
由无界智慧(Spatialtemporal AI)团队推出的A0模型,是首个基于空间可供性感知的通用机器人操作模型,通过具身无关的可供性表征实现了跨平台的通用操作能力,在Franka、Kinova、Realman 和 Dobot等多个机器人平台上进行了验证。相比VLA方法RDT-1B和π0,在复杂操作任务中成功率高出70%,执行步骤仅需4-5步,是VLA方法效率的10倍,相关论文已被ICCV 2025接收,模型框架和代码等已经全面开源。
论文链接: https://arxiv.org/abs/2504.12636 项目主页: https://a-embodied.github.io/A0/
引言:机器人操作面临的核心挑战
在机器人技术飞速演进的时代,赋予机器人通用操作能力依然是行业面临的核心难题。例如“擦拭白板”这类任务,机器人不仅需要明确施力的位置("where"),更需规划抹布的运动轨迹("how")。然而,现有方法在空间可供性(affordance)理解方面依然存在不足。
现有主流研究路线包括:模块化方法与端到端视觉-语言-动作(VLA)大模型。前者借助视觉基础模型来提升空间感知,但在捕捉物体的可供性细节方面有所欠缺;后者虽然能够直接生成动作指令,却难以对空间位置形成深层次认知,因而在如擦拭白板或物体堆叠等复杂任务中表现不佳。
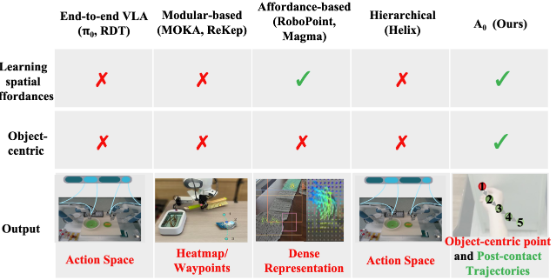
图1. 机器人操作方法对比
机器人操作是机器人技术和具身智能领域中一个基础却极具挑战性的任务,要求机器人在复杂环境中与物体进行交互。近期的研究主要集中在两类方法:(1)基于模块化的方法,利用大型视觉基础模型进行空间理解;(2)端到端的视觉-语言-动作(VLA)方法,用于细粒度操作。然而,现有方法在理解空间可供性——即对象交互的“何处”(where)与“如何”(how)——方面仍存在显著局限,而空间可供性正是实现空间智能的关键。例如,在执行擦拭白板等任务时,对空间可供性的理解不足往往导致执行不完整或效率低下。
空间可供性不仅可以从真实和合成的机器人数据集中学习,还可以从诸如互联网数据和手-物交互(HOI)数据等富含可操作性知识的异域数据中获取。这些数据集包含了关于物体交互、空间属性和物理特性的宝贵信息,因此将可操作性知识表示为统一的空间可供性表示尤为必要。基于模块化的方法,如 ReKep和 MOKA,虽能直接利用视觉大模型(LVM),却缺乏对空间和物理世界的深度理解,尤其在捕捉物体可操作性方面存在不足。另一方面,端到端方法如 RDT 和 π0 直接生成动作,却无法充分理解空间位置,导致在擦白板或堆叠物体等复杂操作任务中的表现不佳。
近年来,一些方法开始认识到空间可供性在机器人操作中的重要性。基于点的方法如 SpatialVLA、Any-point Trajectory Modeling、RoboPoint、Track2Act,以及基于流的方法如 General Flow、Im2Flow2Act,在建模空间交互方面取得了显著进展。然而,这些方法通常侧重于密集的空间表示或完整的轨迹建模(见图 1),计算开销大且依赖于特定机械臂平台。相比之下,我们的方法以对象为中心,仅关注预测待操作物体的接触点和后续轨迹。我们提出了一种具身无关的可供性表示(Embodiment-Agnostic Affordance Representation),用于捕捉对象交互的“何处”与“如何”。这种设计使得方法具身无关,可在不同机器人平台间实现无缝泛化;并且,仅需少量任务特定的标注数据进行微调,即可满足实际部署的高效性与通用性。
为了解决操控任务中空间理解与物理推理的难题,我们提出了 A0——一种专为机器人操作设计的新型可供性感知分层模型。该模型将操作任务分解为两个层次:(1)高层的空间可供性理解;(2)低层的动作执行。模型与系统架构如图 2所示。A0 主要聚焦于高层的空间可供性理解,包括对象接触点和接触后轨迹,以有效地指导低层的动作执行。为了学习基础的定位能力,A0 首先在 100 万条接触点定位数据上进行预训练,随后在带注释的空间轨迹数据集上进行监督微调。这一分层设计使得 A0 能够更有效地应对复杂操作任务,尤其是那些需要空间可供性推理与物理交互的场景。实验结果显示,在 Franka 机械臂上,A0 的平均成功率达到 62.50%;在 Kinova 机械臂上达到 53.75%,均优于现有最强基线。值得注意的是,A0 在擦拭白板等轨迹跟踪任务中的表现也十分稳健,成功率达 45%。
