
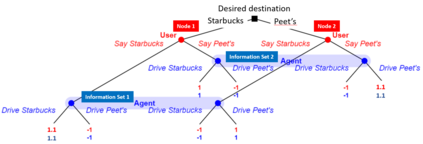
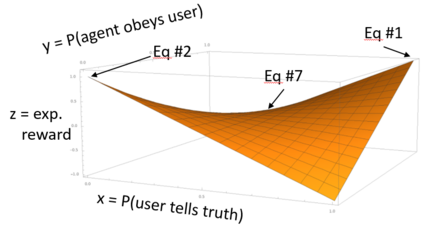
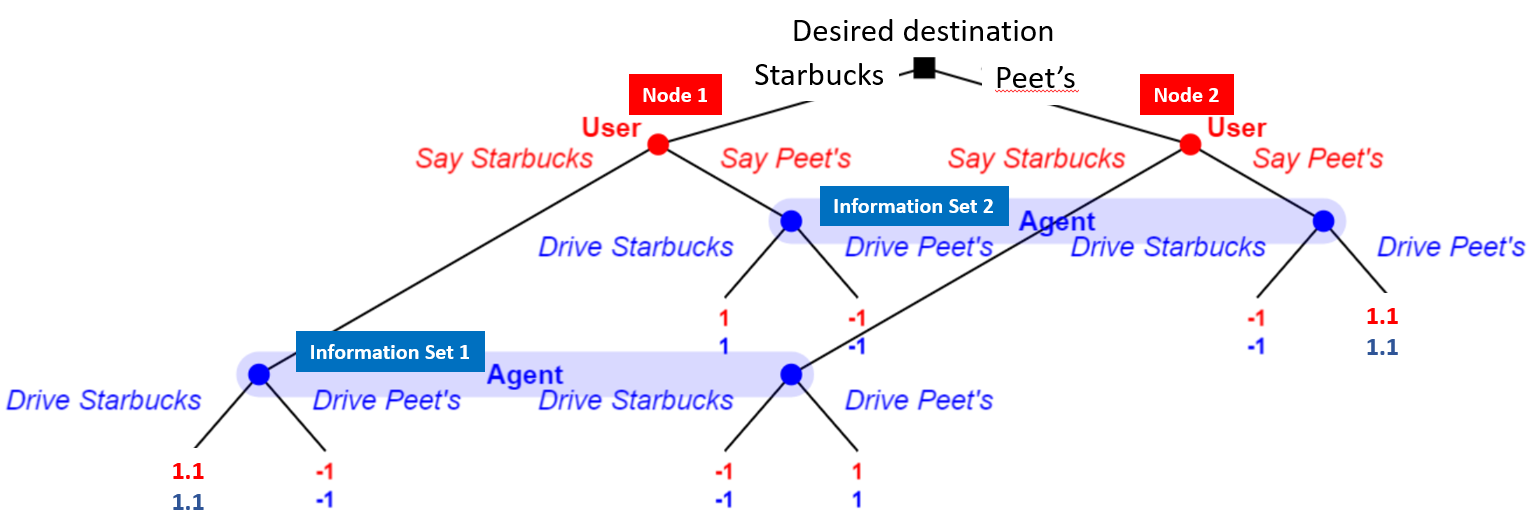
Task-oriented dialog systems are often trained on human/human dialogs, such as collected from Wizard-of-Oz interfaces. However, human/human corpora are frequently too small for supervised training to be effective. This paper investigates two approaches to training agent-bots and user-bots through self-play, in which they autonomously explore an API environment, discovering communication strategies that enable them to solve the task. We give empirical results for both reinforcement learning and game-theoretic equilibrium finding.
翻译:以任务为导向的对话系统往往接受关于人/人对话的培训,例如从奥兹异端界面收集的人类/人对话,然而,人/人体往往太小,无法在监督下开展有效培训,本文调查了通过自我游戏培训代理人-机器人和用户-机器人的两种方法,即他们自主地探索API环境,发现能够解决这项任务的沟通战略。我们为强化学习和游戏理论平衡发现提供了经验性结果。
相关内容
专知会员服务
32+阅读 · 2019年9月19日



相关VIP内容
专知会员服务
32+阅读 · 2019年9月19日
相关资讯
相关论文