DeepMind网红博士300页论文出炉:面向NLP的神经迁移学习(附下载)

新智元AI技术峰会今日开幕!
新智元于3月27日在北京泰富酒店举办“2019新智元AI技术峰会——智能云•芯世界”,聚焦智能云和AI芯片发展,重塑未来AI世界格局。
同时,新智元现场权威发布若干AI白皮书,聚焦产业链的创新活跃,助力中国在世界级的AI竞争中实现超越。
现场直播:
爱奇艺(全天):
https://live.iqiyi.com/s/19rsj6q75j.html
头条科技(上午):
m.365yg.com/i6672243313506044680/
头条科技(下午):
m.365yg.com/i6672570058826550030/
新智元推荐
来源:图灵 TOPIA(ID: turingtopia)
作者:Sebastian Ruder 编辑:刘静
【新智元导读】NLP领域知名博主Sebastian Ruder近日公开了他的博士论文,总共 329 页,他认为更明确的迁移学习是解决训练数据不足和提高自然语言处理模型下游性能的关键,并展示了支持该假设的相关领域、任务和语言迁移知识的实验结果。这篇论文是了解 NLP 迁移学习非常好的文献。
Sebastian Ruder 是 NLP 领域知名博主(ruder.io),近期他从爱尔兰国立大学博士毕业并加入了 DeepMind。
3 月 23 日,他的博士论文《面向自然语言处理的神经网络迁移学习》公开,总共 329 页。

Sebastian Ruder
在论文中,他认为更明确的迁移学习是解决训练数据不足和提高自然语言处理模型下游性能的关键,并展示了支持该假设的相关领域、任务和语言迁移知识的实验结果。这篇论文是了解 NLP 迁移学习非常好的文献。
当前,基于神经网络的自然语言处理模型擅长从大量标记数据中学习。鉴于这些功能,自然语言处理越来越多地应用于新任务、新领域和新语言。然而,当前的模型对噪声和对抗性示例敏感,并且易于过度拟合。这种脆弱性,加上注意力的成本,对监督学习范式提出了挑战。
迁移学习使得我们能够利用从相关数据中获取的知识,提高目标任务的性能。以预训练词表征形式进行的隐式迁移学习一直是自然语言处理中的常见组成部分。
本文认为, 更明确的迁移学习是解决训练数据不足和提高自然语言处理模型下游性能的关键。我们展示了支持该假设的相关领域、任务和语言转移知识的实验结果。
我们为自然语言处理的迁移学习做出了一些贡献:
首先,我们提出了新的方法来自动选择监督和无监督的领域适应的相关数据。
其次,我们提出了两种新的架构,改善了多任务学习中的共享,并将单任务学习提升到最先进的水平。
第三,我们分析了当前模型对无监督跨语言迁移的局限性,提出了一种改善方法,以及一种新的潜变量跨语言词嵌入模型。
