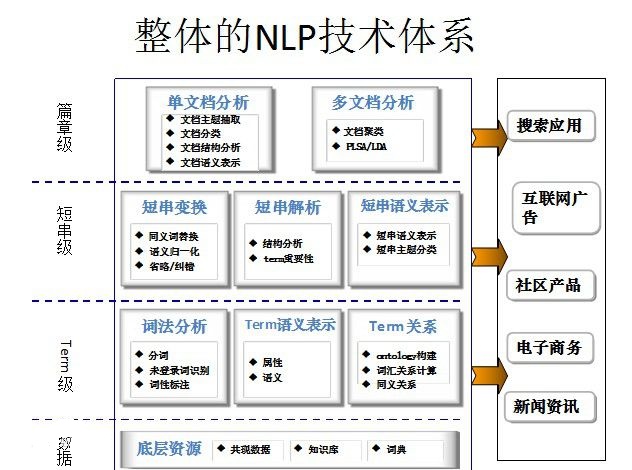
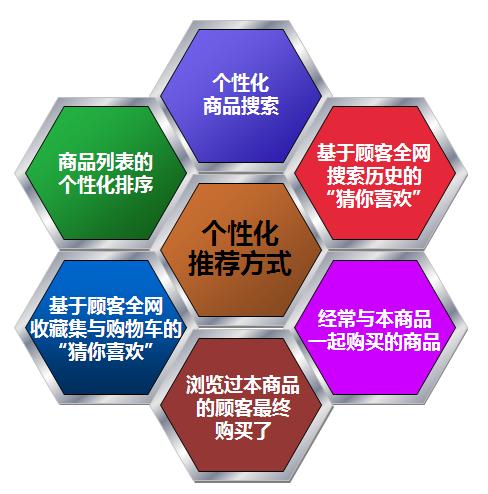
推荐系统,是指根据用户的习惯、偏好或兴趣,从不断到来的大规模信息中识别满足用户兴趣的信息的过程。推荐推荐任务中的信息往往称为物品(Item)。根据具体应用背景的不同,这些物品可以是新闻、电影、音乐、广告、商品等各种对象。推荐系统利用电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买过程。个性化推荐是根据用户的兴趣特点和购买行为,向用户推荐用户感兴趣的信息和商品。随着电子商务规模的不断扩大,商品个数和种类快速增长,顾客需要花费大量的时间才能找到自己想买的商品。这种浏览大量无关的信息和产品过程无疑会使淹没在信息过载问题中的消费者不断流失。为了解决这些问题,个性化推荐系统应运而生。个性化推荐系统是建立在海量数据挖掘基础上的一种高级商务智能平台,以帮助电子商务网站为其顾客购物提供完全个性化的决策支持和信息服务。