【导读】人工智能顶会 ICLR 2021 即国际表征学习大会, 是人工智能领域全球最具影响力的学术会议之一,因此在该会议上发表论文的研究者也会备受关注。据官方统计,今年共有3013篇论文提交。ICLR 采用公开评审,可以提前看到这些论文。小编发现推荐系统(Recommendation System)相关的投稿paper很多,和常见的推荐系统paper不太一样,投稿的大部分理论研究偏多,希望大家多多关注。
为此,这期小编继续为大家奉上ICLR 2021必读的六篇推荐系统投稿相关论文——深度隐变量模型、可解释关系表示模型、多方面信任推荐、不确定性推荐、循环探索网络、分解推荐
ICLR 2021 Submitted Paper: https://openreview.net/group?id=ICLR.cc/2021/Conference
ICLR2020CI、ICML2020CI
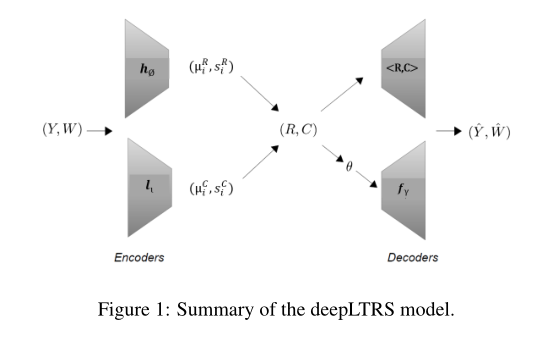
1. DEEPLTRS: A Deep Latent Recommender System based on User Ratings and Reviews
摘要:为了给用户提供基于观察到的用户评分和商品评论文本的高质量推荐,我们引入了一个深度隐变量推荐系统(deep latent recommender system, deepLTRS)。Latent的动机是,当用户只给几个产品打分时,评论中的文本信息是一个重要的信息来源。评论信息的加入可以缓解数据稀疏性,从而增强模型的预测能力。我们的方法采用变分自编码器结构作为生成性深度隐变量模型,用于编码用户对产品的评分的有序矩阵(ordinal matrix)和评论的文档术语矩阵。此外,与唯一的基于用户或基于项目的模型不同,Deep LTRS假定用户和产品都具有潜在的表示。我们提出了一种交替的用户/产品小批量优化结构,用于联合捕获用户和商品的偏好。在模拟和真实数据集上的数值实验表明,Deep LTRS的性能优于最新技术,特别是在极端数据稀疏的情况下。
网址: https://openreview.net/forum?id=JUc6-1xuOX
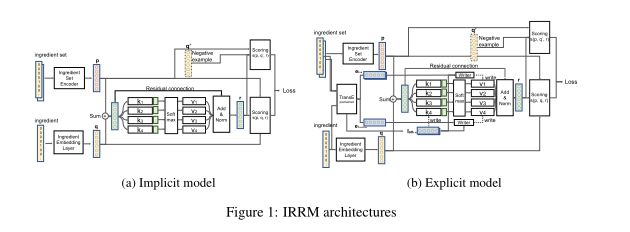
2. Interpretable Relational Representations For Food Ingredient Recommendation Systems
摘要:食物配料推荐系统支持厨师创造新的食谱是具有挑战性的,因为好的配料组合取决于许多因素,如味道、气味、烹饪风格、质地等。使用机器学习来解决这些问题的尝试很少。重要的是,有用的模型不仅需要准确,更重要的是-特别是对于食品专业人士-是可解释的。为了解决这些问题,我们提出了可解释关系表示模型(Interpretable Relational Representation Model, IRRM)。该模型的主要组成部分是一个键-值记忆网络,用于表示成分之间的关系。我们提出并测试了该模型的两个变体。一个可以通过可训练的记忆网络(隐式模型)学习潜在的关系表示,而另一个可以通过集成外部知识库(显式模型)的预训练的记忆网络学习可解释的关系表示。模型产生的关系表示是可解释的-它们允许核对为什么建议某些配料配对。显式模型还允许集成任何数量的手动指定的约束。我们在分别有45,772个食谱的CulinaryDB和55,001个食谱的Flavorne这两个食谱数据集上进行了实验。实验结果表明,我们的模型具有预测性和信息性。
网址: https://openreview.net/forum?id=48goXfYCVFX
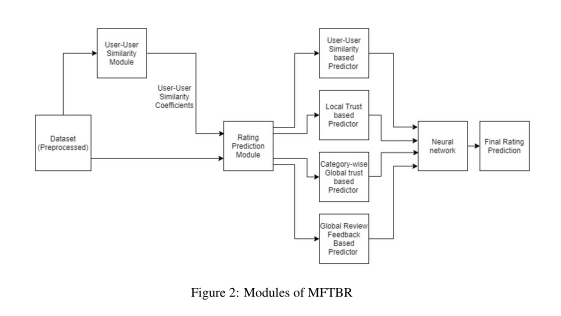
3. Multi-faceted Trust Based Recommendation System
