
欢迎向本公众号投稿文献解读类原创文章,投稿邮箱:380198025@qq.com,请将稿件以附件形式发送。海内外招生、访学、招聘等稿件,请联系微信:xiongzhankun1997。 作者 | 李梦露 审核 | 刘 旋

今天给大家分享一篇浙江大学陈华钧教授,范骁辉教授,张强研究员课题组合作发表在Nature Machine Intelligence上的论文:“Knowledge graph-enhanced molecular contrastive learning with functional prompt”。作者提出了一种通过结合化学领域知识来增强分子性质预测任务的新方法KANO,以面向元素的知识图谱为先验,设计了在基于对比的预训练中的元素引导图增强,在微调中学习功能提示,以唤起预训练模型获得的下游任务相关知识。大量实验表明KANO的有效性,并为其预测提供了化学合理的解释。
摘要
深度学习模型可以准确地预测分子性质,并有助于更快、更有效地寻找潜在的候选药物。许多现有的方法纯粹是数据驱动的,专注于探索分子的内在拓扑和构造规则,没有任何化学先验信息。高度的数据依赖性使它们难以推广到更广泛的化学空间,并导致预测缺乏可解释性。为了解决这一问题,作者引入了一个面向化学元素的知识图谱(KG)来总结元素及其密切相关的官能团的基本知识。提出了一种基于功能提示的知识图增强分子对比学习方法(KANO),在预训练和微调中利用外部基础领域知识。具体而言,以面向元素的知识图谱为先验,首先设计了在基于对比的预训练中的元素引导图增强,在不违反分子语义的情况下探索微观原子关联。然后,在微调中学习功能提示,以唤起预训练模型获得的下游任务相关知识。广泛的实验表明,KANO在14个分子性质预测数据集上优于最先进的基线,并为其预测提供了化学合理的解释。这项工作通过提供高质量的知识先验,可解释的分子表示和优越的预测性能,有助于更有效的药物设计。
方法
KANO概述
作者提出的基于功能提示的分子对比学习方法KANO由三个主要部分组成:(1)ElementKG的构建和表示,(2)基于对比的预训练,(3)提示增强的微调。概述图如下。
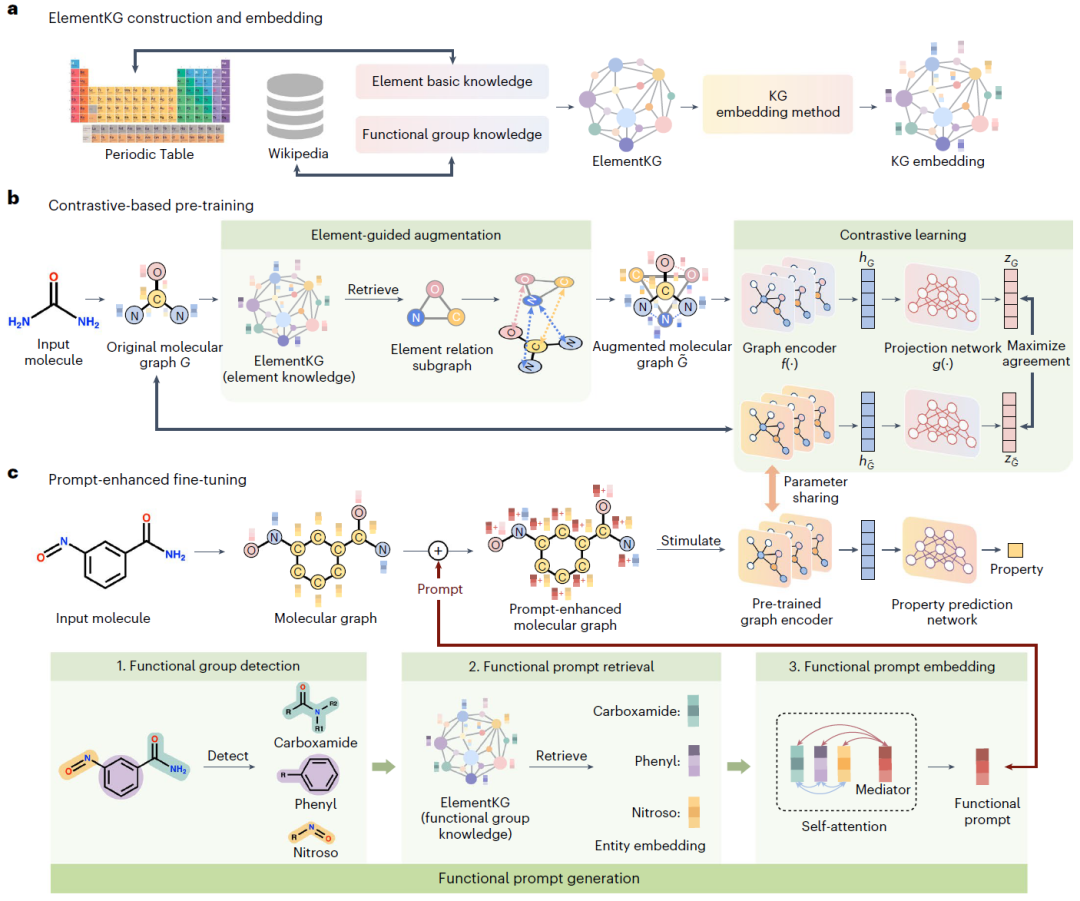
ElementKG的构建和表示