我们的主要贡献如下: 1. 提出具身无关的可供性表示:通过预测面向对象的接触点和后续轨迹,高效捕捉空间可供性;该表示由 100 万条标注数据及高效标注流水线支持。面向点的设计使其高度灵活,易于在不同机器人平台间部署。 1. 设计层次化可供性感知扩散模型 A0:模型首先学习具身无关的可供性表示,然后生成精确的操作动作。为增强空间可供性理解,模型引入了位置偏移注意力(Position Offset Attention)、DiT模块和空间信息聚合层(Spatial Information Aggregation Layer)等关键组件。 1. 在多种机器人平台上验证有效性:我们在 Franka、Kinova、Realman 和 Dobot 等平台上进行了广泛实验,A0 在需要空间可供性推理的复杂任务中(如擦拭白板或放置物体)表现优异,充分展示了其强大的泛化能力与具身无关设计优势。
A0模型的创新突破
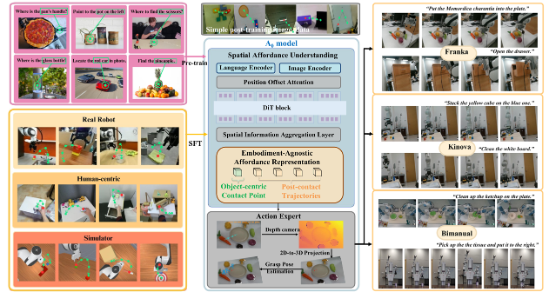
图2. A0模型总体图 A0在以下三方面实现了突破: 1. 分层任务分解:将操控流程拆分为高层的可供性理解与底层的动作执行两部分,实现任务的结构化分解; 1. 具身无关设计:输出仅依赖物体接触点与路径,不依赖任何特定机器人硬件; 1. 高效表征学习:通过100万接触点数据的预训练与示例轨迹微调,实现跨平台、跨任务的操作泛化。
技术核心:如何实现空间可供性感知?
A0的技术架构包含两大核心组件:
**1. 具身无关可供性表征 **
研究团队构建了统一的可供性表征,整理整合了来自四类数据源的操作知识:
- 互联网数据(PixMo-One-Point:100万单接触点标注),从公开的PixMo-Points数据集中筛选出单个点标注的数据得到。
- 人机交互数据(HO4D-22k:22,000条人-物交互轨迹)
- 真实机器人数据(DROID-3k:3,000条操作轨迹)
- 仿真数据(ManiSkill-5k:4,965条仿真轨迹)
这种表征仅包含物体中心的图像、2D路径点和语言指令,实现了跨数据源的统一表示。
**2. 分层扩散模型架构 **
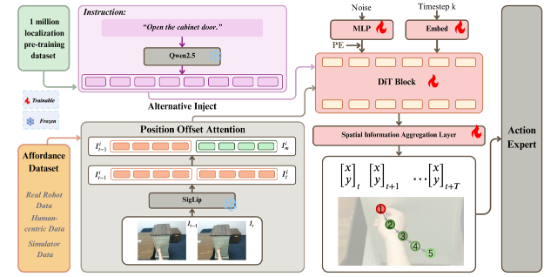
图3. A0模型结构图
模型采用基于DiT的扩散模型,其输入是T×2的高斯噪声,预测机器人操作的T个时间步的2D路径点。使用Qwen2.5-7B和SigLip (400M) 作为语言和图像编码器得到对应的嵌入表示。当前图像和前一步图像经过SigLip的嵌入表示进行拼接。通过交叉注意力交替地输入语言和图像的嵌入表示到DiT层作为扩散模型的条件。
模型包含两大创新模块:
- 位置偏移注意力(POA):通过当前帧与前一帧的token差值获取运动信息
- 空间信息聚合层(SIAL):将潜在空间映射回物理空间的非线性MLP解码器
训练过程分为两个阶段:
- 预训练:使用100万规模的PixMo-One-Point数据集,使用MSE损失监督第一个路径点预测
- 有监督微调:扩展至T个路径点预测,融入运动信息理解
DiT前向和反向过程分别设置为1000和5步。推理阶段采用DPM-Solver求解。
**动作执行 **
基于扩散模型得到的T个2D路径点生成动作。A0 模型的动作生成流程包括三步:
- 2D→3D 投影 对图像上预测的关键点(包括接触点和后续方向提示点),利用深度图和相机内参反投影到三维空间,得到每个点的 3D 坐标。
- 抓取姿态估计 以反投影的接触点为参考,调用 GraspNet 或其他抓取采样器生成一组候选抓取姿态,再挑选最贴近该点的最佳抓取方案。
- 路径点选择与执行 对剩余方向提示关键点同样反投影至三维,并让 VLM例如GPT-4o 判断它们在自由空间中的高度类别(如“与目标平齐”或“高于目标”),最后在 SE(3) 空间内插值生成平滑轨迹,驱动真实机器人完成操作。