摘要:推荐系统对用户在互联网上做出的选择中起着决定性的作用。他们寻求为用户量身定做决策。由于人们认为用户与他们信任的人相似,会做出与这些用户相似的选择,这使得信任(trust)成为推荐系统中的一个非常重要的因素。在协同推荐系统(collaborative recommendation systems)中,信任及其对人们选择的影响已经被广泛研究。可以理为,信任不是一层不变的,而是可以随上下文变化的。最近在基于信任的推荐系统领域的研究表明,使用基于trust的方法极大地提高了推荐质量(Mauro等人,2019年;Fang等人,2015年)。我们提出了一个推荐系统,该系统在考虑产是否适合特定用户的同时,考虑了信任的多个方面。这种基于多方面信任的推荐器(MFTBR)体系结构考虑到了可扩展性--不需要太多的努力就可以添加新的信任方面--并且不会对动态性信任方面进行任意加权。取而代之的是,通过神经网络优化权重以获得最佳结果。这里考虑的信任方面是本地信任、全局信任和类别信任。MFTBR的性能明显好于基本协同过滤-U2UCF(C.Desrosiers,2011),以及社交和基于信任的推荐系统领域的一些成熟模型-MTR(Mauro等人,2019年)和SocialFD(Yu等人,2017年)。因此,我们的模型不仅考虑了信任对推荐的影响,而且考虑了信任建立的上下文,从而提供了更接近现实生活中的推荐。
网址: https://openreview.net/forum?id=tUNXLHsIx3r
4. PURE: an Uncertainty-aware Recommendation Framework for Maximizing Expected Posterior Utility of Platform
摘要:商业推荐可以看作是推荐平台与其目标用户之间的互动过程。平台的一个关键问题是如何充分利用其优势,使其效用最大化,即推荐所带来的商业利益。本文提出了一种新的推荐框架,该框架有效地利用了用户在不同项目维度上的不确定性信息,并且显式地考虑了展示策略对用户的影响,从而使平台获得最大的期望后验概率(maximal expected posterior)。我们将获得最大期望后验概率的最优策略问题描述为一个约束非凸优化问题,并进一步提出了一种基于ADMM的解来导出近似最优策略。通过对从真实推荐平台收集的数据进行了大量的实验,验证了该框架的有效性。此外,我们亦采用建议的架构框架进行试验,以揭示平台如何取得商业效益。研究结果表明,平台应满足用户对用户喜欢的商品维度的偏好,而对于用户不确定性较高的商品维度,该平台可以通过推荐实用性高的商品来获得更多的商业收益。
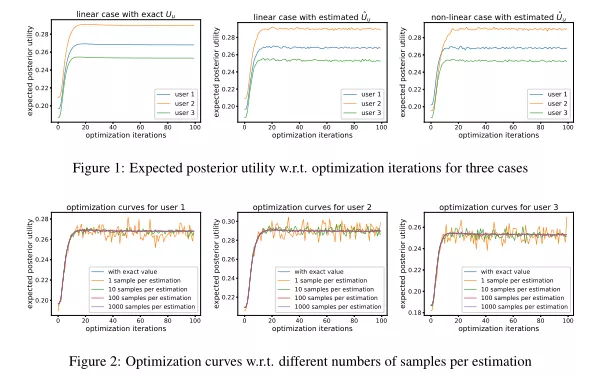
网址: https://openreview.net/forum?id=D5Wt3FtvCF
5. Recurrent Exploration Networks for Recommender Systems
摘要:循环神经网络已被证明在推荐系统建模序列用户反馈方面是有效的。然而,它们通常只关注项目相关性,而不能有效地为用户挖掘多样化的项目,从而在长远来看损害了系统的性能。为了解决这个问题,我们提出了一种新型的循环神经网络,称为循环探索网络( recurrent exploration networks, REN),在潜在空间中联合进行表示学习和有效探索。试图平衡相关性和探索性,同时考虑到表征中的不确定性。我们的理论分析表明,即使在学习的表示存在不确定性的情况下,REN也可以保持速率最优的 sublinear regret(Chu等人,2011)。我们的实验研究表明,REN在合成和真实推荐数据集上都能获得令人满意的长期回报,表现优于最先进的模型。

网址: https://openreview.net/forum?id=WN_6sThEI_-
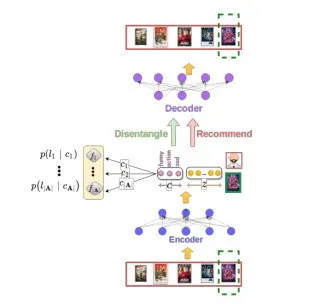
6. Untangle: Critiquing Disentangled Recommendations
摘要:大多数协同过滤方法背后的核心原则是将用户和项目嵌入到潜在空间中,在潜在空间中,独立于任何特定项目属性学习各个维度。因此,用户很难基于特定方面(评论)控制他们的推荐。在这项工作中,我们提出了Untangle:一种推荐模型,它允许用户相对于特定的项目属性(例如,不那么暴力的、更有趣的电影)控制推荐列表,这些属性在用户偏好中具有因果关系。Untangle使用精细化的训练过程,通过训练:(i)一部分监督的β-VAE来解开(disentangles)项目表示,以及(ii)第二阶段,其优化以生成对用户的推荐。Untangle可以根据用户喜好控制对推荐的评论,而不会牺牲推荐的准确性。此外,只需要极少的标签项就可以创建与属性无关的偏好表示。