针对典型海空协同作战中指挥控制技术对时效性、准确性和跨域融合能力的高要求, 提出了一种先验知识启发的双层强化学习框架. 通过研究先验知识启发的奖励塑造方式, 提取作战子任务设计状态聚合方法, 从而把具体状态映射到抽象状态; 基于抽象状态使用马尔科夫决策过程(Markov decision process, MDP)理论进行建模, 使用强化学习算法求解该模型; 使用最终求解出的抽象状态价值函数进行基于势能的奖励塑造. 以上流程与下层具体MDP 过程并行求解, 从而搭建了一个双层强化学习算法框架.基于全国兵棋推演大赛的兵棋推演平台进行了实验, 在状态空间、动作空间、奖励函数等方面细化算法. 指出了先验知识代表从上而下的任务式指挥方式, 而多智能体强化学习在某些结构上符合自下而上的事件式指挥方式. 两种方式结合, 使得该算法控制下的作战单元学习到协同作战战术, 面对复杂环境具有更好的鲁棒性. 经过仿真实验, 该算法控制的红方智能体对抗规则智能体控制的蓝方可以获得70 %的胜率.海空协同作战是高技术战争条件下最为典型的 作战样式之一[1] , 其作战空间包含海、空、天、电磁等领 域, 具有典型的跨域作战特征. 海空协同作战面临战场态势复杂快变、信息不完 全、不同域之间战术协同困难、决策时效性要求高等 问题[2] , 需要指挥员从跨域的视角审视问题, 将不同领 域的能力予以互补, 对指挥控制技术提出了更高的要 求[3-4] . 传统的指挥控制理论具有局限性[5] , 较多考虑同 一领域力量的叠加性利用, 缺乏跨域视角[6] . 近年来, 以 多智能体强化学习(multi-agent-reinforcement-learning, MARL)为代表的智能决策技术发展迅速, 在星际 争霸[7]、足球[8]比赛等大型实时策略类游戏应用中甚至 能够击败人类顶尖玩家, 该技术在解决多智能体对抗 博弈问题领域中具有显著优势, 为研究海空协同作战 的指挥控制技术开辟了新的技术路线. 综上所述, 研究多智能体强化学习技术在海空协 同作战的指挥决策中的应用, 有助于辅助指挥官制定 战略战术, 推动新型指挥控制技术的研究.
首先介绍典型多智能体强化学习算法(monotonic value function factorisation for deep multi-agent reinforcement learning, QMIX)的研究现状, Tabish 等研究 者提出的 QMIX 算法[9]采用分布式决策、集中式训练 的方法, 在理论上可以较好地适应海空协同作战的特 点. 作战编成中的各个作战单元可以根据局部观测进 行决策, 同时在全局信息和奖励分解的帮助下兼顾全 局最优策略. 但是在实际应用中, 海空协同作战往往 比较复杂, 存在奖励稀疏的问题, 单纯的 QMIX 算法 存在探索效率不高 [10] , 鲁棒性较差的问题, 这会导致 算法最后无法学习到较好的协作策略. 为提升 QMIX 算法性能, 本文将目光投向了专家 先验知识[11] . 在海空协同作战中, 往往存在许多与作 战相关的高阶先验知识[12] , 子任务是其中最重要也是 最常见的一种. 指挥员通过对作战阶段的划分, 在时 间上把复杂的总作战任务分解成多个子任务, 通过从 上而下的任务式指挥方式, 指导作战集群完成一系列 子任务, 最终实现总作战任务. 如何使用子任务相关的先验知识提高 QMIX 算 法的性能, 成为了本文的关键研究问题之一. 为有效使用子任务相关的先验知识, 首先研究先 验知识与强化学习算法的结合方式, 在强化学习中, 先验知识可以是一种偏好, 或是一种目标状态. 为了 将先验知识嵌入到算法中, 偏好可以用智能体在选择 不同动作的概率分布表示[13]; 目标状态可以用相应的 奖励进行表示. 这些先验知识发生在强化学习训练以 前, 由人类根据以往的实践经验或是主观想法设定. Takato 等研究者将奖励函数的自动塑造方法与 状态聚合方法结合, 提出了使用在线奖励塑造加速单 智能体强化学习训练的方法[14] . 但是该方法使用的状 态聚合由志愿者人工指定, 且没有验证在多智能体强 化学习中的可行性.
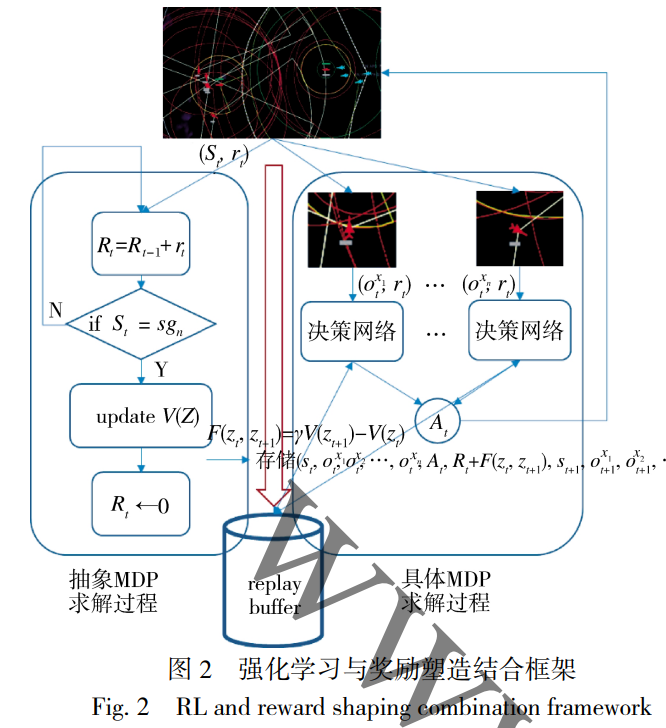
针对上述研究背景与研究问题, 本文提出了一种 战术先验知识启发的多智能体双层强化学习算法. 根 据人类先验知识, 把 MARL 问题的总任务分解成一 系列的子任务, 设计状态聚合方法, 构建了状态聚合 函数, 把具体状态映射到抽象状态. 接着基于抽象状 态对抽象 MDP 进行建模[15] , 使用强化学习算法求解该 模型. 最后使用求解出的抽象状态价值函数进行基于 势能的奖励塑造. 以上流程与下层具体 MDP 并行求 解, 从而搭建了一个双层强化学习算法框架, 使得奖 励稠密化, 加速下层 MDP 的求解. 为验证算法效果, 本文基于海空协同作战这一任务背景进行了仿真实 验. 实验结果表明, 使用战术先验知识启发的多智能 体双层强化学习算法能够指挥智能体团体实现总体 作战意图, 学习到协同作战的策略. 与此同时, 各智能 体仍可以根据自身观察和全局信息作出独立决策, 具 有较好的鲁棒性, 符合作战要素融合化和去中心化的 特点.