最后,我们提出了一个基于微调语言模型的序列迁移学习框架,并分析了适应阶段。
1.1 动机
语言通常被认为是人类智力的标志。开发能够理解人类语言的系统是人工智能的主要障碍之一,该目标推动了人工智能,特别是自然语言处理和计算语言学研究。随着语言渗透到人类生存的每个方面,最终,自然语言处理是计算机在增强人类智能方面发挥其全部潜力所必需的技能。
早期针对这一难以捉摸的目标的象征性方法是试图利用人类编写的规则来捕捉文本的含义。然而,这种基于规则的系统很脆弱,并且仅限于它们为 [Winograd,1972] 设计的特定领域。它们通常无法处理意外或看不见的输入,最终被证明限制性太强,无法捕捉到自然语言的复杂性 [国家研究委员会和自动语言处理咨询委员会,1966 年]。
在过去 20 年中,自然语言处理的统计方法 [Manning 等人,1999 年] 已经变得司空见惯,它使用数学模型自动从数据中学习规则。因此,我们应该将人力投入到创建新的特征中去,用于指示模型在预测时应该考虑的数据中的连接和关系,而不是去编写规则。然而,特征工程非常耗时,因为这些特征通常是针对特定任务的,而且需要相关领域的专业知识。
在过去五年中,深度神经网络 [Krizhevsky 等人,2012 a, Goodfellow 等人,2016] 作为机器学习模型的一个特殊类别,已经成为从数据中学习的首选模型。这些模型通过对一个多层次特征结构的学习,减少了对特征工程的需求。因此,人力投入的重点集中于为每项任务确定最合适的架构和训练设置。
在自然语言处理以及机器学习的许多领域,训练模型的标准方法是对大量的示例进行注释,然后提供给模型,让其学习从输入映射到输出的函数。这被称为监督学习。对于每项任务,如分析文本的句法结构、消除单词歧义或翻译文档,都是从零开始训练新模型。来自相关任务或领域的知识永远不会被组合在一起,模型总是从随机初始化开始 tabula rasa。
这种从空白状态中去学习的方式与人类习得语言的方式截然不同。人类的语言学习并非孤立进行,而是发生在丰富的感官环境中。儿童通过与周围环境的互动 [Hayes 等人,2002 年],通过持续的反馈和强化 [Bruner, 1985 年] 来学习语言。
然而,最近基于深度神经网络的方法通过对从几十万到数百万对输入 - 输出组合 (如机器翻译) 的学习,在广泛的任务上取得了显著的成功 [Wu 等人,2016 年]。鉴于这些成功,人们可能会认为没有必要偏离监督学习的范式,因此没有必要创建受人类语言习得启发的算法。毕竟,大自然为我们提供的是灵感而非蓝图;例如,人工神经网络只是受到人类认知的松散启发 [Rumelhart 等人,1986 年]。