上图为ElementKG的简要介绍,它由两个级别组成:实例级和类级,分别用红色和蓝色表示。在实例级,化学元素和官能团表示为ElementKG中的实体,用红色块表示。为了记录每个元素的各种化学属性和每个官能团的组成,作者应用数据属性,将文字数据类型值附加到实体上。虚线块表示其上方红色块中实体的数据属性。此外,如红色箭头所示,通过对象属性建立实体之间的关联,例如元素之间的化学属性关系以及元素与官能团之间的包含关系。然后,根据它们的共性对所有实体进行分类,从而得到ElementKG的类级别。实体通过rdf:type分配给相应的类,用黑色虚线箭头表示。蓝色块表示不同的类,而蓝色箭头则反映了它们之间的包含(rdfs:subClassOf)或不连接(owl:disjointWith)。特别是,类之间的subClassOf关系形成了类层次结构,它是ElementKG的主干。具体构造过程如下:首先,从收集到的元素和官能团的知识中提取类层次结构。比如类ReactiveNonmetals和类Nonmetals之间的rdfs:subClassOf构造意味着ReactiveNonmetals中的实体集是Nonmetals中实体的子集。此外,Ester类中的每个实体都是其父类GroupContainingOxygen的成员。需要注意的是,子类关系是可传递的,这意味着ReactiveNonmetals类也是Element类的子类。然而,由于字面名称可能不足以区分不同的类,因此作者为类定义了不相交性,并使用owl:disjointWith添加了不相交性公理(disjointness axioms)。例如,Metals类和Nonmetals类之间的不相交表明Metals类中的元素实体不能同时是Nonmetals类的成员。使用类层次结构,通过rdf:type为每个类分配相应的实体,红色块中的C和O元素都是ReactiveNonmetals类的成员。其次,作者编译来自元素周期表的化学属性列表,并将它们作为数据属性分配给每个实体。每个元素都有超过15个数据属性,包括hasName、hasAtomic、hasDensity和hasIonization。另一方面,对于官能团,记录它们包含的键的类型。例如,Carboxyl的hasBondType包含单键和双键。第三,作者使用对象属性(红色方向箭头)对ElementKG中实体之间的关系进行建模。为了实现这一点,作者离散元素的连续化学属性值,并将它们用作对象属性,以将元素实体彼此连接起来。例如,三元组(C,inRadiusGroup1,O)表示实体C和实体O都在RadiusGroup1中,而(C,hasStateGas,O)表示它们都处于气态。作者为这些对象属性添加对称特征,这意味着(O,hasStateGas,C)在给定(C,hasStateGas,O)时也成立。由于ElementKG主要是面向元素的,不直接向官能团添加对象属性。相反,作者通过isPartOf对象属性在元素和官能团实体之间建立连接,这表明元素参与了官能团的形成。
