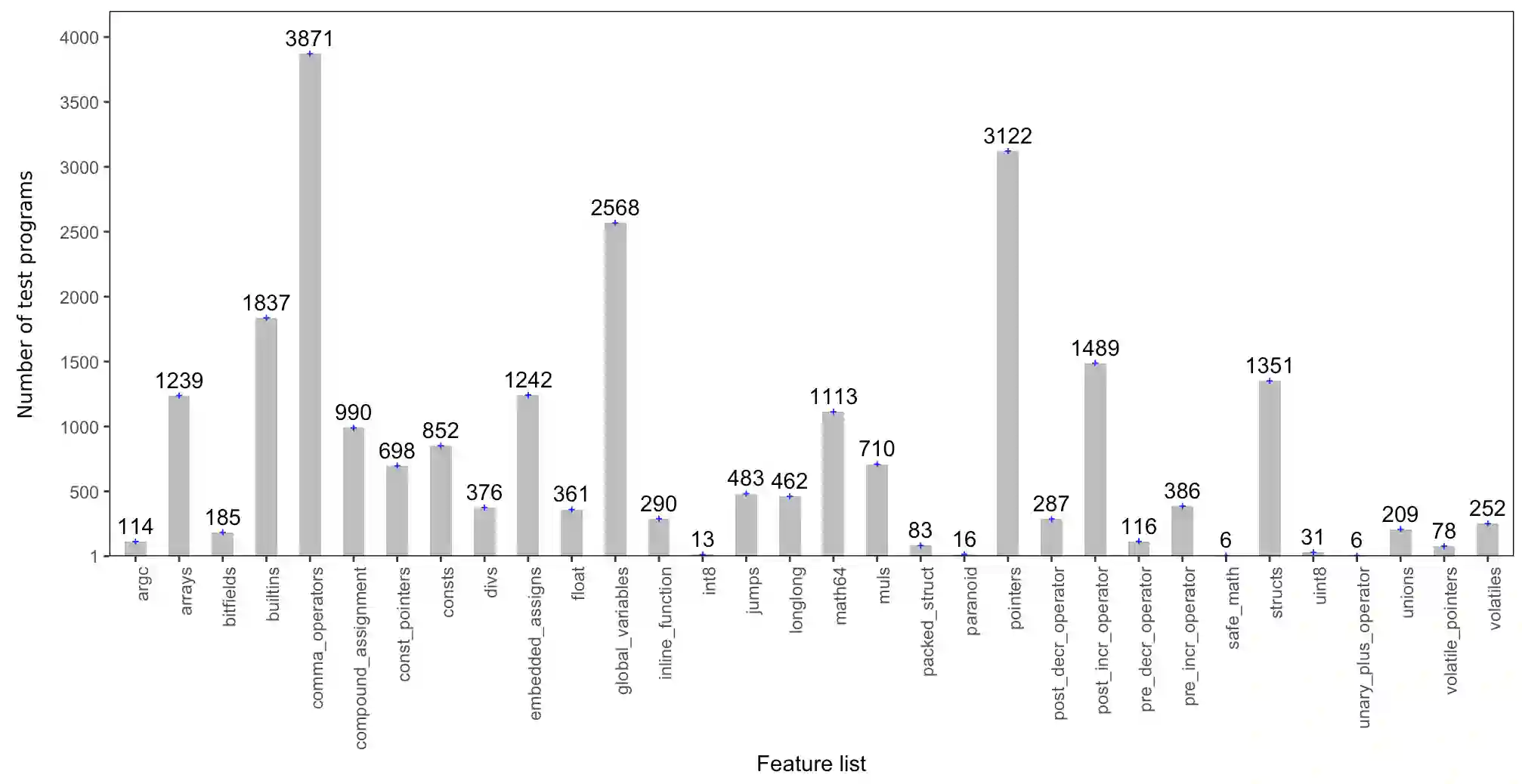
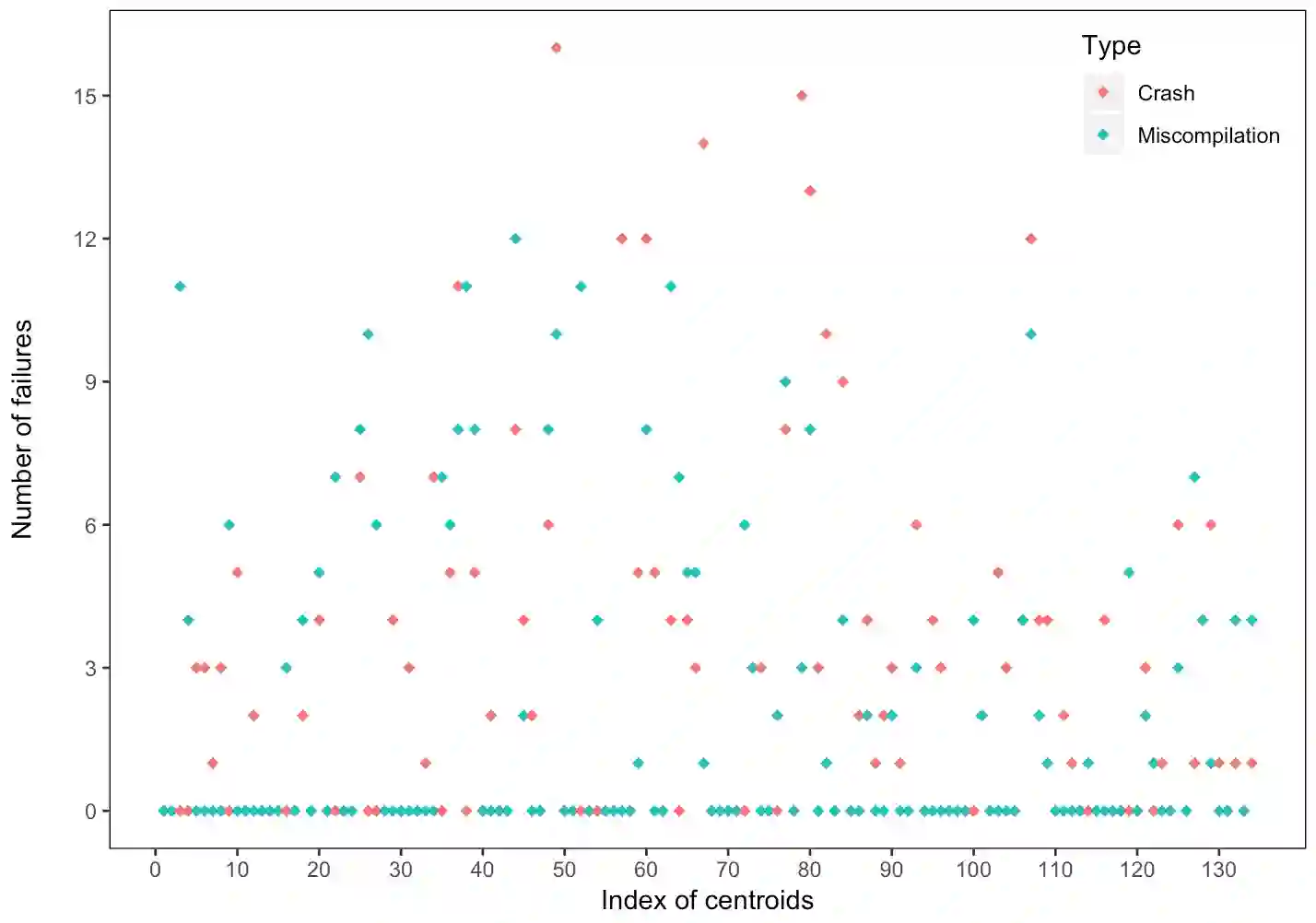
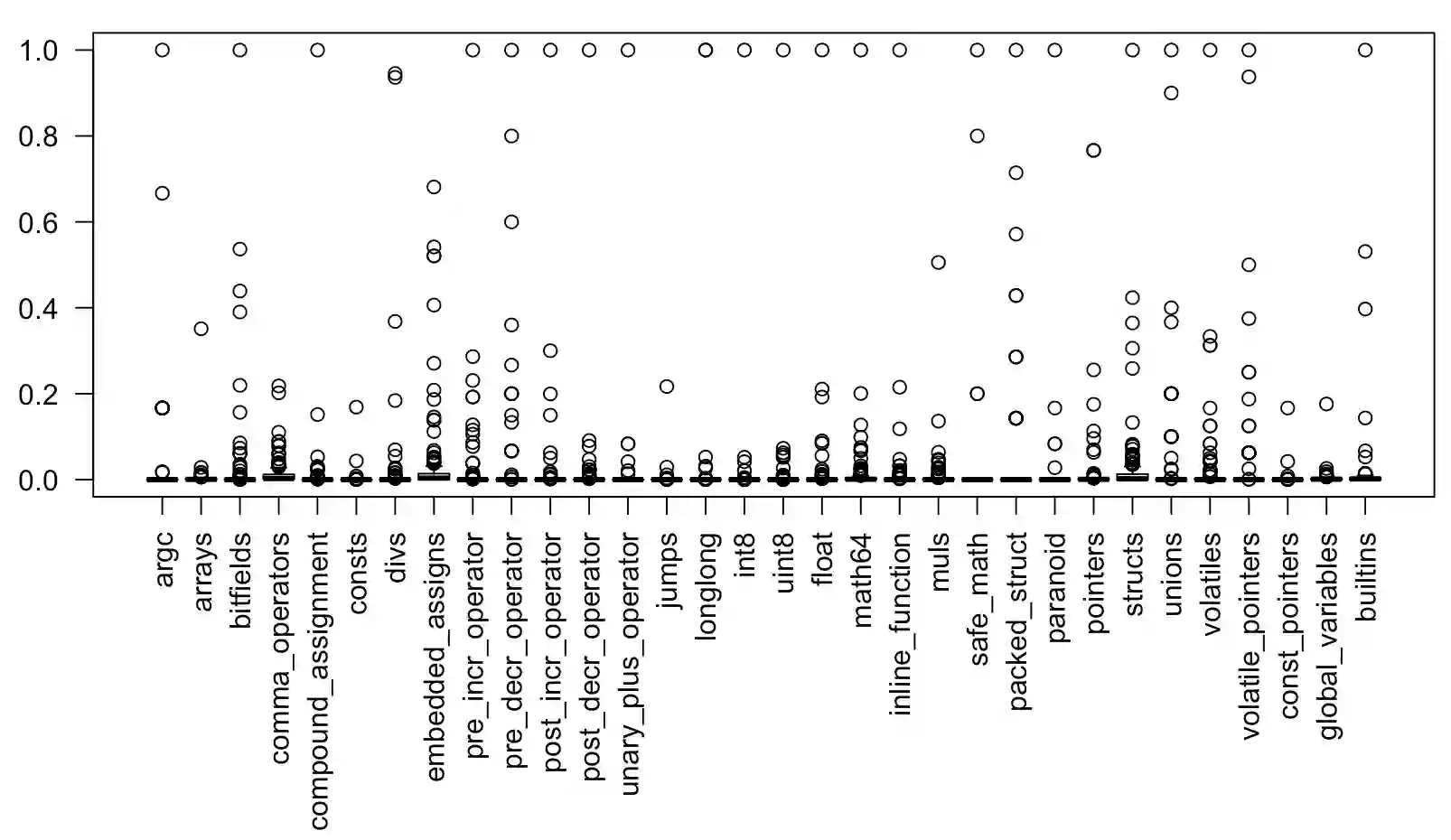
The correctness of compilers is instrumental in the safety and reliability of other software systems, as bugs in compilers can produce executables that do not reflect the intent of programmers. Such errors are difficult to identify and debug. Random test program generators are commonly used in testing compilers, and they have been effective in uncovering bugs. However, the problem of guiding these test generators to produce test programs that are more likely to find bugs