
基于Transformers 从序列到序列的角度重新思考语义分割
Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
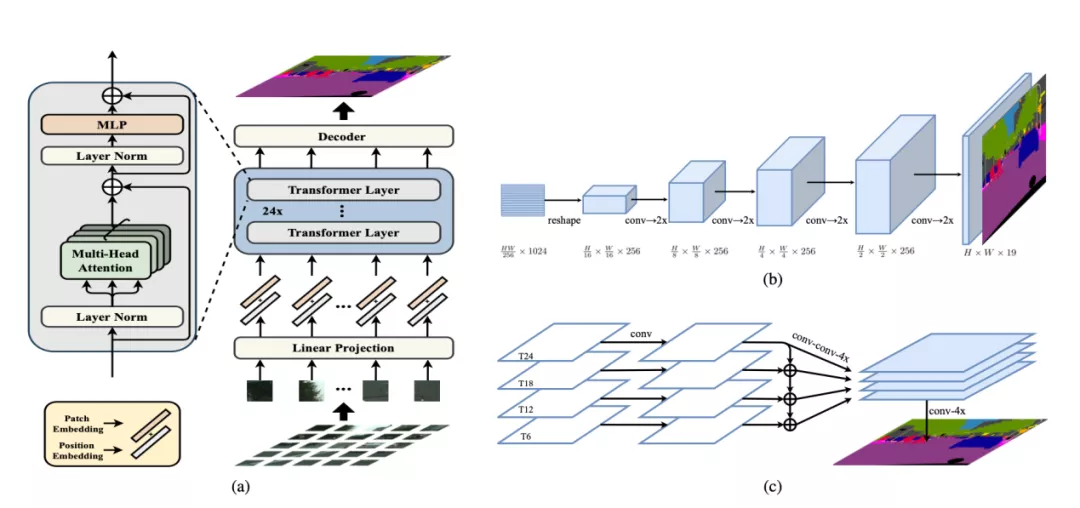
我们希望为语义分割方法提供另一种思路,将语义分割转变为序列到序列的预测任务。在本文中,我们使用transformer(不使用卷积和降低分辨率)将图像编码为一系列patch序列。transformer的每一层都进行了全局的上下文建模,结合常规的Decoder模块,我们得到了一个强大的语义分割模型,称之为Segmentation transformer(SETR)。大量实验表明,SETR在ADE20K(50.28%mIoU),Pascal Context(55.83%mIoU)上达到SOTA,并在Cityscapes上取得了较好结果。
成为VIP会员查看完整内容
相关内容

Transformer是谷歌发表的论文《Attention Is All You Need》提出一种完全基于Attention的翻译架构
Arxiv
10+阅读 · 2020年12月31日
Arxiv
9+阅读 · 2018年9月17日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
10+阅读 · 2020年12月31日
Arxiv
9+阅读 · 2018年9月17日