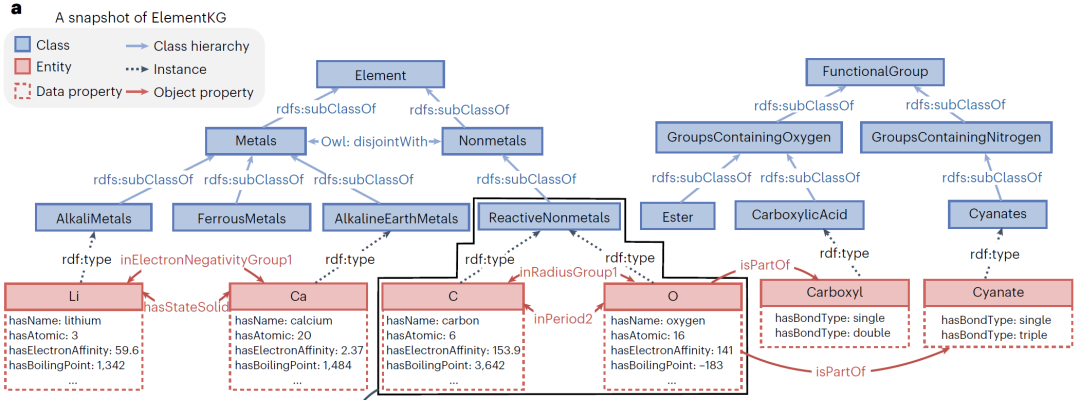
为了充分挖掘ElementKG中所有实体、关系和其他组件的结构和语义信息,获得有意义的表示,作者采用了基于OWL2Vec*的KG嵌入方法。如上图所示,该方法包括两个步骤:(1)从ElementKG中提取语料库,包括结构文档、词汇文档和组合文档;(2)在语料库上训练语言模型,以获得高质量的KG嵌入。结构文档通过计算每个目标实体的随机游走并将遍历的关系和实体组合成句子来捕获图结构和逻辑构造器。例如,从元素C开始的深度为3的随机漫步将产生以下句子(C,inRadiusGroup1,O,rdf:type,ReactiveNonmetals)。词汇文档包括从结构文档解析的句子。例如,上面的句子可以解析为('C','in','radius','group1','O','type','reactive','nonmetals')。为了建立实体及其字面名称之间的对应关系,作者将词汇文档中的每个单词替换为结构文档中的相应实体,从而生成组合文档。也就是说,上面的例子可以转换成一组句子:('C','in','radius','group1','O','type','reactive','nonmetals'), ('C','inRadiusGroup1','O','type','reactive','nonmetals')等等。将这三个文档合并为一个文档,然后使用该文档训练具有skip-gram架构的word2vec模型。最后,在ElementKG中获得每个实体和关系的嵌入,将其用于增强分子图的输入特征初始化和功能提示生成。
对比学习框架
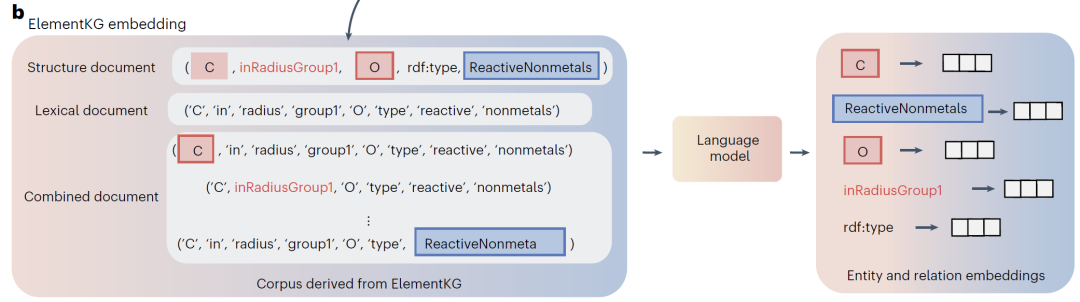
