
题目: Learning Representations For Images With Hierarchical Labels
摘要:
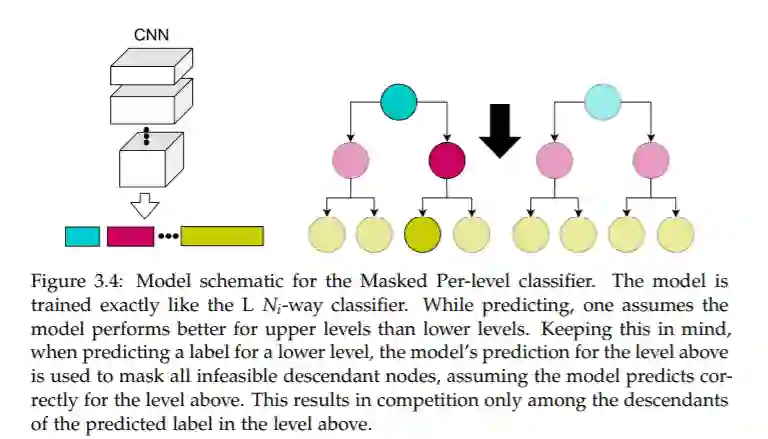
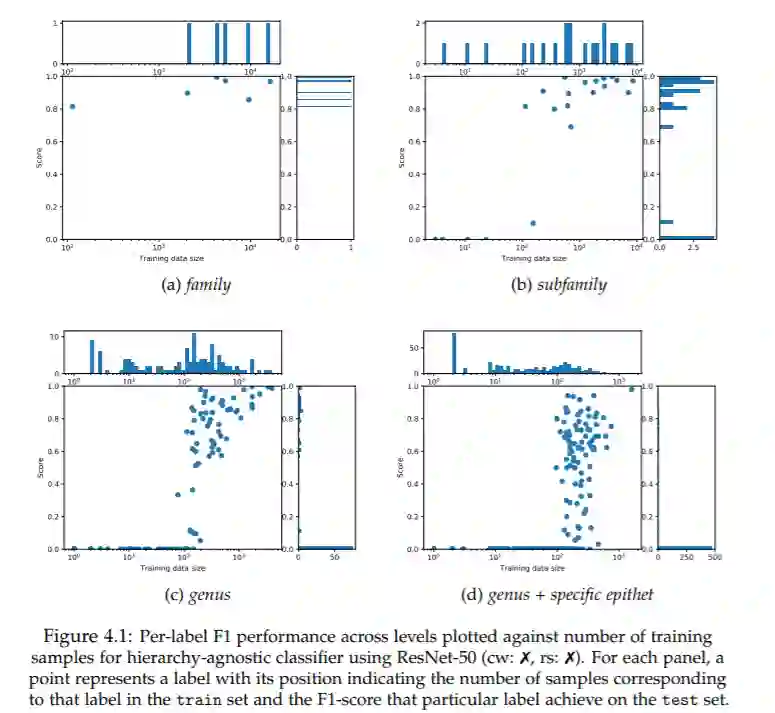
图像分类已经得到了广泛的研究,但是除了传统的图像标签对之外,在使用非常规的外部指导来训练这些模型方面的工作还很有限。在本文中,我们提出了一组利用类标签引起的语义层次信息的方法。在论文的第一部分,我们将标签层次知识注入到任意的分类器中,并通过实验证明,将这些外部语义信息与图像的视觉语义相结合,可以提高整体性能。在这个方向上更进一步,我们使用自然语言中流行的基于保留顺序的嵌入模型来更明确地建模标签-标签和标签-图像的交互,并将它们裁剪到计算机视觉领域来执行图像分类。尽管在本质上与之相反,在新提出的、真实世界的ETH昆虫学收集图像数据集上,注入层次信息的CNN分类器和基于嵌入的模型都优于不可知层次的模型。
成为VIP会员查看完整内容
相关内容



相关VIP内容
相关资讯
相关论文