remains challenging. In this paper, we use the code snippets in the bug reports to guide the test generation. The main idea of this work is to extract insights from the bug reports about the language features that are more prone to inadequate implementation and using the insights to guide the test generators. We use the GCC C compiler to evaluate the effectiveness of this approach. In particular, we first cluster the test programs in the GCC bugs reports based on their features. We then use the centroids of the clusters to compute configurations for Csmith, a popular test generator for C compilers. We evaluated this approach on eight versions of GCC and found that our approach provides higher coverage and triggers more miscompilation failures than the state-of-the-art test generation techniques for GCC.
翻译:编译器的正确性对于其他软件系统的安全和可靠性至关重要,因为编译器中的错误可以产生不反映程序员意图的可执行文件。 这些错误很难识别和调试。 随机测试程序生成器通常用于测试编译器中,它们有效地发现错误。 然而,指导这些测试生成器制作更可能发现错误的测试程序的问题仍然具有挑战性。 在本文中,我们使用错误报告中的代码片断来指导测试生成。 这项工作的主要想法是从错误报告中提取关于更易于执行的语文特征的洞察力,并利用洞察力来指导测试生成器。 我们使用海合会的C编译器来评估这一方法的有效性。 特别是,我们首先根据它们的特性将海合会的错误报告中的测试程序集中起来。 我们然后使用集中的密件器来为Cmeter( Cnocker)配置一个受欢迎的测试生成器。 我们评估了8个版本的海合会方法,发现我们的方法提供了更高的覆盖范围,并触发了比海合会的测试技术更错误的生成失败。