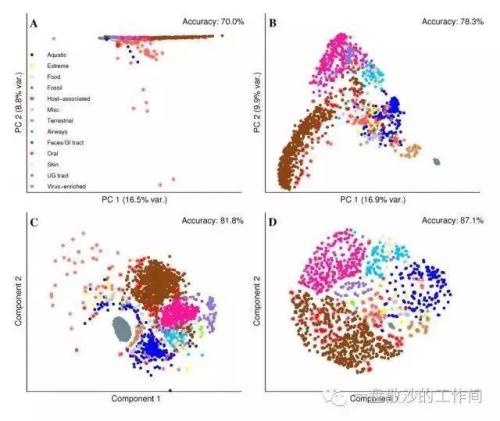
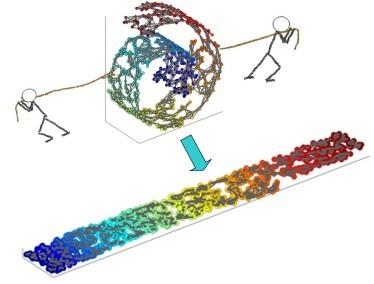
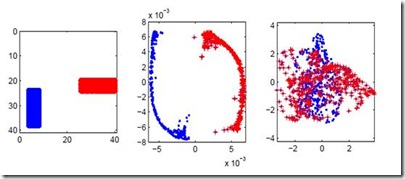
成为VIP会员查看完整内容
VIP会员码认证
首页
主题
发现
会员
服务
注册
·
登录
数据降维
关注
4863
数据降维
综合
百科
VIP
热门
动态
论文
精华
内置降维、聚类等算法,时间序列数据分析Python库Deeptime
机器之心
4+阅读 · 2021年1月23日
谷歌开源Embedding可视化工具
AINLP
0+阅读 · 2020年10月15日
【中科大】大数据算法(2020年春季)
专知
0+阅读 · 2020年5月16日
哈工大硕士生用Python实现了11种数据降维算法,代码已开源!
CVer
0+阅读 · 2019年11月30日
哈工大硕士生用 Python 实现了 11 种经典数据降维算法,源代码库已开放
新智元
3+阅读 · 2019年11月30日
2020年算法岗面试应该如何应对?
CVer
0+阅读 · 2019年10月30日
年薪30W起,如何4个月拿下AI算法工程师offer?
算法与数学之美
0+阅读 · 2019年10月14日
AI算法连载15:统计之数据降维
算法与数学之美
1+阅读 · 2019年10月12日
小孩都看得懂的主成分分析
平均机器
4+阅读 · 2019年9月22日
与其沉迷抖音,不如4个月拿下AI算法工程师offer!
算法与数学之美
1+阅读 · 2019年9月18日
年薪30W起,如何4个月拿下AI算法工程师offer?
大数据技术
0+阅读 · 2019年9月4日
年薪30W起,如何4个月拿下AI算法工程师offer?
算法与数据结构
0+阅读 · 2019年9月4日
npj: 电镜中的垃圾变黄金—深度神经网络
知社学术圈
0+阅读 · 2019年6月1日
机器学习中的编码器-解码器结构哲学
人工智能前沿讲习班
7+阅读 · 2019年3月20日
开源软件平台RAPIDS如何加速数据科学?| 超级公开课NVIDIA专场预告
智东西
0+阅读 · 2018年12月24日
参考链接
父主题
机器学习
数据挖掘
子主题
主成分回归
主成分分析
局部线性嵌入
流形学习
线性判别分析
因子分析
拉普拉斯特征映射
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top