
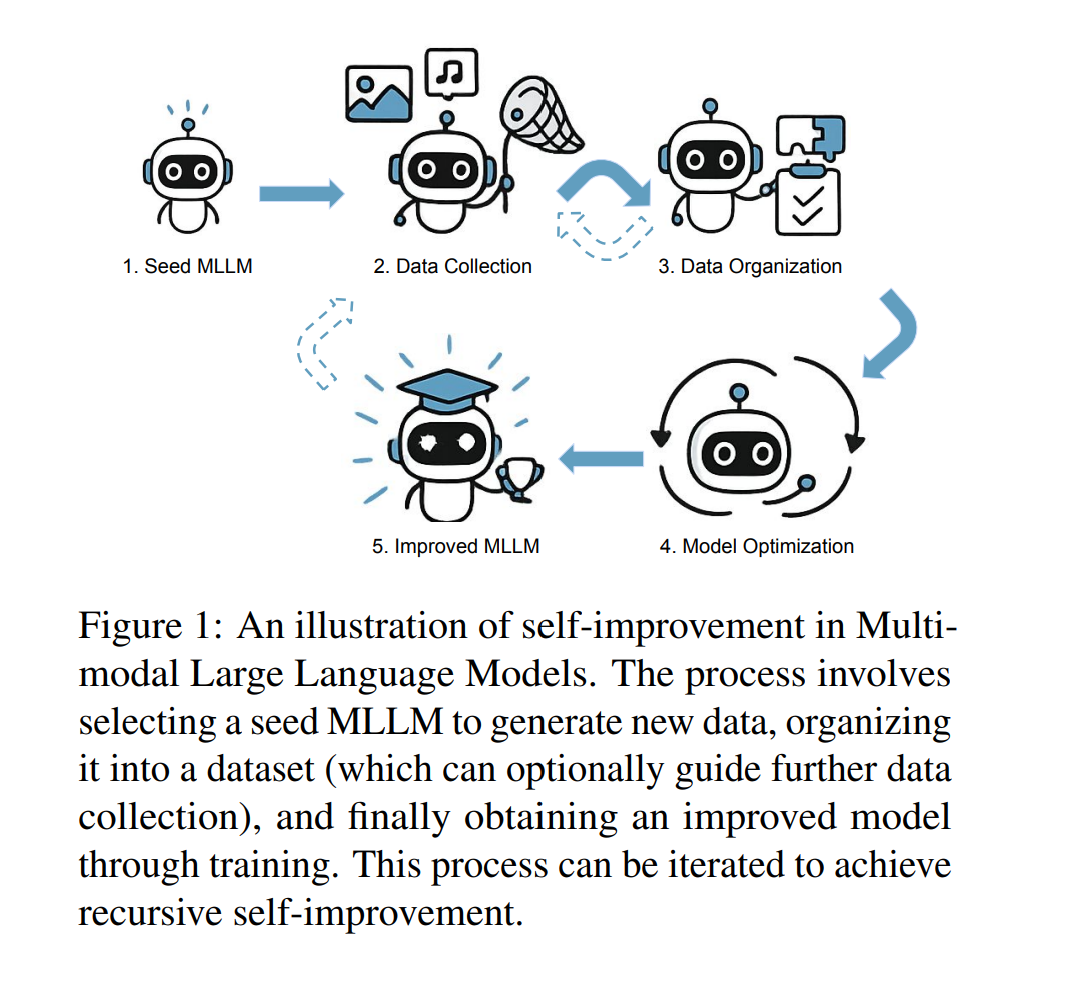
近年来,大语言模型(LLMs)的自我改进(Self-Improvement)取得了显著进展,能够在无需显著增加成本,尤其是人工干预的情况下,有效提升模型能力。
尽管这一研究方向仍处于早期阶段,但其向多模态领域的扩展具有巨大潜力,可充分利用多样化数据源,从而构建更具通用性和自主学习能力的自我改进模型。 本文是首篇系统综述多模态大语言模型(MLLMs)自我改进研究的工作。我们对现有文献进行了结构化梳理,并从三个核心视角总结相关方法:
数据收集(Data Collection),
数据组织(Data Organization),
模型优化(Model Optimization), 以促进MLLM自我改进技术的进一步发展。
此外,我们还综述了该领域中常用的评测方法与下游应用场景。最后,本文对开放性挑战与未来研究方向进行了总结与展望。
1 引言(Introduction)
**自我改进(Self-improvement)旨在使模型具备自主收集与组织训练所需数据的能力,从而生成性能更优的下一代模型。这一范式为克服静态训练模式中成本高昂的扩展瓶颈与潜在性能上限提供了新的路径。 在多模态大语言模型(Multimodal Large Language Models, MLLMs)**中,自我改进的目标是让模型利用自身能力获取新的训练数据,并据此优化自身性能,从而实现持续改进。近期研究(Favero et al., 2024; Deng et al., 2024b; Amirloo et al., 2024)表明,这种方法能够在较低成本下显著减少幻觉现象(hallucination),并提升模型在通用任务上的表现。
目前,该方向已取得重要进展。一些工作(Zhou et al., 2024a)将自我改进与外部工具或同伴模型结合,以部分实现自我优化;另一些研究(Yu et al., 2024b)则尝试仅依靠单一模型完成全部流程,朝着完全自我改进(full self-improvement)迈进。尽管已有研究(Tao et al., 2024)总结了文本型LLM的自我改进机制,且其他综述亦探讨了MLLM的一般性框架(Yin et al., 2024; Zhang et al., 2024a)或特定问题(如幻觉,Bai et al., 2024),但迄今为止仍缺乏一项专门针对MLLM自我改进方法的系统综述。为弥补这一空白,本文旨在对该领域进行全面梳理,并识别亟需解决的关键挑战。 与LLM中的自我改进(Huang et al., 2022; Tao et al., 2024)相比,MLLM的自我改进面临多模态融合带来的独特挑战。例如,多模态特性可能引发模态对齐问题(modality alignment problem),而这一问题被认为是MLLM幻觉产生的重要原因之一(Li et al., 2023b)。此外,现有的MLLM通常无法独立生成所有所需的训练数据,因为多数模型(Liu et al., 2024a; Bai et al., 2023)尚不具备直接生成图像的能力。尽管如此,学界对利用自我改进提升MLLM效率与效果的兴趣日益增长,并已取得一系列令人鼓舞的成果。 本文旨在系统总结现有工作、比较不同方法,并为后续研究提供清晰方向。全文结构如下: * 首先,我们概述MLLM自我改进的整体研究背景; * 接着,介绍用于自我改进起点的种子模型(Seed Models); * 随后,如图2所示,我们将详细方法分为三部分进行讨论:数据收集(Data Collection)、数据组织(Data Organization)与模型优化(Model Optimization),并对各方法进行对比分析; * 同时,我们整理了用于评估自我改进效果的常用指标与基准结果,以支持系统性比较; * 此外,还讨论了相关下游应用场景,以展示该范式的实际影响; * 最后,我们总结当前领域的主要挑战与潜在研究方向,并给出总体结论。
通过本综述,我们希望为下一代具备更强自我改进机制的多模态大语言模型提供清晰的发展路径,推动该领域从带有偏差的随机探索走向系统化研究,并吸引更多研究者投入这一前景广阔的方向。