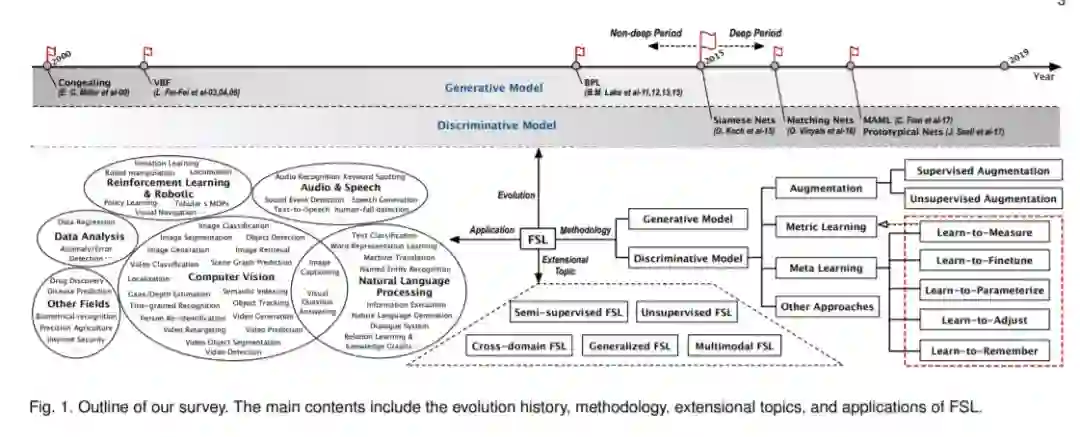
少样本学习(FSL)在机器学习领域具有重要意义和挑战性。成功地从很少的样本中学习和归纳的能力是区分人工智能和人类智能的一个明显的界限,因为人类可以很容易地从一个或几个例子中建立他们对新颖性的认知,而机器学习算法通常需要数百或数千个监督样本来保证泛化能力。尽管FSL的悠久历史可以追溯到21世纪初,近年来随着深度学习技术的蓬勃发展也引起了广泛关注,但迄今为止,有关FSL的调研或评论还很少。在此背景下,我们广泛回顾了2000年至2019年FSL的200多篇论文,为FSL提供了及时而全面的调研。在本综述中,我们回顾了FSL的发展历史和目前的进展,原则上将FSL方法分为基于生成模型和基于判别模型的两大类,并特别强调了基于元学习的FSL方法。我们还总结了FSL中最近出现的几个扩展主题,并回顾了这些主题的最新进展。此外,我们重点介绍了FSL在计算机视觉、自然语言处理、音频和语音、强化学习和机器人、数据分析等领域的重要应用。最后,我们对调查进行了总结,并对未来的发展趋势进行了讨论,希望对后续研究提供指导和见解。
地址:
https://www.zhuanzhi.ai/paper/ffc99a53aeb6629e21b9a42db76b9dd1
概述:
人类智能的一个令人印象深刻的特点是能够从一个或几个例子中迅速建立对新概念的认知。许多认知和心理学证据[184,224,371]表明,人类可以通过很少的图像[23]识别视觉物体,甚至儿童也可以通过一次偶见就记住一个新单词[35,51]。虽然从很少的样本中支持人类学习和归纳能力的确切原因仍是一个深刻的谜,但一些神经生物学研究[285,29,157]认为,人类显著的学习能力得益于人脑中的前额叶皮层(PFC)和工作记忆,特别是PFC特有的神经生物学机制与大脑中存储的以往经验之间的相互作用。相比之下,最先进的机器学习算法都需要大量数据,尤其是最广为人知的深度学习[186],它将人工智能推向了一个新的高潮。深度学习作为机器学习发展的重要里程碑,在视觉[172,319,120]、语言[231,318]、语言[127]、游戏[308]、人口学[97]、医学[74]、植物病理学[100]、动物学[252]等广泛的研究领域都取得了显著的成就。一般来说,深度学习的成功可以归结为三个关键因素:强大的计算资源(如GPU)、复杂的神经网络(如CNN[172]、LSTM[129])和大规模数据集(如ImageNet[287]、Pascal-VOC[75])。然而,在现实的应用场景中,比如在医学、军事、金融等领域,由于隐私、安全、数据标注成本高等因素,我们无法获得足够的标签训练样本。因此,使学习系统能够有效地从很少的样本中进行学习和归纳,成为几乎所有机器学习研究人员所期待的蓝图。
从高层次上看,研究少样本学习的理论和现实意义主要来自三个方面。首先,FSL方法不依赖于大规模的训练样本,从而避免了在某些特定应用中数据准备的高昂成本。第二,FSL可以缩小人类智能和人工智能之间的差距,是发展通用人工智能的必要之旅[191]。第三,FSL可以实现一个新兴任务的低成本和快速的模型部署,而这个任务只有几个暂时可用的样本,这有利于阐明任务早期的潜在规律。
少数样本学习(FSL),又称小样本学习、少样本学习或一次性学习,可以追溯到21世纪初。尽管该研究已有近20年的历史,在理论和应用层面上都具有重要意义,但到目前为止,相关的调查和综述还很少。在本文中,我们广泛调查了从21世纪头十年到2019年几乎所有与FSL相关的科学论文,以详细阐述一个系统的FSL调研。我们必须强调,这里讨论的FSL与zero-shot learning (ZSL)正交[346],这是机器学习的另一个热门话题。ZSL的设置需要与概念相关的侧面信息来支持跨概念的知识迁移,这与FSL有很大的不同。据我们所知,到目前为止,只有两份与fsl相关的预先打印的综述伦恩[305,349]。与他们相比,本次综述的新颖之处和贡献主要来自五个方面:
(1) 我们对2000年至2019年的200多篇与FSL相关的论文进行了更全面、更及时的综述,涵盖了从最早的凝固模型[233]到最新的元学习方法的所有FSL方法。详尽的阐述有助于把握FSL的整个发展过程,构建完整的FSL知识体系。
(2) 根据FSL问题的建模原则,我们提供了一种可理解的层次分类法,将现有的FSL方法分为基于生成模型的方法和基于判别模型的方法。在每个类中,我们根据可一般化的属性进一步进行更详细的分类。
(3) 我们强调当前主流目前的方法,例如,基于目前的元学习方法,和分类成五大类,他们希望通过元学习策略学习学习,包括Learn-to-Measure Learn-to-Finetune, Learn-to-Parameterize,学会调整和Learn-to-Remember。此外,本调查还揭示了各种基于元学习的FSL方法之间潜在的发展关系。
(4) 总结了最近在普通FSL之外出现的几个外延研究课题,并回顾了这些课题的最新进展。这些主题包括半监督FSL、无监督FSL、跨域FSL、广义FSL和多模态FSL,它们具有挑战性,同时也为许多现实机器学习问题的解决赋予了突出的现实意义。这些扩展主题在以前的综述中很少涉及。
(5) 我们广泛总结了现有FSL在计算机视觉、自然语言处理、音频和语音、增强学习和机器人、数据分析等各个领域的应用,以及目前FSL在基准测试中的表现,旨在为后续研究提供一本手册,这是之前综述中没有涉及到的。
本文的其余部分组织如下。在第2节中,我们给出了一个概述,包括FSL的发展历史、我们稍后将使用的符号和定义,以及现有FSL方法的分类建议。第3节和第4节分别详细讨论了基于生成模型的方法和基于判别模型的方法。然后,第5节总结了FSL中出现的几个扩展主题。在第6节中,我们广泛地研究了FSL在各个领域的应用以及FSL的基准性能。在第8节中,我们以对未来方向的讨论来结束这次综述。