
题目: Octet: Online Catalog Taxonomy Enrichment with Self-Supervision
简介:
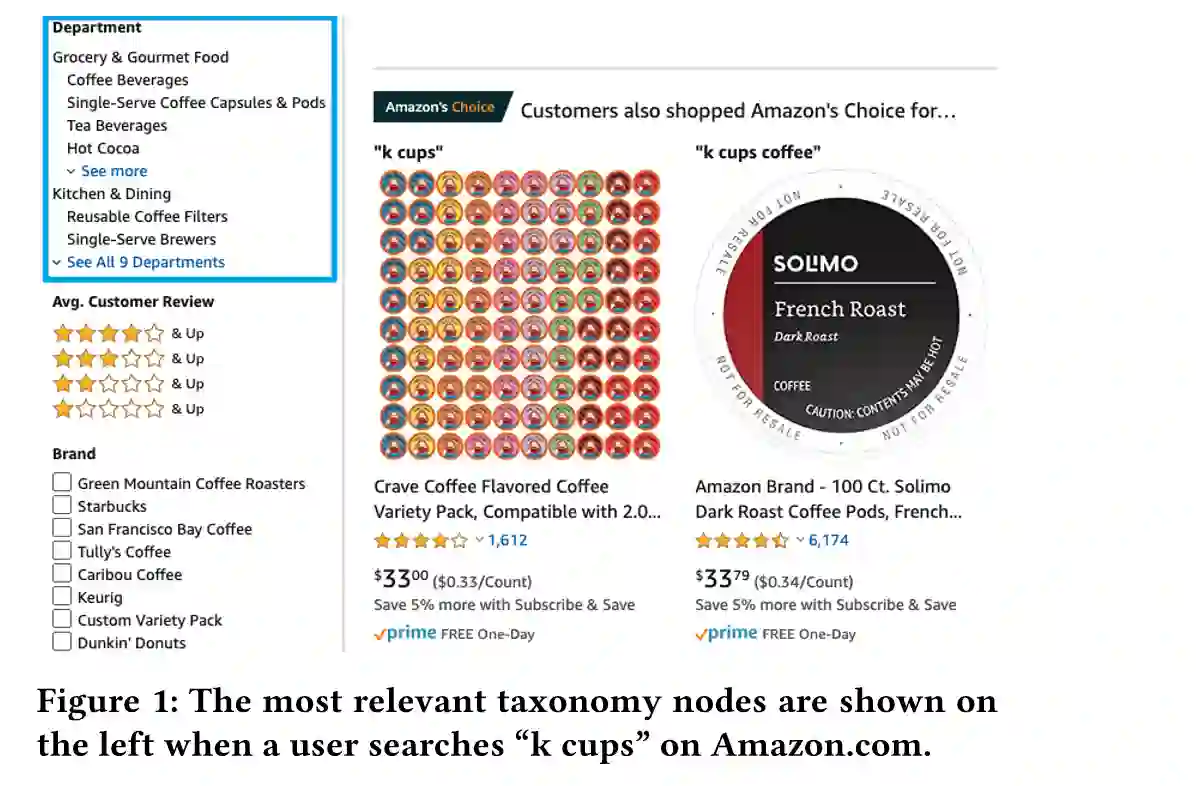
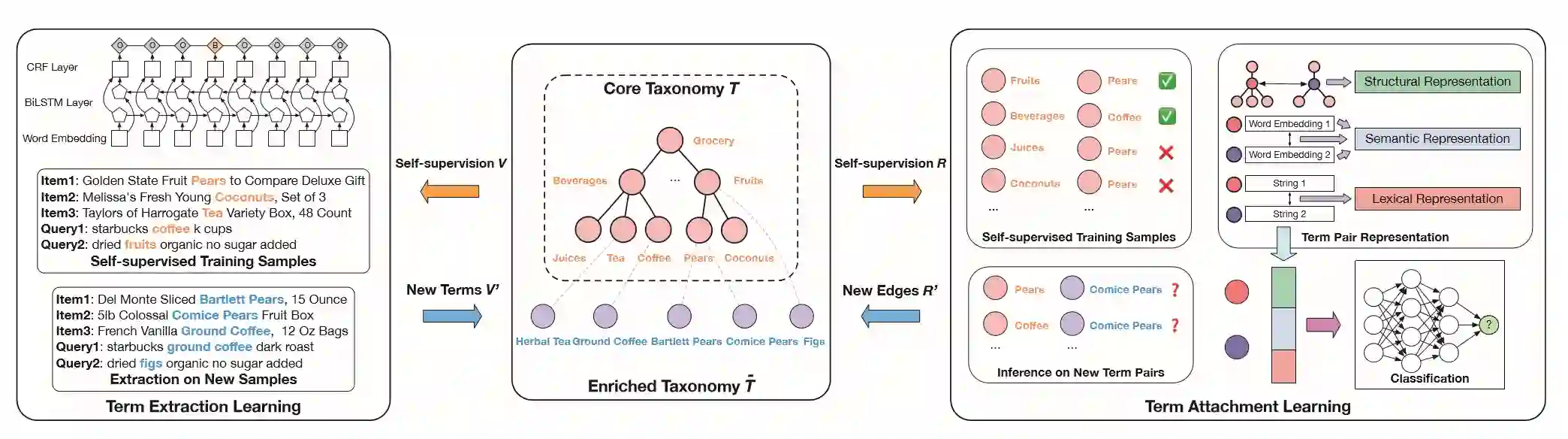
分类法在各个领域都有广泛的应用,特别是在在线项目分类、浏览和搜索方面。尽管在线目录分类法的使用很普遍,但实际上大多数分类法都是由人类维护的,这是劳动密集型的,难以扩展。虽然从零开始的分类学构建在文献中得到了大量的研究,但是如何有效地丰富现有的不完全分类学仍然是一个开放而重要的研究问题。分类法的丰富性不仅要求对新出现的术语具有健壮性,而且要求现有分类法结构与新术语附件之间的一致性。在本文中,我们提出了一个自我监督的端到端框架Octet,用于在线目录分类法的丰富。Octet利用联机目录分类法独有的异构信息,例如用户查询、项及其与分类法节点的关系,而不需要除现有分类法以外的其他监督。提出了一种用于术语提取的序列标记模型,并利用图神经网络(GNNs)来捕获术语连接的分类结构和查询项分类交互。在不同的在线领域进行的大量实验表明,通过自动和人工评估,Octet方法优于最新的方法。值得注意的是,Octet丰富了生产中的在线目录分类法,使其在开放世界评估中的规模增加了2倍。
成为VIP会员查看完整内容

