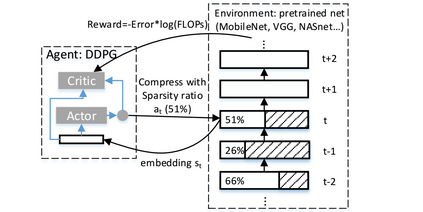
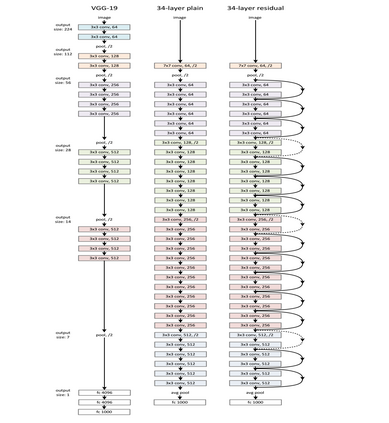
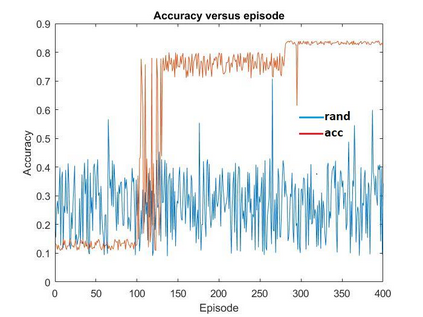
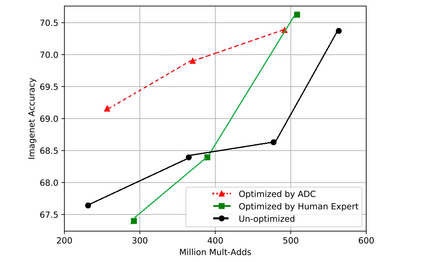
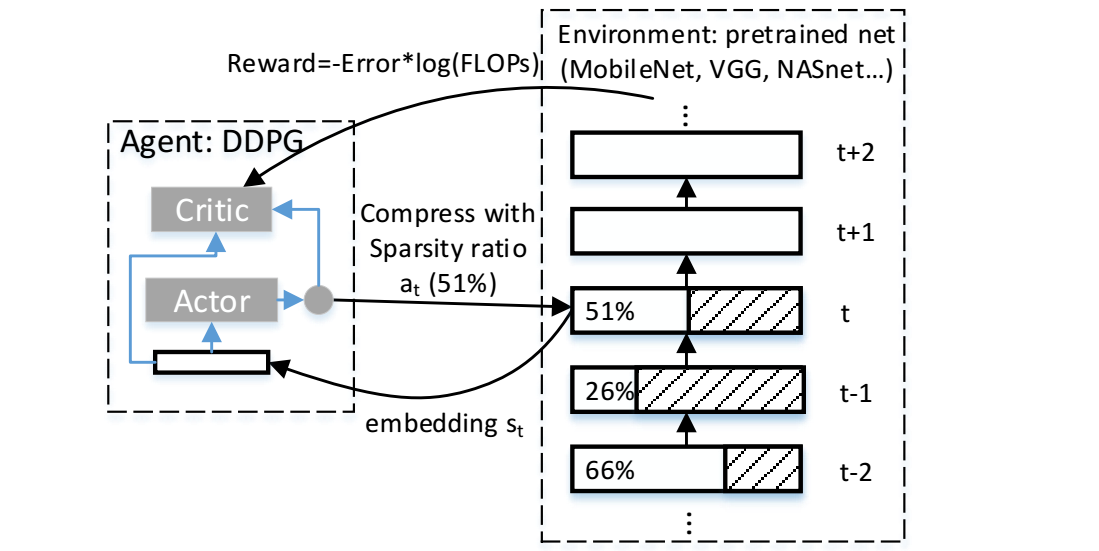
Model-based compression is an effective, facilitating, and expanded model of neural network models with limited computing and low power. However, conventional models of compression techniques utilize crafted features [2,3,12] and explore specialized areas for exploration and design of large spaces in terms of size, speed, and accuracy, which usually have returns Less and time is up. This paper will effectively analyze deep auto compression (ADC) and reinforcement learning strength in an effective sample and space design, and improve the compression quality of the model. The results of compression of the advanced model are obtained without any human effort and in a completely automated way. With a 4- fold reduction in FLOP, the accuracy of 2.8% is higher than the manual compression model for VGG-16 in ImageNet.
翻译:以模型为基础的压缩是一种有效、便利和扩展的神经网络模型,其计算有限和功率低。然而,传统的压缩技术模型利用精心设计的特征[2,3,12],并探索在大小、速度和准确性方面探索和设计大空间的专门领域,这些区域通常具有回数、速度和准确性,通常具有回数、速度和时间,本文将有效分析深自动压缩(ADC)和在有效的抽样和空间设计中加强学习强度,并改进模型的压缩质量。先进模型的压缩结果是在没有人的努力和完全自动化的情况下取得的。随着FLOP的四倍削减,2.8%的准确性将高于图像网中VGG-16的人工压缩模型。