最近的研究 [Jia 和 Liang, 2017 年,Belinkov 和 Bisk, 2018 年] 表明,当前算法的脆弱程度与早期基于规则的系统类似:它们无法概括出其在训练期间看到的数据以外的东西。这些算法遵循它们训练的数据的特征,并且在条件发生变化时无法适应。
人类的需求是复杂的,语言是多种多样的;因此,不断有新的任务 - 从识别法律文件中的新先例,到挖掘看不见的药物间的相互作用,再到路由支持电子邮件等等,这些都需要使用自然语言处理来解决。
自然语言处理还有望帮助弥合造成网路信息和机会不平等的数字语言鸿沟。为实现这一目标,这些模型除英语之外,还需要适用于世界 6, 000 种语言。
为了获得一个在以前从未见过的数据上表现良好的模型(无论是来自新的任务,领域还是语言 ),监督学习需要为每个新的设置标记足够的示例。
鉴于现实世界中的语言、任务和域名过多,为每个设置手动注释示例是完全不可行的。因此,标准监督学习可能会由于这些现实挑战的存在而遭遇失败。
通过将知识从相关领域、任务和语言转移到目标设置,迁移学习将有望扭转这种失败。
事实上,迁移学习长期以来一直是许多 NLP 系统的潜在组成部分。NLP 中许多最基本的进步,如潜在语义分析 [Deerwester 等人,1990 年]、布朗聚类 [Brown 等人,1993b] 和预训练的单词嵌入 [Mikolov 等人,2013a] 均可被视为迁移学习的特殊形式,作为将知识从通用源任务转移到更专业的目标任务的手段。
在本文中,我们认为将 NLP 模型的训练定义为迁移学习而非监督学习,有助于释放新的潜力,使我们的模型能够得到更好的推广。我们证明我们的模型优于现有的迁移学习方法以及不迁移的模型。
为此,我们开发了针对各种场景跨域、任务和语言进行转换的新模型,并且证明了我们的模型在性能上比现有的迁移学习方法和非迁移的模型都要优越。
1.2 研究目标
本文研究了使用基于神经网络的自然语言处理方法在多个任务、领域和语言之间进行迁移的自动表征学习问题。
本文的主要假设如下:
自然语言处理中的深层神经网络会利用来自相关域、任务和语言的现有相关信息,其性能优于在各种任务中不使用此信息的模型。
换句话说,我们认为在大多数情况下,迁移学习优于监督学习,但有两点需要注意:
1. 当已经有足够数量的训练实例时,迁移学习可能没有那么大的帮助;
2. 如果没有相关信息,迁移学习可能就不那么有用了。
为了解决第一个方面,我们分析了迁移学习的几个功能。第二点暗示了本论文中反复出现的主题:迁移学习的成功取决于源的设置与目标设置的相似性。
总而言之,我们列出了五个需求,这些需求将通过本文提出的方法来解决:
1. 克服源设置和目标设置之间的差异:该方法应克服源设置和目标设置之间的差异。许多现有方法只有在源和目标设置相似时才能很好地工作。为了克服这一挑战,我们提出了方法用于:选择相关示例、利用弱监督、灵活地跨任务共享参数、学习通用表示和分析任务相似性。