在获得ElementKG及其嵌入后,作者的目标是将其纳入预训练中,以增强模型对基础领域知识的理解。作者使用ElementKG中的基本元素知识,采用对比学习方法在大量未标记分子上预训练图编码器(具体内容在下面介绍)。用于创建正对的对比学习的传统图增强技术通常涉及删除节点或扰动边,这可能违反分子内的化学语义。为了解决这个问题并在原子之间建立更有意义的联系,作者提出了一种元素引导图增强方法来构建对比学习中的正对。如下图所示,首先识别给定分子中存在的元素类型,并从ElementKG中检索它们相应的实体和关系。这形成了一个元素关系子图,该子图使用元素的关联实体和关系来描述元素之间的关系。将子图中的元素实体节点连接到原始分子图中相应的原子节点,以创建一个增强的分子图,该分子图集成了基本的领域知识,并捕获了共享相同元素类型的原子之间的基本关联,即使它们没有直接通过化学键连接。这种方法保留了拓扑结构,同时结合了重要的化学语义。在此基础上,作者采用对比学习框架通过最大化原始分子图和增广分子图之间的一致性来训练图编码器,而不会在增广图中不加区分地嵌入元素知识。
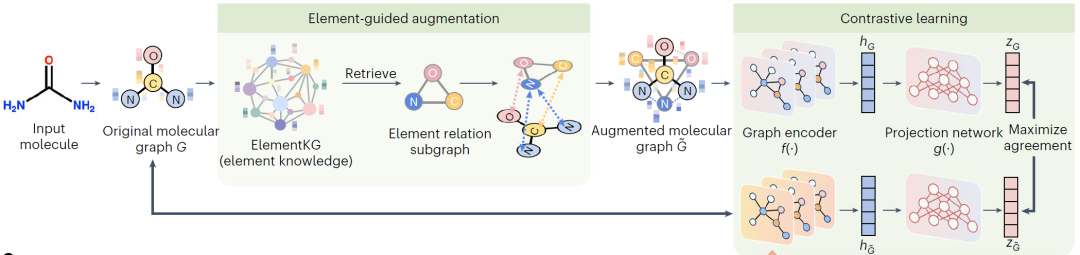
给定大小为N的小批量,作者将N个原始分子图转换为N个增广分子图,生成2N个图。原始分子图及其增广图构成正对,和构成负对。在使用图编码器捕获图表示后,非线性变换将原始和增广的图表示映射到隐空间,在隐空间中计算对比损失。采用两层感知器(MLP)来进行投影,然后使用normalized temperature-scaled cross-entropy (NT-Xent)损失函数来训练图编码器,以最大化正对之间的一致性和负对之间的差异。正对之间损失函数定义为:
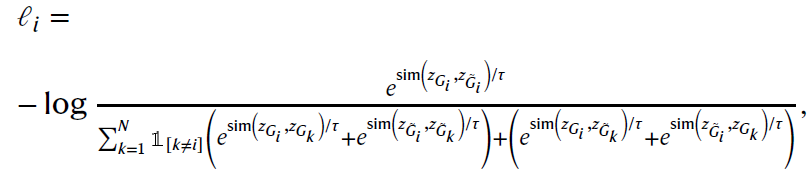
其中sim()表示余弦相似性,是温度影响参数,是潜在表示。对比损失的分子衡量正对之间的一致性,而分母计算每个图与其他2N−1个图之间一致性的总和。这意味着原始图的潜在表示不仅要考虑与其他原始图潜在向量的相似度,而且要考虑与所有增广图的相似度。增广图的潜在表示也遵循相同的计算过程。最后,计算minibatch中所有正对的损失。
提示生成器
预训练后,分子图编码器需要微调下游性质预测。具体来说,输入的分子图被送入预训练的图编码器,以提取嵌入图的,然后将其送入预测器以输出预测值。为了弥合预训练对比任务和下游任务之间的差距,作者建议使用官能团知识作为提示来刺激预训练的图编码器。如下图所示,从ElementKG的官能团知识中生成功能提示。首先,检测输入分子中的所有官能团,检索其在ElementKG中的相应实体嵌入,并构建具有可学习嵌入的中介,以捕获每个官能团的重要性。然后,将自注意力机制应用于中介(红色)的嵌入和官能团实体的嵌入,以全面聚合其语义并获得功能提示。功能提示生成如下:
