【深度】Google提出「自监督」表征学习方法,让智能体通过「观察」认识世界
原文来源:www.cs.unm.edu
作者:Debidatta Dwibedi、Jonathan Tompson、Corey Lynch、Pierre Sermanet
来源:雷克世界
导语:现如今,在用于各种计算机视觉任务的最先进方法中包含一个视觉表征学习步骤。而在本文中,Google提出了一种用于连续控制任务的自监督表征学习方法。通过在嵌入空间中联合嵌入多个帧,扩展了从视觉观察中进行学习的时间对比网络(TCN),引入了多帧时间对比网络(mfTCN),从而可以更好地对位置和速度进行估计,从而在连续控制任务中实现更好的性能表现。
在这项研究中,我们探索了一种新的方法,让机器人简单地通过观察世界从而认识世界。特别地,我们调查了在连续控制任务中学习任务不可知论表征的有效性。我们通过在嵌入空间中联合嵌入多个帧而不是单个帧,扩展了从视觉观察中进行学习的时间对比网络(Time-Contrastive Networks,TCN)。我们证明,通过这样做,我们现在能够更准确地对位置和速度属性进行编码。我们在强化学习环境中测试了这种自监督方法(self-supervised approach)的有用性。我们证明,智能体通过观察自身所采取的动作或其他智能体成功地执行任务而学习的表征,可以使用诸如近端策略优化(Proximal Policy Optimization,PPO)这样的算法来学习连续控制策略,仅使用已学习的嵌入作为输入。

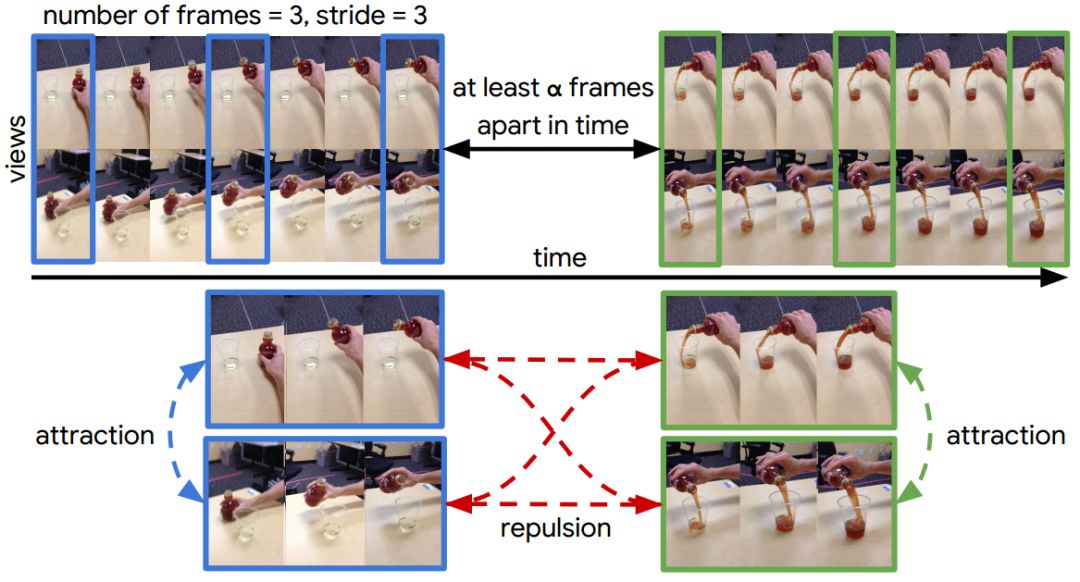
图1:对于同一事件的两个视角,我们从视频中剪抽取片段,并将其进行嵌入以为每个视图生成多帧时间对比网络(mfTCN)嵌入。为了对深度网络进行训练,我们同时从不同的角度考虑不同的片段,并且从不同的时间步骤中截取不同的片段。
现如今,许多用于各种计算机视觉任务的最为先进的方法包括了一个视觉表征学习步骤。通常情况下,这种预训练是使用一个监督替代损失(surrogate loss)进行的,其中有充足的训练据可供使用,最常见的是大规模ImageNet或COCO分类数据集。当然,如果你能同样利用基于像素的机器人控制的监督预训练,这将会是非常有用的。但是,我们目前还尚不清楚这些任务需要到底什么样的正确监督。
图2:在上图中,我们展示了我们是如何从一个批量中进行采样从而对我们的模型进行训练。 如第一行所示,我们同时从两个视图中采样片段,其中每个片段包含3帧,每帧之间跨度为3。我们确保剪辑不重叠,并且它们之间至少有一个α时间间隔差距。从仅有的两个样本,我们可以看到自监控信号的强度,这迫使模型在相似的框架中寻找差异,同时寻找不同视图之间的相似性。
作为监督学习的替代性方法,最近的一些诸如时间对比网络(TCN)或位置速度编码器(PVE)等自监督方法,在涉及构建适合于强化学习(RL)和机器人应用程序的具有鲁棒性的视觉表征时,已经显示除了令人鼓舞的结果,而不需要昂贵的监督标签。这些方法从有用的域中的观察中学习表征。这些方法的共同之处是辅助损失(auxiliary loss)的构建,从而推动模型学习有用的结构先验,如时序一致性(temporal consistency)、视图不变性(view invariance)等。PVE支持在模拟环境中学习连续控制策略,而TCN被证明有助于模仿学习,在这种情况下,机械手臂用于将液体倒入容器中。但是,这两种方法都存在一定的缺点。在TCN中,嵌入以单个帧为条件进行进行的。这使得学习运动线索变得困难。同样地,PVE需要为每个环境调优一组先验。此外,使用这些技术所学习的表征还没有与在真实状态下直接进行训练的策略的表现性能相匹配。