2. 诱导归纳偏差:该模型应该诱导归纳偏差,从而提高其推广能力。我们采用的归纳偏差包括半监督学习、对正交约束的多任务学习、弱监督、匹配的先验关系、层次关系和预先训练过的表示。
3. 将传统方法和当前方法相结合:该模型应该从经典工作中汲取灵感,以便克服最先进方法中的局限性。我们提出了两种模型,明确地结合了两方面的优点,即传统方法优势和神经网络方法的优势。
4. 在 NLP 任务的层次结构中进行迁移:该方法应该在 NLP 任务的层次结构中迁移知识。这包括在低级别和高级别任务之间进行共享,在粗粒度和细粒度的情感任务之间进行共享,以及从通用任务迁移到各种各样的任务中。
5. 推广到多个设置:该方法应该能够推广到许多不同的设置之上。为了测试这一点,我们在多种任务、领域和语言中评估相关方法。
1.3 贡献
在本文中,我们将重点讨论 NLP 迁移学习的三个主要方面:跨领域迁移、跨任务迁移和跨语言迁移。
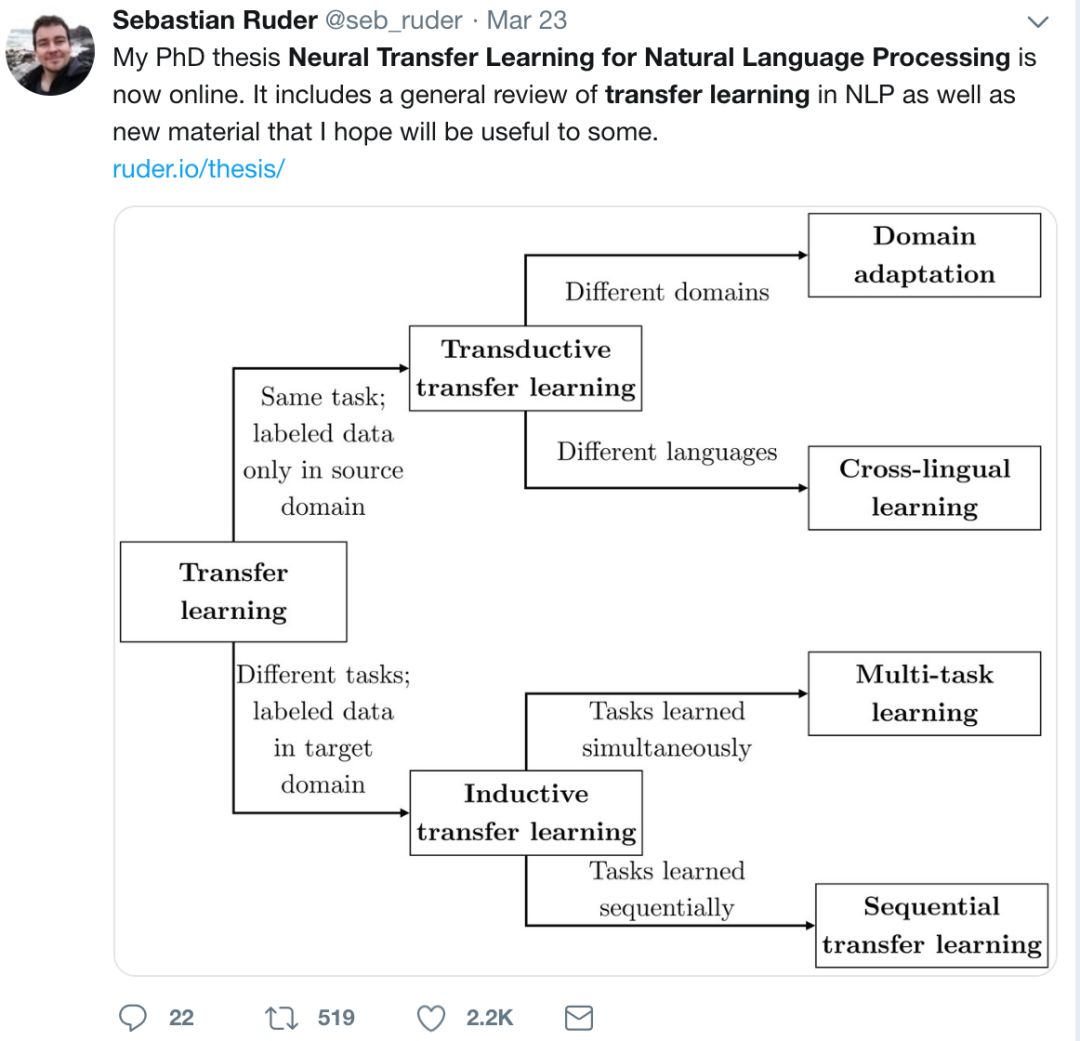
根据源和目标任务的性质、领域和学习顺序的不同,这三个维度可以自然地分为四个不同的迁移学习设置:领域适应、跨语言学习、多任务学习和序列迁移学习。我们在表 1.1 中展示了本文的贡献是如何与这四种设置相关联的。
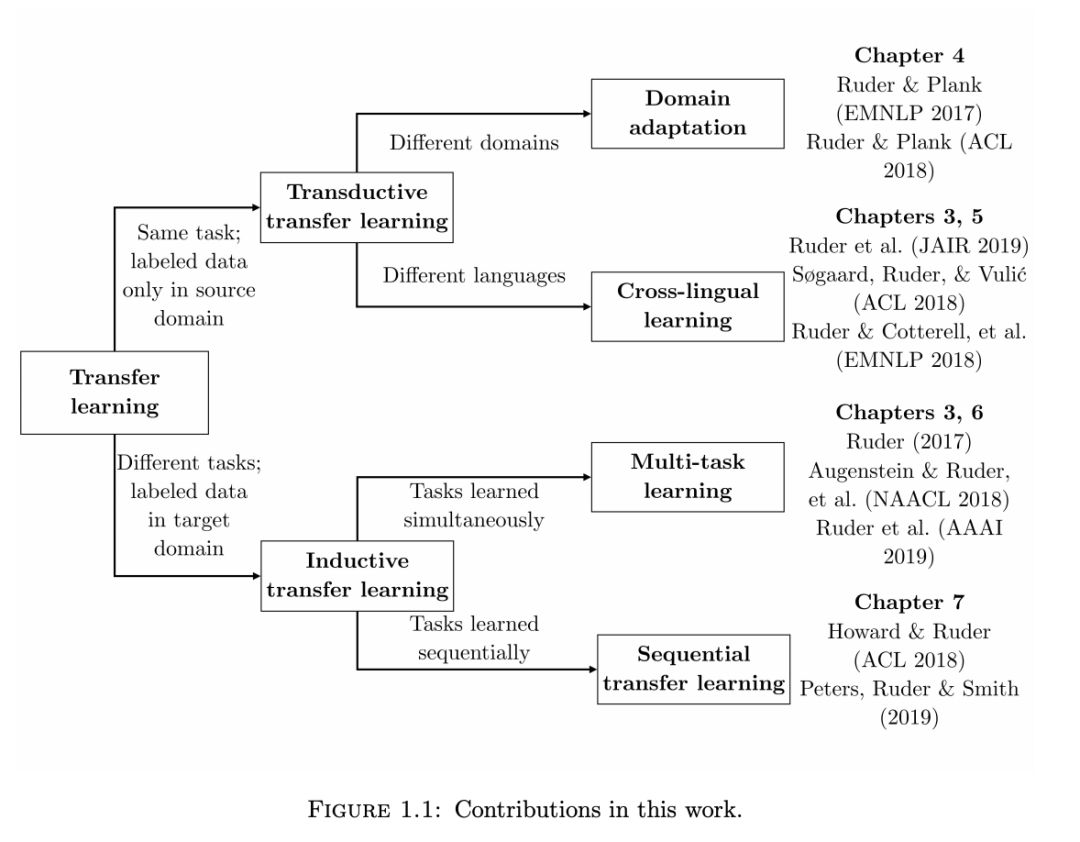
本论文的贡献可以分为理论、实践和实证三个方面。
在理论贡献方面:
我们提供了反映自然语言处理中最常见的迁移学习设置的分类方法;
我们展示了学习在单词级别上优化类似目标的跨语言词嵌入模型;
我们分析了无监督跨语言嵌入模型的理论局限性;
我们展示了如何将现有的跨语言嵌入方法视为一个潜变量模型;
我们提出了一个理论框架,将现有架构推广到多任务学习。
在实践贡献方面:
我们对自然语言处理中最常见的四种迁移学习设置进行了广泛的回顾:多任务学习、序列迁移学习、领域适应和跨语言学习;
我们提出了一种新的基于特征向量的度量方法,以衡量两种语言之间无监督双语词典归纳的可能性;
我们提供了适应预训练表征的指南;
我们开源了我们的代码。
我们最终做出以下实证贡献:
我们提出了一个模型,它自动学习如何选择与特定目标领域相关的训练实例;
我们将半监督学习方法与神经网络相结合,并将其与最先进的方法进行比较;
我们提出了一种受 tri-training 启发的更有效的半监督学习方法;
我们实证分析了无监督跨语言词嵌入模型的局限性;
我们提出了一个新的双语词典归纳的潜变量模型;
我们提出了一个新的多任务学习模型,可以自动学习在不同任务之间共享哪些层;
我们提出了一个新的多任务学习模型,它集成了来自不同标签空间的信息;