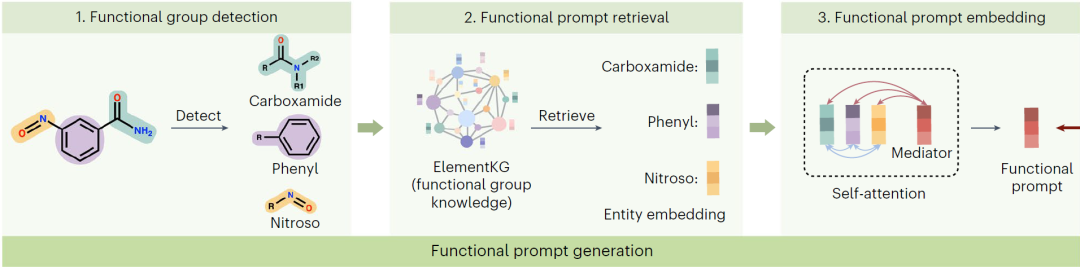
为了刺激预训练模型回忆之前所学的相关知识,作者设计了一个提示生成器,基于ElementKG和输入的分子图生成提示,即。作者使用RDKit检测中包含的所有官能团,并根据名称在ElementKG中检索相应的官能团实体。然后使用KG嵌入方法得到官能团实体的嵌入,其中m为检测到的官能团个数。为了捕捉官能团的重要性,作者构建了一个可学习向量作为中介(记为),然后在中介和官能团的嵌入上应用自注意力机制。具体来说,输入的首先被投影到查询/键/值向量中:
其中,d是隐层维度。输出嵌入计算为:
作者执行了两层自注意力层,得到了中介的嵌入,它反映了不同重要程度的官能团的综合贡献。然后将其输入到一个全连接层中,并进行层规范化以获得功能提示:
最后,作者将添加到中每个原子节点的原始表示中,并具有可学习的尺度参数,从而得到中节点的新输入特征表示为。然后,将这个提示增强的分子图输入到预训练的图编码器和预测器中进行分子性质预测。

图编码器架构
分子图可以表示为,其中,表示一组节点,表示一组边。每条边都是双向的。设表示节点的初始特征,表示边的初始特征。特别是,对于原始分子图中的原子和键,作者根据特定的化学规则为它们提取不同的初始特征。比如对于增广图,作者将上述得到的元素实体嵌入作为元素节点的初始特征。通过对ElementKG中相应元素实体之间的多个关系的嵌入进行平均池化,得到每两个元素节点之间的一条边的初始特征。按照原始分子图中相同的特征提取方法,得到原子和键的初始特征。元素与原子之间的边用不同的随机初始化特征来区分,即相同颜色的虚线表示相同的初始特征,不同颜色表示不同的表示。给定图结构、节点特征和边特征,旨在学习一个图编码器,它将输入图映射到向量表示。本文,作者将CMPNN作为图编码器,通过加强边和节点之间的消息交互来改进图嵌入。首先,为了更新节点的隐藏状态,每个节点聚集其传入边的表示,而不是其邻近节点。中间消息向量为:
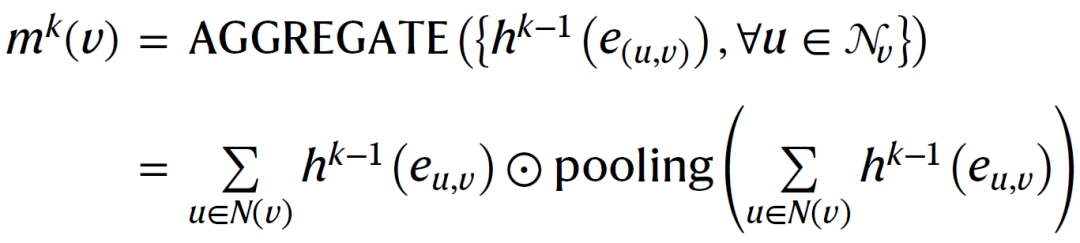
其中表示消息传递的当前深度,是元素乘法运算符。这里作者应用最大池化来突出显示具有最高信息强度的边,因为节点的隐藏状态主要基于来自传入边的最强消息。然后,将节点当前的隐藏状态与消息向量连接,并通过一个通信函数 (communicative function)来更新节点的隐藏状态:

其中隐藏状态充当消息中转站,接收传入消息,将其整合并发送到下一站。具体的通信功能是通过将节点和边特征输入到MLP中,然后进行ReLU激活来实现的。其次,作者通过从中减去其逆边(inverse edge)信息来提取边的信息:
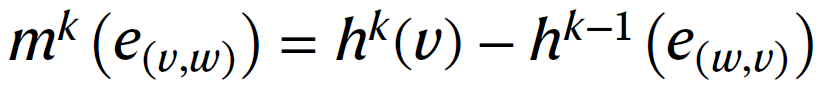
其中是的逆边。为了更新边的隐藏状态,首先将边中间消息与初始边特征输入到一个全连接层中。将ReLU激活函数应用于输出,并将其用作下一次迭代的中间消息向量。这个过程可以用数学表达式表示为: 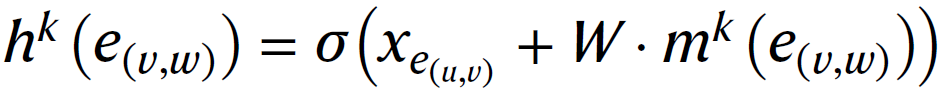
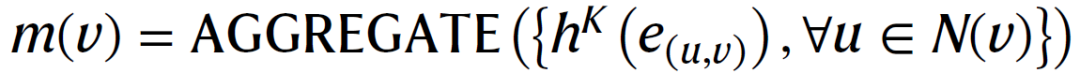

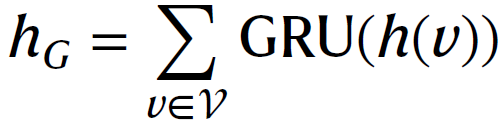
实验设置
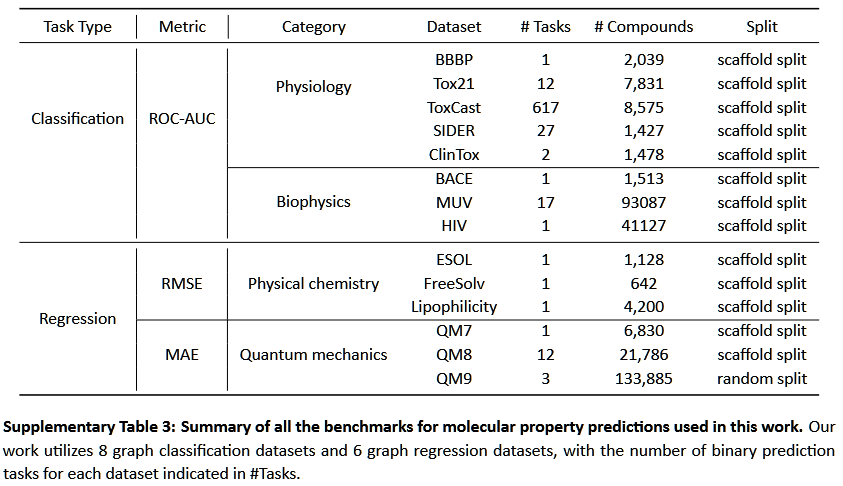
在预训练阶段,作者使用从ZINC15取样的250,000个未标记分子对KANO进行预训练。在微调阶段,作者使用了来自MoleculeNet的14个基准数据集,包括678个二元分类任务和19个回归任务。这些数据集涵盖了广泛的分子数据,如药物、生物、物理和化学。
结果
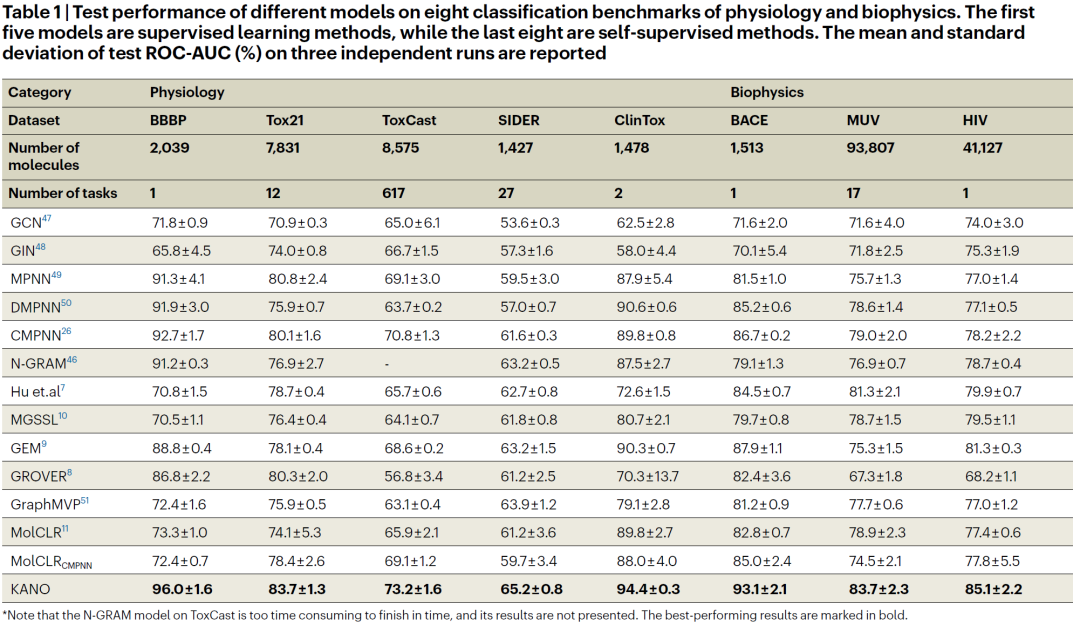
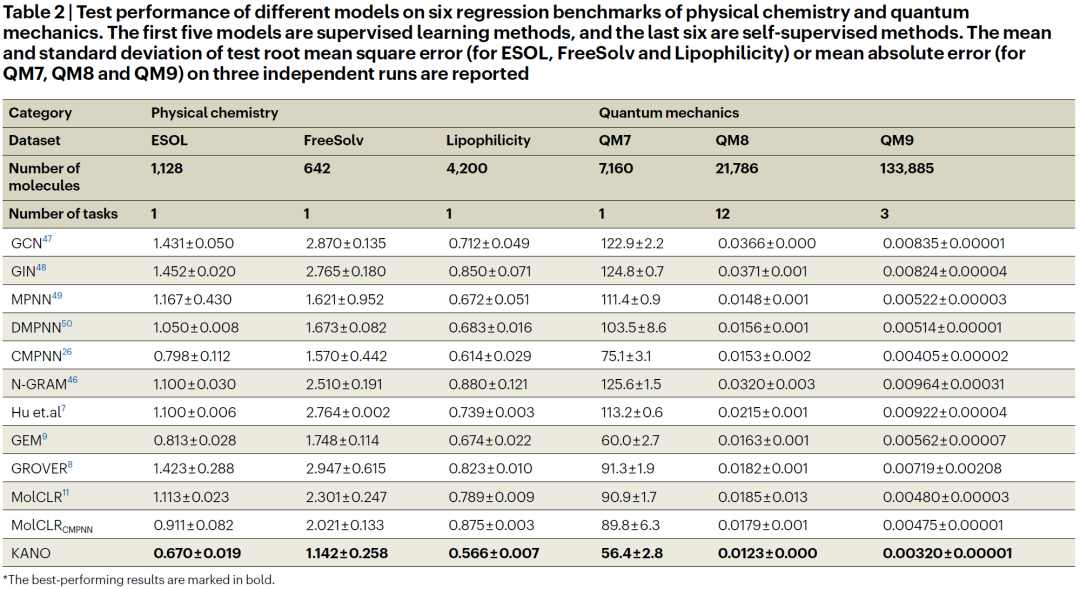
KANO提高了性质预测的性能
为了评估KANO的有效性,作者在四类数据集上评估了它的性能。表1和表2给出了各种方法的结果。#Molecules表示每个数据集中分子的数量,#Tasks表示每个数据集中二元预测任务的数量。表1报告了分类任务中AUC结果。主要观察结果包括:(1)KANO在所有8个数据集上的表现均优于其他方法,显著提高了3.79%,显示了其有效性。(2) KANO在Tox21、ToxCast、SIDER和MUV等多任务学习数据集上表现良好。特别是,KANO在具有617个二元分类任务的ToxCast数据集上实现了3.39%的改进。鲁棒性表明其表示涵盖了不同的分子语义。表2给出了回归任务的测试性能。主要观察结果如下:(1) KANO在监督和自监督模型中得分最高,在所有六个回归任务上都比之前的方法相对提高了15.8%。(2) KANO精细的化学理解帮助它在量子力学数据集上取得了显著的准确性,甚至超过了包含额外3D信息的模型。