实验结果:跨平台验证卓越性能
研究团队在Franka、Kinova、Realman和Dobot四种机器人平台上进行了全面验证:
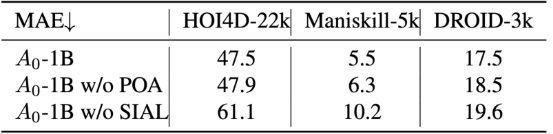
- 离线评估: 评测A0模型在HOI4D-22k, Maniskill-5k和DROID-3k数据集上预测路径点的准确率,使用像素值MAE指标 (三个数据集的图像分辨率分别是1920×1080, 512×512, and 320×180)。训练集和测试集按照8:2划分。结果如下表所示。 预训练能够提升模型对空间物体位置定位能力和泛化能力。消融实验证明了POA和SIAL模块都是有效的,SIAL能够有效地将中间层特征映射为动作的2D路径点。
- 预训练使HOI4D-22k和ManiSkill-5k数据集的像素值MAE分别降低47.5和5.5
- 移除POA会使ManiSkill-5k上的MAE增加0.8
- 移除SIAL会使HOI4D上的MAE飙升13.2
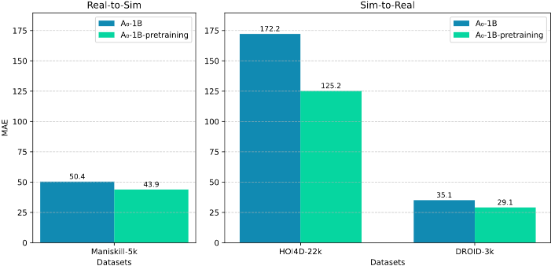
图4. 预训练模型MAE性能
表1. 离线评估 & 消融实验
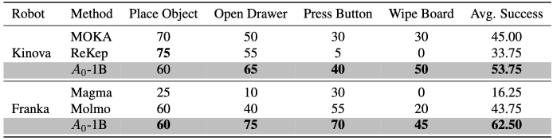
- 真实场景测试: 在机器人平台测试四种不同类型任务“放置物体”“打开抽屉”“按下按钮”“擦干净白板”的执行成功率。
- 在Franka平台上平均成功率达到62.5%,较次优方法提升18.75%
- 在Kinova平台上达到53.75%成功率,较最弱基线提升20%
- 特别在"擦白板"任务中表现突出(成功率45%)

图5. Franka Emika真机评测
表2. SOTA方法性能对比
- 对比实验:
- 与VLA方法RDT-1B、π0和π0-FAST进行对比。评测指标使用任务执行的平均成功率。
- 在“放置物体”任务中,A0成功率达到60%,比RDT-1B高出40%,比π0高出20%,比π0-FAST高出25%
- 在“打开抽屉”任务中,A0成功率达到65%,比RDT-1B高出65%,比π0高出45%,比π0-FAST高出55%
- 在“按下按钮”任务中,A0成功率是40%,比RDT-1B高出15%,比π0高出30%,比π0-FAST高出10%
- RDT-1B和π0-FAST在“擦白板”任务中全部失败,π0的成功率只有10%,而A0成功率显著高于上述方法,达到50%。
- A0执行步骤仅需4-5步,是VLA方法的1/8到1/10
表3. 与RDT-1B和π0在Kinova真机上对比实验


应用前景与未来方向
A0模型已展现出在家庭服务、工业操作等场景的应用潜力。研究团队指出未来两大改进方向:
抓取姿态估计:对于姿态敏感型任务例如“旋转把手”,结合VLM视觉辅助选择最优抓取位置和执行动作,或者采集少量样本微调。 1. 长序列任务:利用VLM基础模型将长序列任务分解成子任务,再使用A0模型实现底层动作执行。 1. 高度估计优化:整合深度信息直接预测高度
这项工作为实现通用机器人操作提供了新思路,其分层设计和具身无关特性,有助于机器人快速适应多样化任务和平台。
无界智慧团队介绍
无界智慧(Spatialtemporal AI)是一家专注于基于时空智能的跨场景具身Agent的AI公司,致力于打造具备自主感知、理解、决策与执行能力的服务机器人系统。我们当前面向“康养场景”构建具备真实任务执行能力的智能康养机器人,部署于养老院、康养社区、家庭养老、示范样板间等场景。
无界智慧团队成员由来自CMU、UIUC、MBZUAI、清华、北大、中山大学、南方科技大学以及中科院的研究人员组成。团队在机器人和人工智能领域具有深厚的学术造诣,已在T-PAMI、CVPR、ICCV、ICML、NeurIPS、ICLR、ICRA、RSS等国际顶级会议和期刊上发表数百篇高水平学术论文。
团队表示,目前正在持续迭代基于时空智能的通用具身大模型和通用具身Agent,推动具身智能和人形机器人领域的技术突破。
合作联系:wangsy@spatialtemporal.ai
END

