

使大语言模型(LLMs)与人类对齐是一项具有挑战性的任务,这主要源于人类偏好反馈本身具有多维性和复杂性。尽管现有方法通常将该问题建模为一个多目标优化问题,但它们往往忽视了人类实际的决策方式。有限理性理论表明,人类决策往往遵循“满意化”(satisficing)策略——即在优化主要目标的同时,使其他次要目标达到可接受的阈值水平(Simon, 1956)。
为弥合这一差距,并将“满意化对齐”的理念应用于推理阶段,我们提出了 SITAlign:一种用于推理时的大语言模型对齐框架,其核心思想是在最大化主要目标的同时,对次要目标设置基于阈值的约束条件,以实现多维对齐的实用性。我们从理论上分析了该满意化推理对齐方法的次优界限,并通过多个基准测试进行了实证验证。
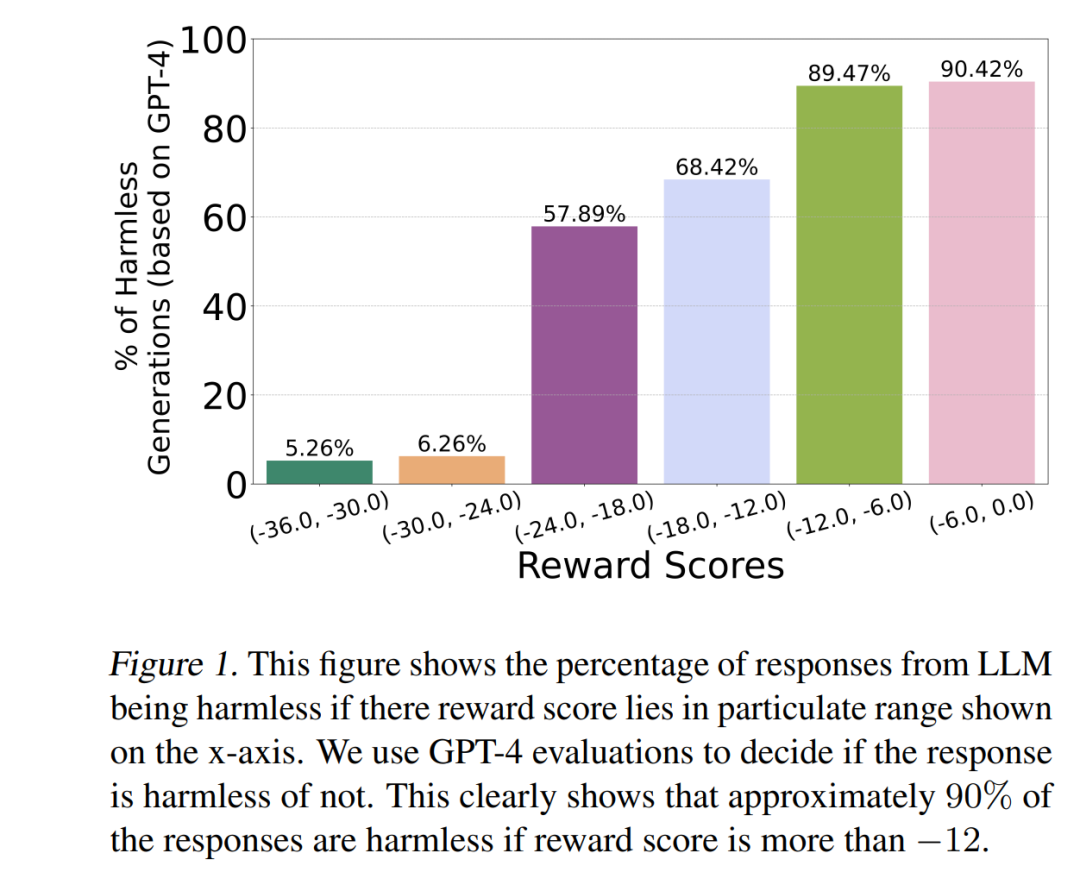
例如,在 PKU-SafeRLHF 数据集上,以最大化 有用性(helpfulness) 为主要目标、并确保 无害性(harmlessness) 满足预设阈值为约束条件时,SITAlign 相较于现有最优的多目标解码策略,在 GPT-4 的“有用性奖励胜平率”(win-tie rate)指标上提升了 22.3%,同时仍然满足无害性阈值要求。 这一研究表明,基于有限理性的满意化对齐策略,不仅更贴近人类实际决策机制,还能在保证安全性的同时显著提升模型输出的效用性。
成为VIP会员查看完整内容

相关内容

大语言模型是基于海量文本数据训练的深度学习模型。它不仅能够生成自然语言文本,还能够深入理解文本含义,处理各种自然语言任务,如文本摘要、问答、翻译等。2023年,大语言模型及其在人工智能领域的应用已成为全球科技研究的热点,其在规模上的增长尤为引人注目,参数量已从最初的十几亿跃升到如今的一万亿。参数量的提升使得模型能够更加精细地捕捉人类语言微妙之处,更加深入地理解人类语言的复杂性。在过去的一年里,大语言模型在吸纳新知识、分解复杂任务以及图文对齐等多方面都有显著提升。随着技术的不断成熟,它将不断拓展其应用范围,为人类提供更加智能化和个性化的服务,进一步改善人们的生活和生产方式。
相关VIP内容
相关资讯
相关论文