(3) KANO极大地帮助了标签信息有限的任务,在分别只有1128和642个标记分子的小数据集ESOL和FreeSolv上平均提高了21.7%。总之,KANO在所有基准测试中都优于其他模型,证明了将ElementKG集成到预训练和微调阶段的有效性。KANO不仅优于其他SSL方法,而且还展示了其优于监督方法的优势,为推广到更广泛的化学领域提供了竞争优势。
KG中更丰富的知识导致更健壮的表示
ElementKG在KANO框架中是必不可少的,因为它指导分子增强和功能提示生成。为了确定其各个组件的贡献,作者使用不同的KG组件(如类层次结构、数据属性和官能团知识)来评估KANO的性能。作者只在预训练期间修剪ElementKG的组件,并保持微调的实验设置与原始KANO方法一致。下图a显示:(1)具有完整ElementKG架构的KANO (complete ElementKG)在所有数据集上优于其他变体,突出了每个组件的不可或缺性。(2)去除类层次结构 (w/o class hierarchy)会导致性能下降,强调类划分和子类之间的传递关系在提炼和转移基础领域知识方面的重要性。(3) ElementKG中不包含官能团 (w/o functional group)会导致性能明显下降,凸显了官能团的关键作用。(4)排除实体的数据属性 (w/o data properties)几乎总是表现最差,强调化学属性的重要性。
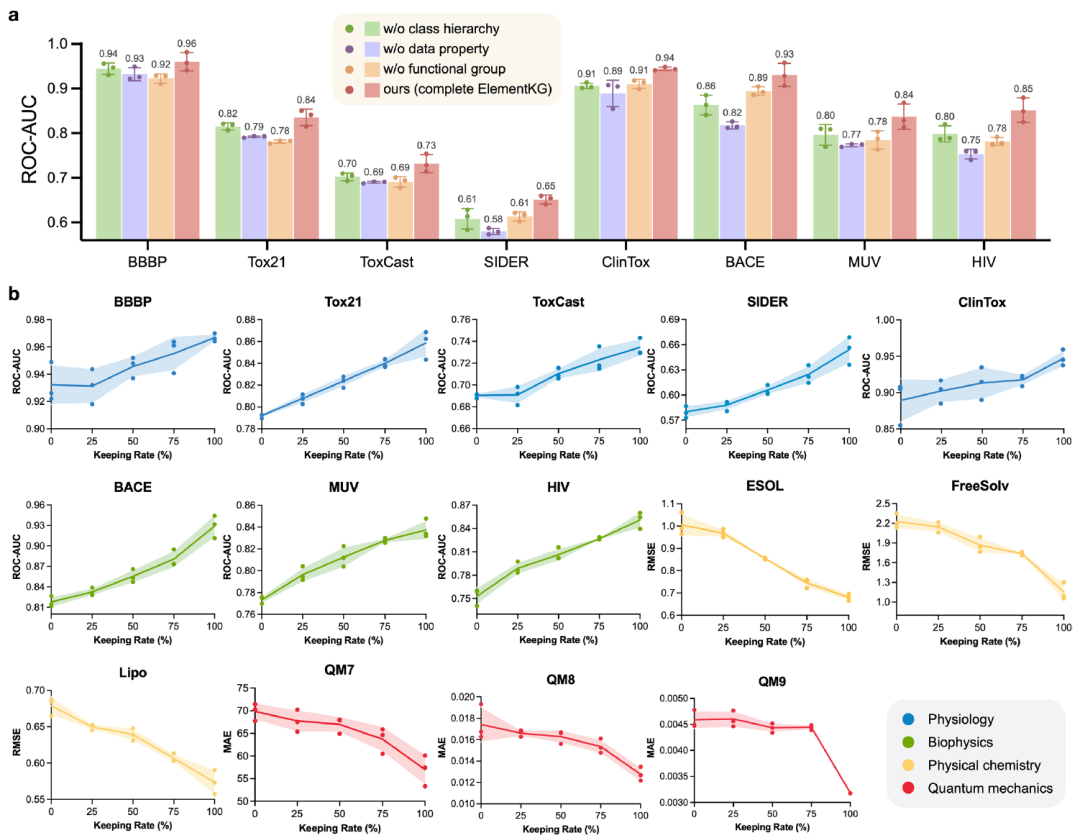
为了进一步研究数据属性的影响(每个元素包含超过15个),作者屏蔽了其中的一定比例,并报告了四类任务的测试性能。上图b显示了测试结果。值得注意的是,随着保留属性比例的增加,模型的性能不断提高,验证了更丰富的数据属性提供了更全面的基础知识,从而能够学习更健壮的分子表示。
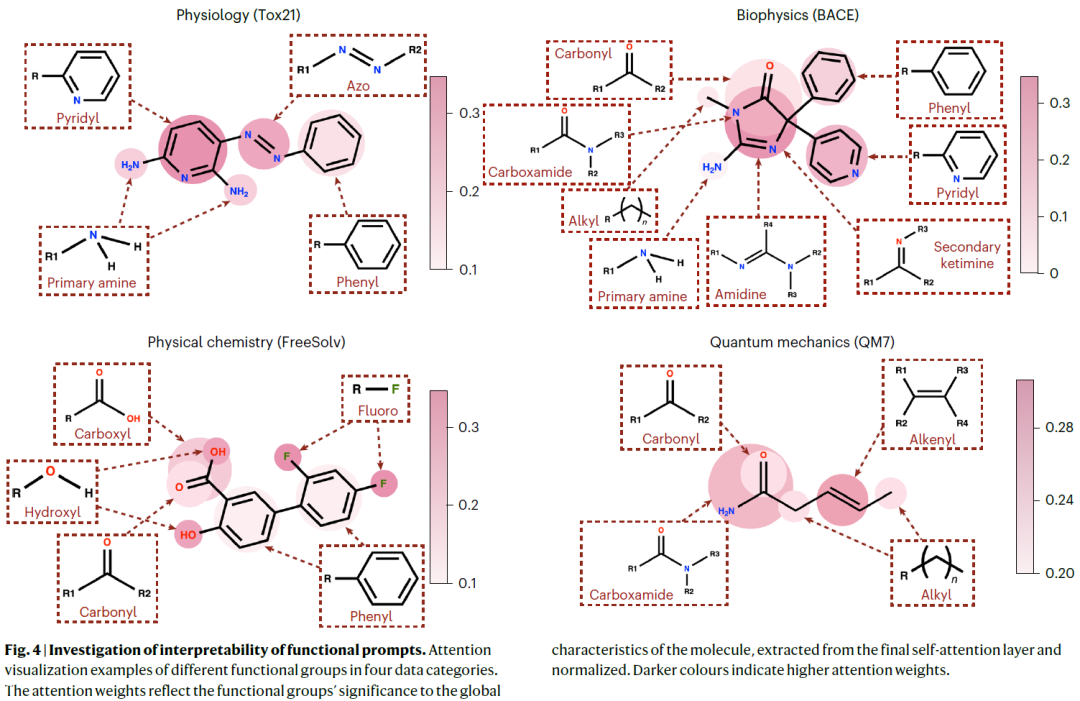
功能提示能够提供可解释的预测
由于功能提示作为预训练对比任务和下游分子特性预测任务之间的桥梁,作者对它们提供特定领域可解释性的潜力很感兴趣。从图4的四个性质类别中可视化了分子图中官能团的注意权重。(1)第一个例子来自Tox21公共数据库,该数据库测量化合物的毒性。观察到pyridyl和azo官能团的关注度较高,其次是primary amine。有趣的是,pyridyl和primary amine可以结合形成2,6-diaminopyridine,这是继发性肝毒素和皮肤致敏剂的主要成分。