
主题: Safe and Fair Machine Learning
简介:
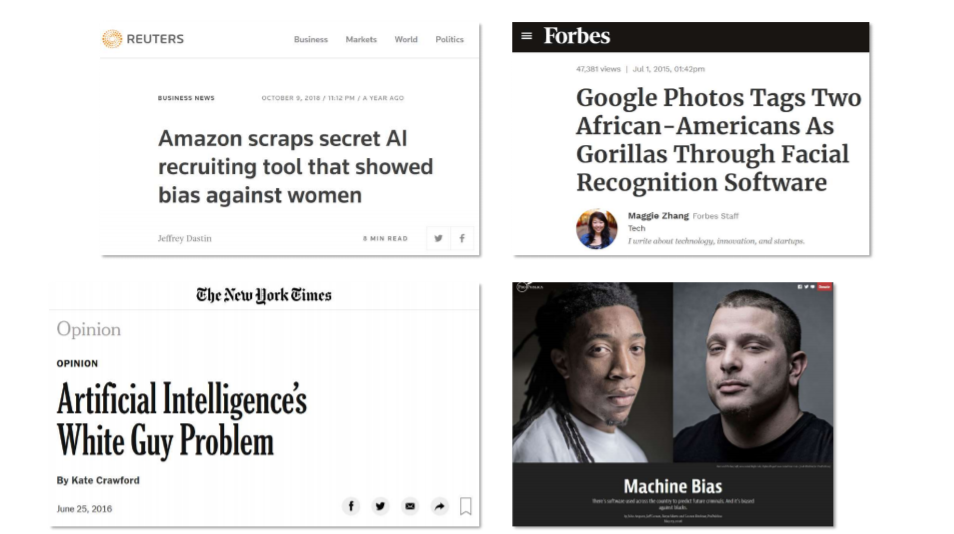
在这个演讲将讨论一些我们的未来的工作在一个新的框架设计的机器学习算法,内容包括:1)使得算法的用户更容易定义他们认为是不受欢迎的行为(例如,他们认为是不公平的,不安全,或者成本);2)提供了一个高信任度保证它不会产生一个解决方案,展示了用户定义的不受欢迎的行为。
作者简介:
Philip Thomas是马萨诸塞大学安姆斯特分校信息与计算机科学学院助理教授,自主学习实验室联合主任。之前是卡内基·梅隆大学(CMU)的博士后,2015年,在马萨诸塞州立大学阿默斯特分校(UMass Amherst)获得了计算机科学博士学位。主要研究如何确保人工智能(AI)系统的安全性,重点是确保机器学习(ML)算法的安全性和公平性以及创建安全和实用的强化学习(RL)算法。
成为VIP会员查看完整内容



相关内容

专知会员服务
13+阅读 · 2019年10月3日
Arxiv
3+阅读 · 2018年1月30日


相关VIP内容
专知会员服务
13+阅读 · 2019年10月3日
相关资讯
相关论文
Arxiv
3+阅读 · 2018年1月30日