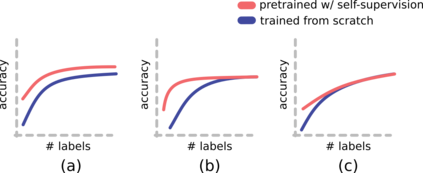
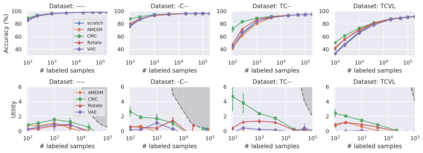
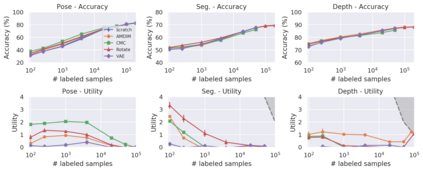
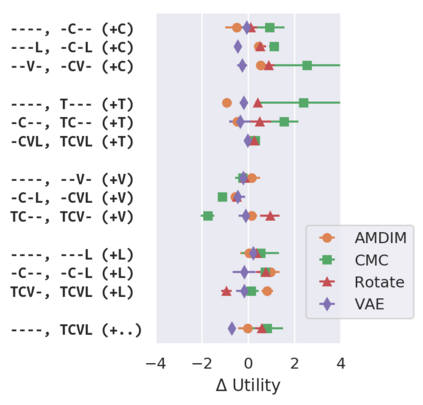
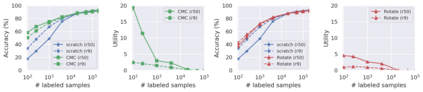
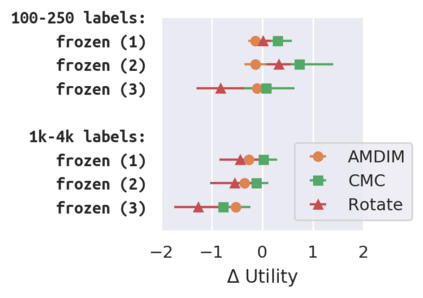
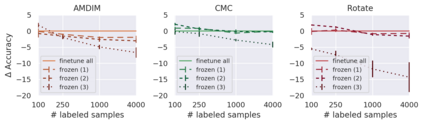
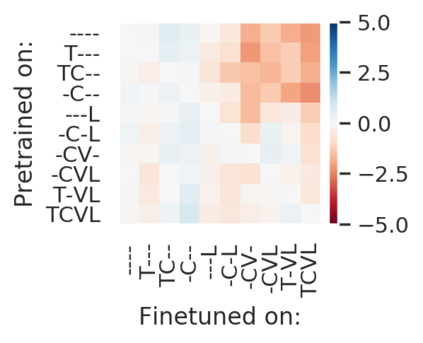
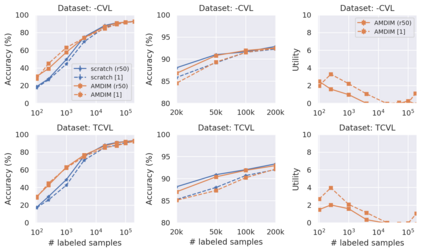
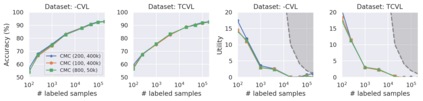
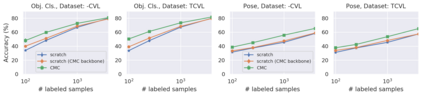
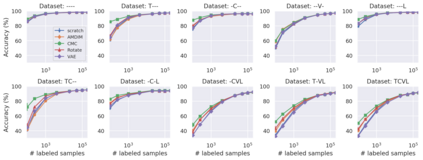
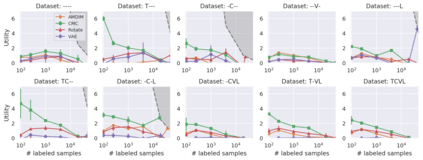
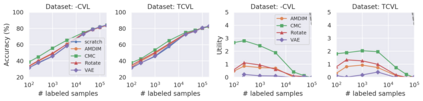
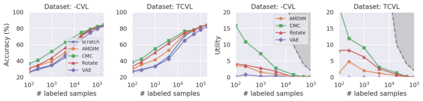
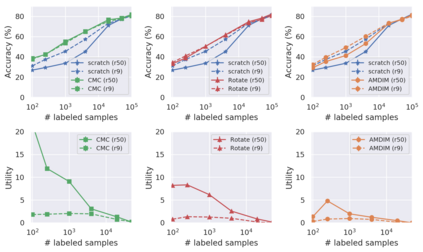
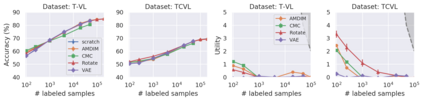
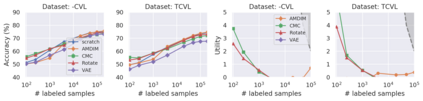
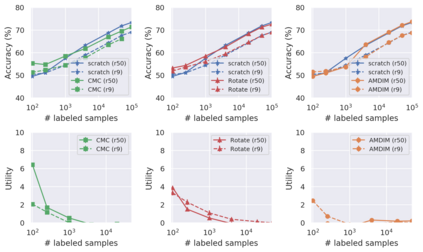
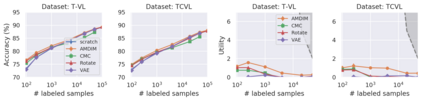
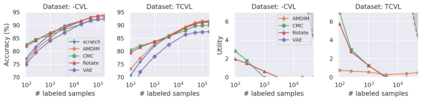
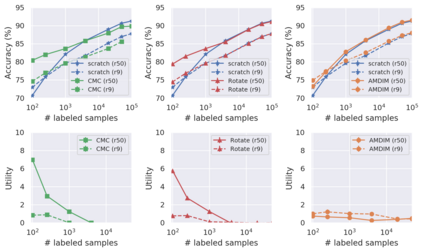
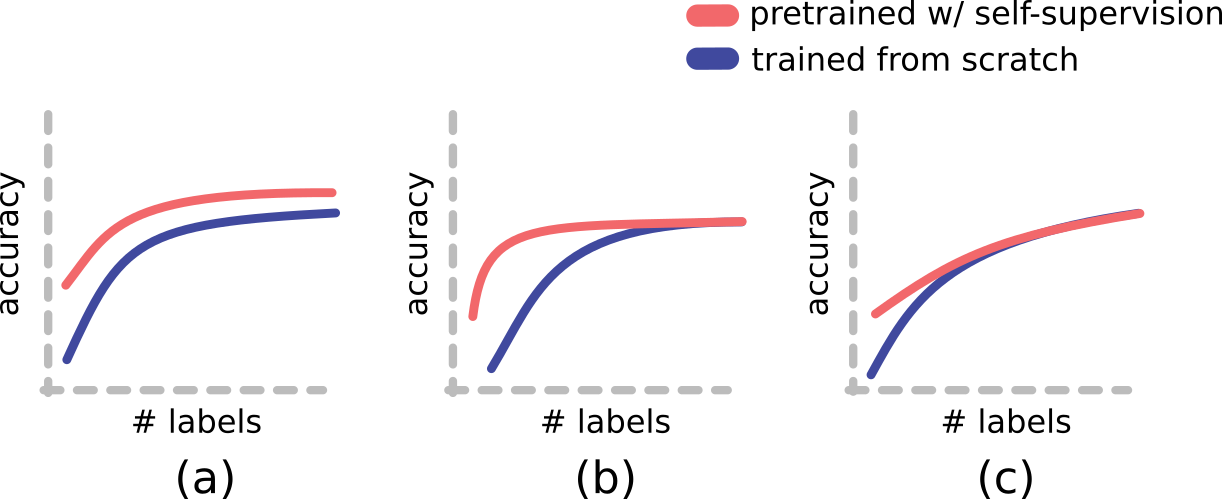
