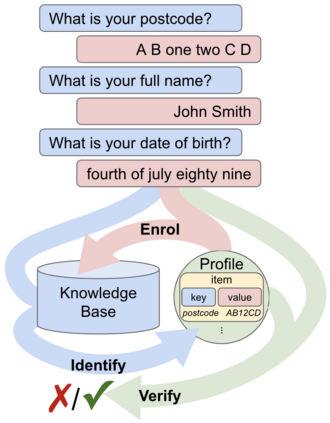
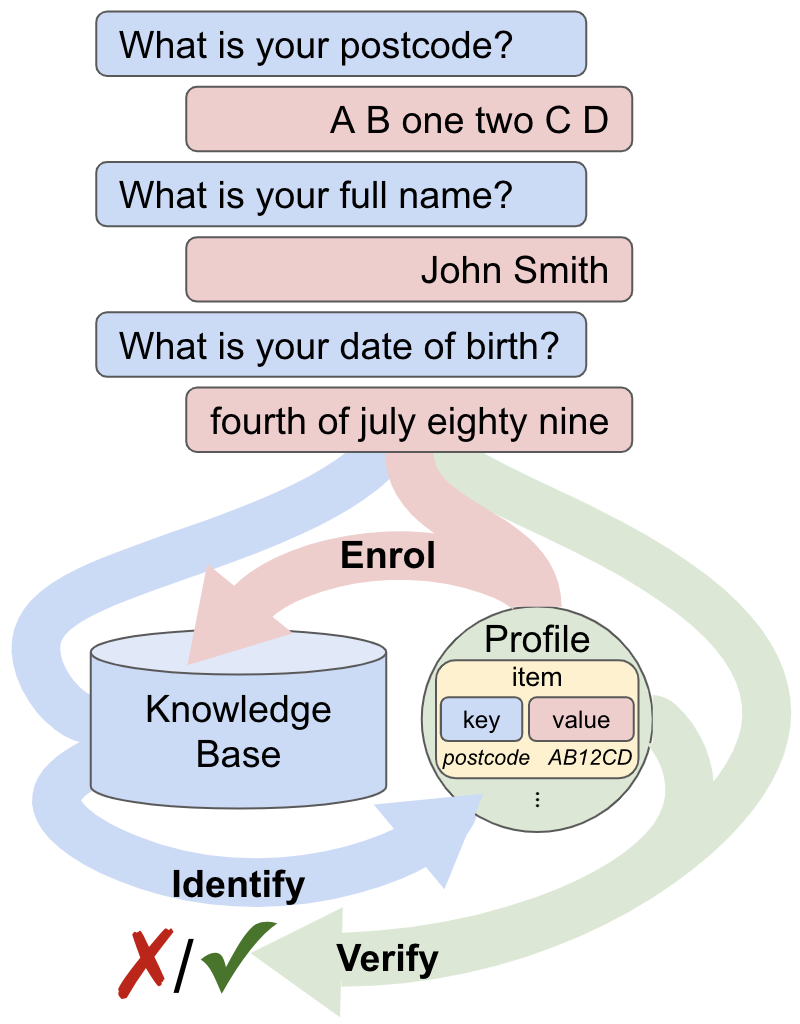
Knowledge-based authentication is crucial for task-oriented spoken dialogue systems that offer personalised and privacy-focused services. Such systems should be able to enrol (E), verify (V), and identify (I) new and recurring users based on their personal information, e.g. postcode, name, and date of birth. In this work, we formalise the three authentication tasks and their evaluation protocols, and we present EVI, a challenging spoken multilingual dataset with 5,506 dialogues in English, Polish, and French. Our proposed models set the first competitive benchmarks, explore the challenges of multilingual natural language processing of spoken dialogue, and set directions for future research.
翻译:以知识为基础的认证对于提供个性化和以隐私为重点的服务的面向任务的口语对话系统至关重要,这种系统应能根据个人信息(如邮政编码、名称和出生日期)注册(E)、核实(V)和识别(I)新用户和经常用户。在这项工作中,我们正式确定三项认证任务及其评价程序,并用英文、波兰文和法文提供具有挑战性的多语种数据集,5 506个多语种对话。我们提出的模式确定了第一个竞争基准,探索口头对话多语言自然语言处理的挑战,并为今后的研究确定方向。