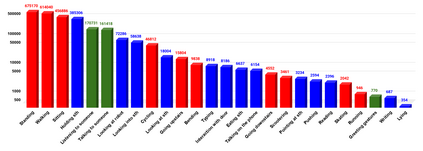
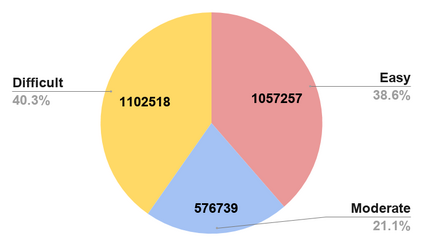
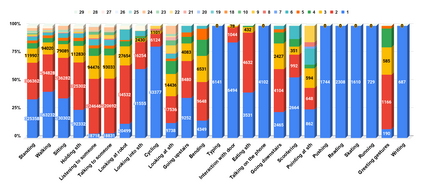
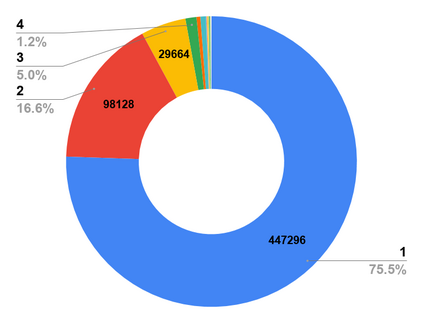
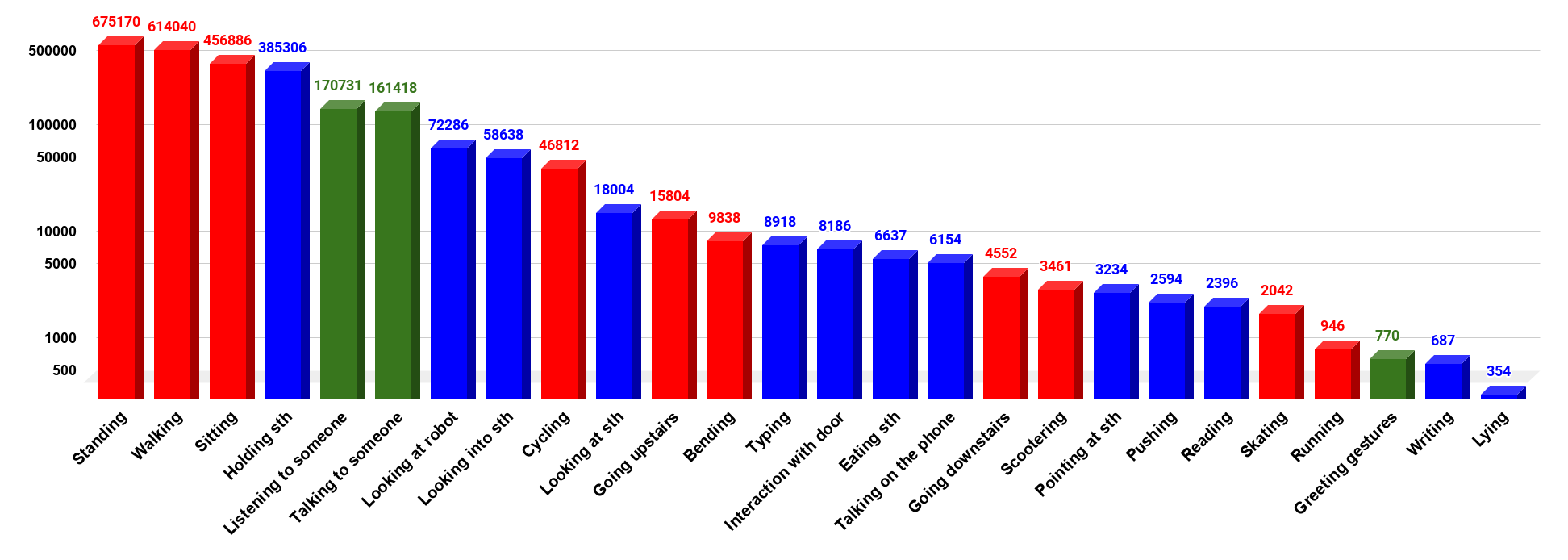
The availability of large-scale video action understanding datasets has facilitated advances in the interpretation of visual scenes containing people. However, learning to recognize human activities in an unconstrained real-world environment, with potentially highly unbalanced and long-tailed distributed data remains a significant challenge, not least owing to the lack of a reflective large-scale dataset. Most existing large-scale datasets are either collected from a specific or constrained environment, e.g. kitchens or rooms, or video sharing platforms such as YouTube. In this paper, we introduce JRDB-Act, a multi-modal dataset, as an extension of the existing JRDB, which is captured by asocial mobile manipulator and reflects a real distribution of human daily life actions in a university campus environment. JRDB-Act has been densely annotated with atomic actions, comprises over 2.8M action labels, constituting a large-scale spatio-temporal action detection dataset. Each human bounding box is labelled with one pose-based action label and multiple (optional) interaction-based action labels. Moreover JRDB-Act comes with social group identification annotations conducive to the task of grouping individuals based on their interactions in the scene to infer their social activities (common activities in each social group).
翻译:大规模视频行动理解数据集的可用性促进了对包含人的视觉场景的解读。然而,学习认识人类在不受限制的现实世界环境中的活动,可能高度不平衡和长篇分布的数据可能高度分布,这仍然是一项重大挑战,尤其是因为缺乏反映大规模数据集,大多数现有的大型数据集来自特定或受限的环境,例如厨房或房间,或视频共享平台,如YouTube。在本文中,我们引入了多式JRDB-Act,这是一个多式数据集,作为现有JRDB的延伸,由社交移动操纵器捕获,反映大学校园环境中人类日常生活行动的真实分布。JRDB-Ac-Act在原子行动上表现得非常密集,由2.8M行动标签组成,构成大型时尚动作检测数据集。每个人类捆绑框都标有一种基于外表的行动标签和多种(可选的)互动行动标签。此外,JRDB-Ac 与社会团体的识别说明都有利于个人群体的社会活动。每个团体在社会互动中进行社会场面活动。