本文将简单介绍 2 篇快手发表在 AAAI 2020 上的论文,其中一篇是关于图像美学评估,另一篇则是关于如何找出精彩片段中的目标集和聚焦点。
Revisiting Image Aesthetic Assessment via
Self-supervised Feature Learning
(通过自监督特征学习重新审视图像美学评估)
![]()
论文地址:https://arxiv.org/pdf/1911.11419.pdf
图像美学质量评估是计算机视觉领域中一个重要研究课题。
近年来,研究者们提出了很多有效的方法,在美学评估问题上取得了很大进展。
这些方法基本上都依赖于大规模的、与视觉美学相关的图像标签或属性,但这些信息往往需要耗费巨大人力成本进行标注。
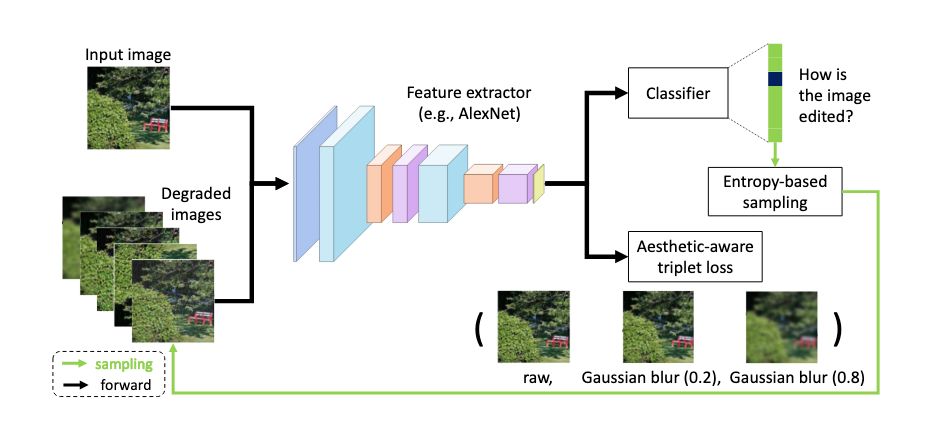
为了能够降低人工标注的成本,“使用自监督学习来学习具有美学表达力的视觉表征”是一个具有研究价值的方向。
![]()
在这篇论文中,我们在这个方向上提出了一种简单且有效的自监督学习方法。
我们方法的核心动机是:
若一个表征空间不能鉴别不同的图像编辑操作所带来的美学质量的变化,那么这个表征空间也不适合图像美学质量评估任务。
从这个动机出发,我们提出了两种不同的自监督学习任务:
一个用来要求模型识别出运用在输入图像上的编辑操作的类型;
另一个要求模型区分同一类操作在不同控制参数下所产生的美学质量变动的差异,以此来进一步优化视觉表征空间。
为了对比实验的需要,我们将提出的方法与现有的经典自监督学习方法(如,Colorization,Split-brain,RotNet等)进行比较。
实验结果表明:
在三个公开的美学评估数据集上(即,AVA,AADB,和CUHK-PQ),我们的方法都能取得具有竞争力的性能。
而且值得注意的是,我们的方法能够优于直接使用ImageNet或者Places数据集的标签来学习表征的方法。
此外,我们还验证了,在 AVA 数据集上,基于我们方法的模型,能够在不使用ImageNet数据集的标签的情况下,取得与最佳方法相当的性能。
Find Objects and Focus onHighlights: Mining Object Semantics for Video Highlight Detection viaGraph Neural Networks(找出精彩片段中的目标集和聚焦点:
利用图神经网络来挖掘目标语义信息的视频精彩片段检测)
![]()
论文链接:https://pan.baidu.com/s/1MHCSRXi75ED_2mr4HqcEBA
随着视频应用的迸发,用户每天都会接触到大量的视频,浏览整个视频费时又乏味。
视频精彩片段检测提取了能将视频的精华,从而很大地程度上缓解这种情况。
现有视频精彩片段检测方法存在两个问题。
首先,大多数现有方法仅专注于学习视频的整体视觉表示,但忽略了视频中物体及其交互对精彩部分的影响。
其次,当前最好的方法通常采用成对排序损失的策略,没有使用全局信息。
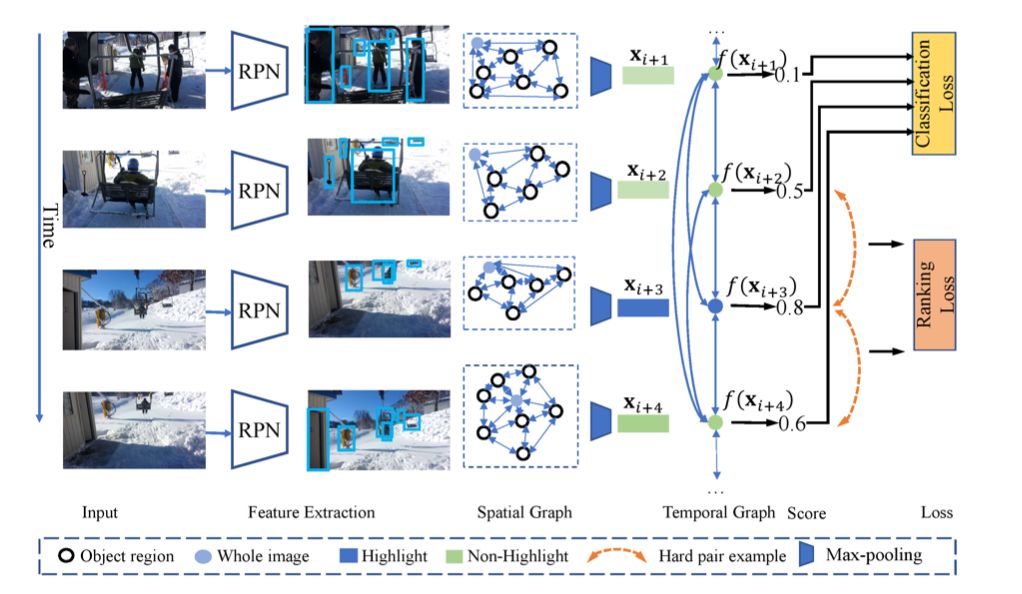
因此,我们提出了一个新颖的视频精彩部分框架,名为VH-GNN,构造一个对象感知图并从全局建模对象之间的关系。
![]()
为了降低计算成本,我们将视频建模成两种类型的图:
空间图,用于捕获每一帧中物体的复杂相互作用。
时间图: 获得每个帧的物体信息表示并捕获全局信息。
在此基础上,我们设计了图神经网络操作来学习视频片段的表示及它们之间的关系。
此外,我们提出了多阶段损失来优化模型,在第一阶段,我们计算了每个视频片段的得分,并使用分类损失优化;然后,根据前一阶段的得分得到难分样本对,再使用成对排序损失对模型进行优化。
我们在两个公开数据集上进行了实验,结果表明我们的方法与最好方法相比,有显著的提升。
更多AAAI 2020信息,将在「AAAI 2020 交流群」中进行,加群方式:
添加AI研习社顶会小助手(AIyanxishe2),备注「AAAI」,邀请入群。
![]()
AAAI 2020 论文解读系列:
![]()
![]()
![]()
![]() 点击“阅读原文” 前往 AAAI 2020 专题页
点击“阅读原文” 前往 AAAI 2020 专题页