
随着网络信息的爆炸式增长,推荐系统在缓解信息过载方面发挥了重要作用。由于推荐系统具有重要的应用价值,这一领域的研究一直在不断涌现。近年来,图神经网络(GNN)技术得到了广泛的关注,它能将节点信息和拓扑结构自然地结合起来。由于GNN在图形数据学习方面的优越性能,GNN方法在许多领域得到了广泛的应用。在推荐系统中,主要的挑战是从用户/项目的交互和可用的边信息中学习有效的嵌入用户/项目。由于大多数信息本质上具有图结构,而网络神经网络在表示学习方面具有优势,因此将图神经网络应用于推荐系统的研究十分活跃。本文旨在对基于图神经网络的推荐系统的最新研究成果进行全面的综述。具体地说,我们提供了基于图神经网络的推荐模型的分类,并阐述了与该领域发展相关的新观点。
摘要:
随着电子商务和社交媒体平台的快速发展,推荐系统已经成为许多企业不可缺少的工具[78]。用户依靠推荐系统过滤掉大量的非信息,促进决策。一个高效的推荐系统应该准确地捕捉用户的偏好,并提出用户潜在感兴趣的内容,从而提高用户对平台的满意度和用户留存率。
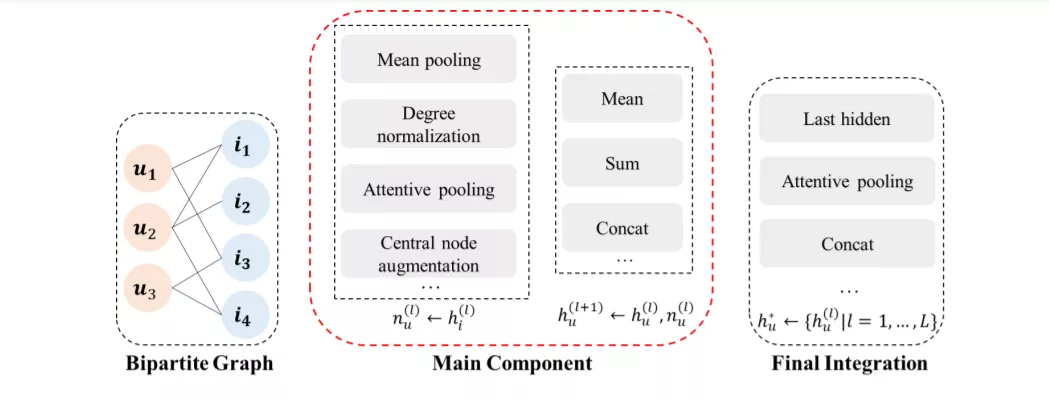
推荐系统根据用户的兴趣和物品属性来评估他们对物品的偏好。用户兴趣和项目属性都用压缩向量表示。因此,如何通过历史交互以及社会关系、知识图谱[49]等侧面信息来了解用户/项目嵌入是该领域面临的主要挑战。在推荐系统中,大多数信息都具有图结构。例如,用户之间的社会关系和与项目相关的知识图谱,自然就是图形数据。此外,用户与项目之间的交互可以看作是二部图,项目在序列中的转换也可以构建为图。因此,图形学习方法被用来获得用户/项目嵌入。在图学习方法中,图神经网络(graph neural network, GNN)目前受到了极大的追捧。
在过去的几年里,图神经网络在关系提取和蛋白质界面预测等许多应用领域取得了巨大的成功[82]。最近的研究表明,推荐器在以图[41]的形式引入用户/项目和边信息的交互时,性能有了很大的提升,并利用图神经网络技术得到了更好的用户/项目表示。图神经网络通过迭代传播能够捕捉用户-项目关系中的高阶交互。此外,如果社会关系或知识图谱的信息是可用的,则可以有效地将这些边信息集成到网络结构中。
本文旨在全面回顾基于图神经网络的推荐系统的研究进展。对推荐系统感兴趣的研究者和实践者可以大致了解基于图神经网络的推荐领域的最新发展,以及如何利用图神经网络解决推荐任务。本调查的主要贡献总结如下:
-
新的分类法:我们提出了一个系统的分类模式来组织现有的基于图神经网络的推荐模型。我们可以很容易地进入这个领域,并对不同的模型进行区分。
-
对每个类别的全面回顾,我们展示了要处理的主要问题,并总结了模型的总体框架。此外,我们还简要介绍了代表性模型,并说明它们是如何解决这些问题的。
-
我们讨论了当前方法的局限性,并在效率、多图集成、可扩展性和序列图构造方面提出了四个潜在的未来方向。