然而,尽管最近的自监督技术尚且存在一定的局限性,但这些方法所学习的表征具有我们希望在本研究中能够利用的许多理想属性:1.嵌入可用于区分观察过程中的不同状态(包括运动属性),而不需要明确的状态标签。2.嵌入应该对视角的变化具有强大的鲁棒性,从而使第三方能够从演示中进行学习,获得其中大量的现成的训练数据(例如YouTube视频)。3.嵌入应该适合新环境中的在线适应,而不需要附加的标签。
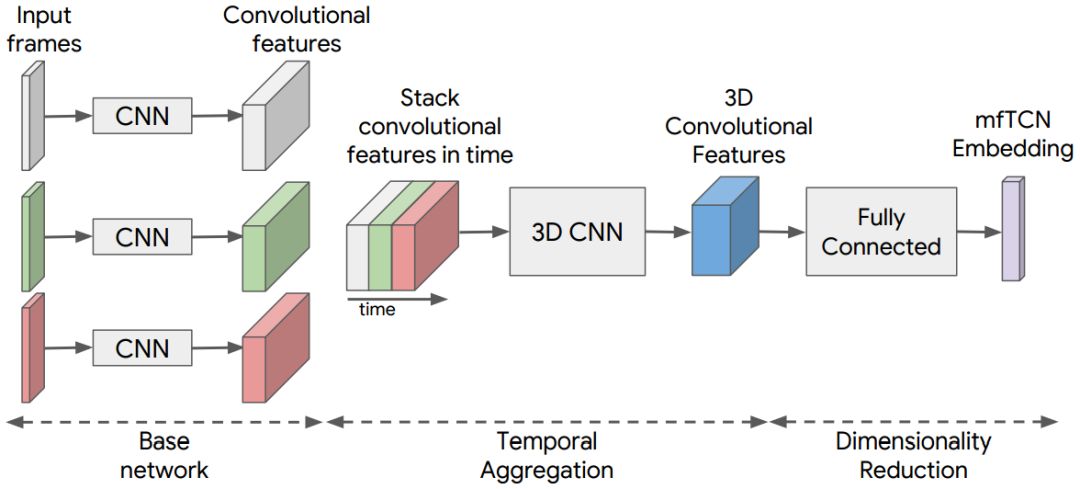
图3:用于从给定的帧序列中提取mfTCN嵌入的架构。我们添加了3D卷积层,用于将跨帧的时间信息聚合在一起并且在mfTCN嵌入中对运动信号进行编码。
本文的贡献是:
•我们引入了TCN的一种多帧变体,我们将其称之为多帧时间对比网络(mfTCN),它能够更好地对时间潜在状态(如速度、角速度、加速度等)进行编码。
•我们的研究表明,这些表征可以用作DeepMind的控制套件中模拟机器人控制任务的PPO已训练策略的输入。
•我们还表明,使用mfTCN所学习的策略能够与基于真实状态的策略相媲美。
在本文中,我们证明了我们的方法可以从像素中对智能体的本体感受状态进行编码。我们期望这种方法也可以学习环境中相关目标的丰富表征。目前,该方法的一个缺点在于,嵌入可以选择固定在环境中的一些目标上从而忽略了其他目标。即使在我们的实验中,我们只使用了已学习的嵌入来学习控制策略,但是在更为实际的环境设置中,我们应该同时使用嵌入和本体感受状态作为输入。尽管我们的表征学习方法是自监督的,但它仍然依赖于对可能状态的合理覆盖。这些问题可以通过明确的探索策略(如内在动机(intrinsic motivation))或专家示范加以缓解。
在本文中,我们通过允许它联合嵌入多个帧来扩展TCN。我们通过实验结果证明,通过这样做,我们可以更好地对位置和速度进行估计,从而在连续控制任务中实现更好的性能表现。我们发现,这种学习具有鲁棒性视觉表征的方法使得我们能够在已学习的表征上,而不是真实的状态中有效地使用策略学习算法。可以这样说,模拟环境中的结果是令人鼓舞的,而我们的目标是使用这个模型来学习更具鲁棒性的关于真实机器人的策略。未来,我们还希望能够根据智能体在开始学习控制策略时所遇到的任何新状态来对表征进行优化。
原文链接:http://www.cs.unm.edu/amprg/Workshops/MLPC18/submissions/paper_10.pdf
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【征稿通知】IEEE IV 2018“智能车辆中的平行视觉”研讨会
☞【征稿】神经计算专刊Virtual Images for Visual Artificial Intelligence
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】诺丁汉大学提出使用GAN进行「人脸识别」中的「人脸特征点定位」
☞【干货】ICML2018论文公布!一文了解机器学习最新热议论文和研究热点