Recent advances have spurred incredible progress in self-supervised pretraining for vision. We investigate what factors may play a role in the utility of these pretraining methods for practitioners. To do this, we evaluate various self-supervised algorithms across a comprehensive array of synthetic datasets and downstream tasks. We prepare a suite of synthetic data that enables an endless supply of annotated images as well as full control over dataset difficulty. Our experiments offer insights into how the utility of self-supervision changes as the number of available labels grows as well as how the utility changes as a function of the downstream task and the properties of the training data. We also find that linear evaluation does not correlate with finetuning performance. Code and data is available at \href{https://www.github.com/princeton-vl/selfstudy}{github.com/princeton-vl/selfstudy}.
翻译:最近的进展刺激了在自我监督的视觉预科培训方面取得令人难以置信的进展。 我们调查了哪些因素在使用这些预科培训方法方面可以发挥作用。 为此,我们评估了各种综合合成数据集和下游任务的各种自监督算法。我们准备了一套合成数据,以便能够无休止地提供附加说明的图像,并完全控制数据集的困难。我们的实验为随着现有标签数量的增加而自我监督变化的效用以及作为下游任务功能和培训数据特性的效用变化提供了深刻的见解。我们还发现线性评价与微调性能不相关。代码和数据可在以下网站查阅:https://www.github.com/princent-vl/selstudy_github.com/prenceton-vl/el/selfstudy}。