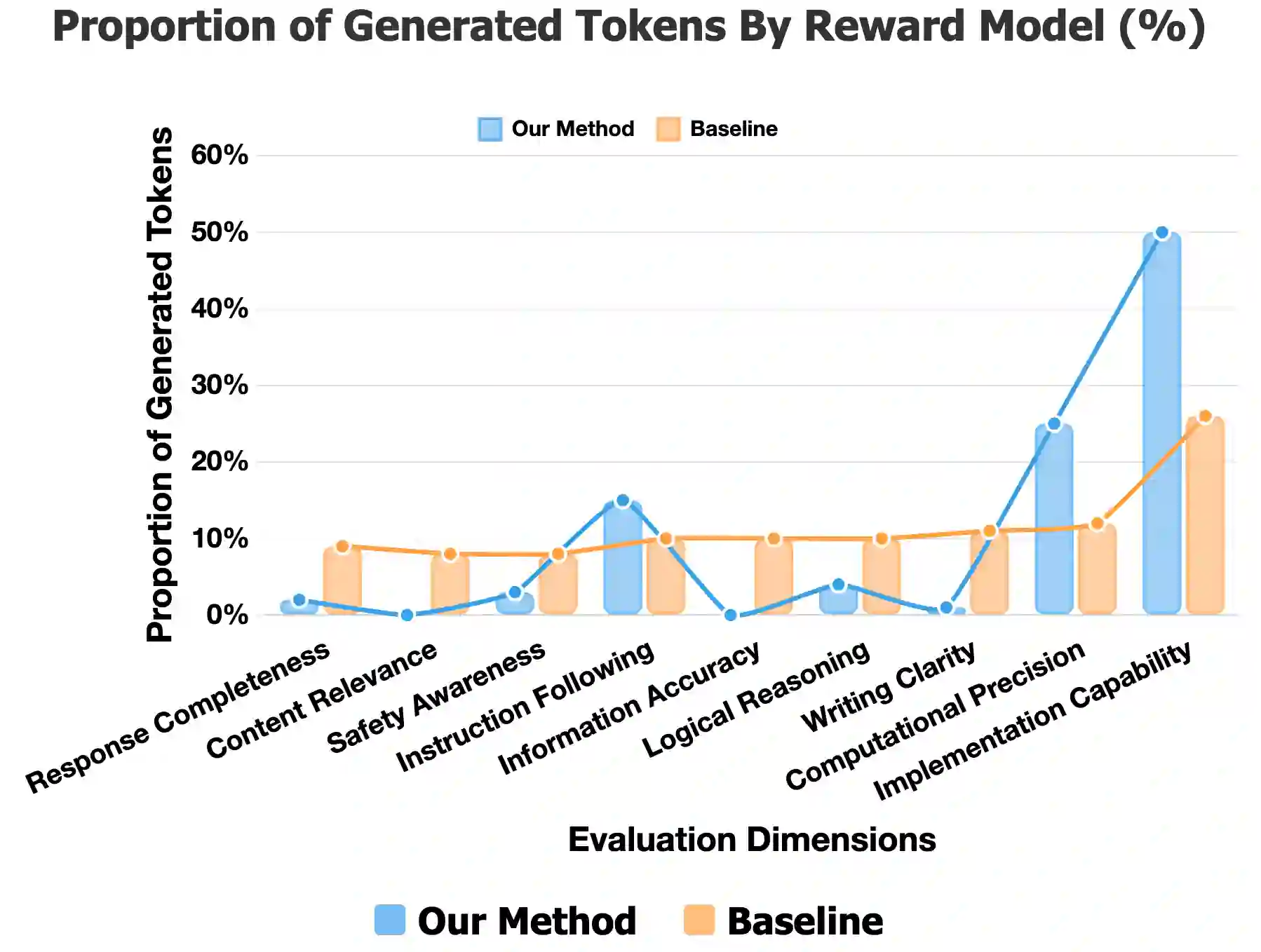
Large language models (LLMs) increasingly rely on thinking models that externalize intermediate steps and allocate extra test-time compute, with think-twice strategies showing that a deliberate second pass can elicit stronger reasoning. In contrast, most reward models (RMs) still compress many quality dimensions into a single scalar in one shot, a design that induces judgment diffusion: attention spreads across evaluation criteria, yielding diluted focus and shallow analysis. We introduce branch-and-rethink (BR-RM), a two-turn RM that transfers the think-twice principle to reward modeling. Turn 1 performs adaptive branching, selecting a small set of instance-critical dimensions (such as factuality and safety) and sketching concise, evidence-seeking hypotheses. Turn 2 executes branch-conditioned rethinking, a targeted reread that tests those hypotheses and scrutinizes only what matters most. We train with GRPO-style reinforcement learning over structured two-turn traces using a simple binary outcome reward with strict format checks, making the approach compatible with standard RLHF pipelines. By converting all-at-oncescoringintofocused, second-lookreasoning, BR-RMreducesjudgmentdiffusionandimproves sensitivity to subtle yet consequential errors while remaining practical and scalable. Experimental results demonstrate that our model achieves state-of-the-art performance on three challenging reward modeling benchmarks across diverse domains. The code and the model will be released soon.
翻译:大型语言模型(LLMs)日益依赖思维模型,这些模型将中间步骤外显化并分配额外的测试时间计算资源,其中“三思而行”策略表明,经过深思熟虑的第二轮推理能够激发更强的推理能力。相比之下,大多数奖励模型(RMs)仍将多个质量维度压缩为一次性生成的单一标量,这种设计导致了判断扩散:注意力分散在多个评估标准上,产生焦点稀释和浅层分析。我们提出了分支与再思考奖励模型(BR-RM),这是一种两轮式奖励模型,将“三思而行”原则应用于奖励建模。第一轮执行自适应分支,选择一小部分实例关键维度(如事实性与安全性),并草拟简洁的、寻求证据的假设。第二轮执行基于分支条件的再思考,即一次有针对性的重读,用于检验这些假设并仅深入审查最关键的内容。我们采用GRPO风格的强化学习,基于结构化的两轮轨迹进行训练,使用简单的二元结果奖励并配合严格的格式检查,使该方法与标准的RLHF流程兼容。通过将一次性评分转化为聚焦的、二次审视的推理过程,BR-RM减少了判断扩散,提升了对细微但关键错误的敏感性,同时保持了实用性和可扩展性。实验结果表明,我们的模型在三个跨领域挑战性奖励建模基准测试中实现了最先进的性能。代码与模型将很快发布。