数据科学是设计从大量数据中提取知识的算法和管道。时间序列分析是数据科学的一个领域,它感兴趣的是分析按时间顺序排列的数值序列。时间序列特别有趣,因为它让我们能够可视化和理解一个过程在一段时间内的演变。他们的分析可以揭示数据之间的趋势、关系和相似性。存在大量以时间序列形式包含数据的领域:医疗保健(心电图、血糖等)、活动识别、遥感、金融(股票市场价格)、工业(传感器)等。
在数据挖掘中,分类是一项受监督的任务,它涉及从组织到类中的带标签的数据中学习模型,以便预测新实例的正确标签。时间序列分类包括构造用于自动标注时间序列数据的算法。例如,使用健康患者或心脏病患者的一组标记的心电图,目标是训练一个模型,能够预测新的心电图是否包含病理。时间序列数据的时序方面需要算法的发展,这些算法能够利用这种时间特性,从而使传统表格数据现有的现成机器学习模型在解决底层任务时处于次优状态。
在这种背景下,近年来,深度学习已经成为解决监督分类任务的最有效方法之一,特别是在计算机视觉领域。本论文的主要目的是研究和发展专门为分类时间序列数据而构建的深度神经网络。因此,我们进行了第一次大规模的实验研究,这使我们能够比较现有的深度学习方法,并将它们与其他基于非深度学习的先进方法进行比较。随后,我们在这一领域做出了大量的贡献,特别是在迁移学习、数据增强、集成和对抗性攻击的背景下。最后,我们还提出了一种新的架构,基于著名的Inception 网络(谷歌),它是目前最有效的架构之一。
我们在包含超过100个数据集的基准测试上进行的实验使我们能够验证我们的贡献的性能。最后,我们还展示了深度学习方法在外科数据科学领域的相关性,我们提出了一种可解释的方法,以便从运动学多变量时间序列数据评估外科技能。
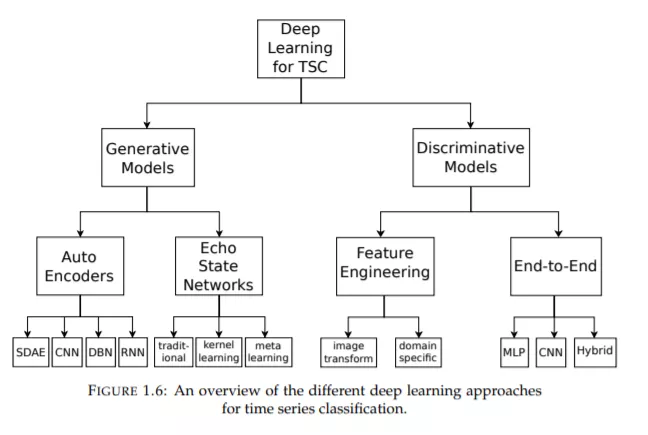
深度学习序列分类概述
在过去的二十年中,TSC被认为是数据挖掘中最具挑战性的问题之一(Yang and Wu, 2006; Esling and Agon, 2012)。随着时间数据可用性的增加(Silva et al.,2018),自2015年以来已有数百种TSC算法被提出(Bagnall et al.,2017)。由于时间序列数据具有自然的时间顺序,几乎在每一个需要某种人类认知过程的任务中都存在时间序列数据(Langkvist, Karlsson, and Loutfi, 2014)。事实上,任何使用考虑到排序概念的已注册数据的分类问题都可以被视为TSC问题(Cristian Borges Gamboa, 2017)。时间序列在许多实际应用中都遇到过,包括医疗保健(Gogolou等,2018)和人类活动识别(Wang et al.,2018;到声学场景分类(Nwe, Dat, and Ma, 2017)和网络安全(Susto, Cenedese, and Terzi, 2018)。此外,UCR/UEA档案中数据集类型的多样性(Dau等,2019;Bagnall et al,2017)(最大的时间序列数据集储存库)展示了TSC问题的不同应用。