相关内容

分类学是分类的实践和科学。Wikipedia类别说明了一种分类法,可以通过自动方式提取Wikipedia类别的完整分类法。截至2009年,已经证明,可以使用人工构建的分类法(例如像WordNet这样的计算词典的分类法)来改进和重组Wikipedia类别分类法。
从广义上讲,分类法还适用于除父子层次结构以外的关系方案,例如网络结构。然后分类法可能包括有多父母的单身孩子,例如,“汽车”可能与父母双方一起出现“车辆”和“钢结构”;但是对某些人而言,这仅意味着“汽车”是几种不同分类法的一部分。分类法也可能只是将事物组织成组,或者是按字母顺序排列的列表;但是在这里,术语词汇更合适。在知识管理中的当前用法中,分类法被认为比本体论窄,因为本体论应用了各种各样的关系类型。
在数学上,分层分类法是给定对象集的分类树结构。该结构的顶部是适用于所有对象的单个分类,即根节点。此根下的节点是更具体的分类,适用于总分类对象集的子集。推理的进展从一般到更具体。
专知会员服务
69+阅读 · 2020年6月19日
Arxiv
5+阅读 · 2019年3月19日


相关VIP内容
专知会员服务
69+阅读 · 2020年6月19日
相关资讯
相关论文
Arxiv
5+阅读 · 2019年3月19日