含azo化合物具有致癌性和诱变性,因此具有重要意义。(2)第二个例子是BACE-1抑制剂。该分子更关注amidine,carboxamide和secondary ketimine,它们构成imidazole成分。此外,pyridyl和phenyl也受到较多关注。这些发现与先前的研究一致,表明芳香杂环家族抑制BACE-1。(3)第三个例子来自FreeSolv,主要研究水中小分子的水化自由能。Fluoro和hydroxyl受到较高的关注,因为fluoro的较强电子获取能力和hydroxyl的亲水性,影响分子与水的相互作用力。此外,极性强的carboxyl得到更多的注意力权重。(4)最后一个分子来自QM7,记录了分子的原子化能。Alkenyl和carboxamide受到更多的关注,因为碳碳双键的键能更高,而酰胺键的稳定性也更高,需要更多的能量才能将它们分解成单独的原子。可解释性探索说明了功能提示如何通过从分子性质预测任务的角度调用相关功能群知识来弥合预训练任务和下游任务之间的差距。
结论
在这项研究中,作者提出了KANO,一种通过结合化学领域知识来增强分子性质预测任务的新方法。通过利用ElementKG, KANO在14个分子基准上取得了卓越的性能。KG引导的预训练允许KANO获得高质量的分子表示空间,而功能提示捕获与下游任务相关的有意义的化学子结构。虽然KANO表现出了良好的性能,但仍有一些局限性。例如,ElementKG可能无法完全捕获分子系统的复杂性,并且当前的功能提示可能无法捕获子结构之间的远程相互作用。为了解决这些限制,作者提出了几个有趣的未来方向。首先,扩展ElementKG以涵盖化学的其他领域,并将其与其他现有的KG相结合,可以提供对分子系统更全面的理解。其次,研究KANO学习表示的可解释性和功能提示捕获的化学知识可以为分子设计和优化提供见解。最后,探索将KANO与其他技术相结合的可能性,以提高其在小数据集上的性能并加速药物发现,这可能是一个有希望的方向。
参考文献
文章链接:https://www.nature.com/articles/s42256-023-00654-0 代码链接:https://github.com/HICAI-ZJU/KANO

扫描二维码获取 更多精彩 AI in Graph本公众号主要介绍应用于图、知识图谱的人工智能算法和研究进展,及其在生物信息、医学健康领域的应用。欢迎关注本公众号获取领域最新文献解读。

点个在看+赞支持一下呗