我们提出了一个新的顺序迁移学习框架,它采用预先训练的语言模型和新的微调技术;
我们将两种流行的适应方法与各种任务中最先进的预先训练表示进行比较。
1.4 论文大纲
在第 2 章中,概述了与理解本文内容有关的背景资料们,回顾了概率和信息论以及机器学习的基础知识,并进一步讨论了自然语言处理中基于神经网络的方法和任务。
在第 3 章中,定义了迁移学习,并提出了一个 NLP 迁移学习的分类方法。然后,详细回顾了四种迁移学习场景:领域适应、跨语言学习、多任务学习和序列迁移学习。
以下各章重点介绍了这些方案中的每一个方案。在每一章中,介绍相应设置的新方法,这些方法的性能都优于基准数据集上目前最先进的设置方法。
第 4 章介绍了在领域适应数据选择方面的工作。对于受监督的领域适应,提出了一种使用贝叶斯优化来学习从多个域中选择相关训练实例的策略方法。对于无监督领域适应,将经典的半监督学习方法应用于神经网络,并提出了一种 tri-training 启发的新方法。这两种方法都旨在根据半监督学习模型选择与目标领域相似或可靠且信息丰富的相关实例。
在第 5 章中,首先分析了无监督跨语言单词嵌入模型的局限性。研究发现,现有的无监督方法在语言不同的环境中不再有效,并提供了一种弱监督的方法来改善这种情况。进一步提出了一种具有正则匹配的潜变量模型,该模型适用于低资源语言。此外,在潜变量的帮助下,为现有的跨语言单词嵌入模型提供了一个新的视角。
在第 6 章中,提出了两种新颖的体系结构,可以改善多任务学习中任务之间的共享。在多任务学习中,当任务不一致时,目前诸如硬参数共享等方法将会失效。
第一种方法通过允许模型了解应该共享任务之间的信息程度来克服这一点。
第二种方法包含来自其他任务的标签空间的信息。
在第 6 章中,提出了两种新的架构,以改善多任务学习中任务之间的共享。在多任务学习中,当任务不相似时,目前诸如硬参数共享等方法将会失效。第一种方法是通过允许模型学习任务之间的信息应该在多大程度上共享来克服这一点。第二种方法则集成了来自其它任务的标签空间信息。
在第 7 章中,重点介绍了序列迁移学习中先前被忽略的适应阶段。首先提出了一个基于语言建模和新的适应技术的新框架。其次,用最先进的预训练表示来分析适应性。发现任务相似度发挥着重要作用,并为从业者提供指导。
第 8 章最后总结包含了结论、发现,并提供了对未来的展望。
参考链接:
http://ruder.io/thesis/neural_transfer_learning_for_nlp.pdf#page=65
论文地址:
http://ruder.io/thesis/neural_transfer_learning_for_nlp.pdf
本文经授权转载自图灵TOPIA(ID: turingtopia)
更多阅读
【2019新智元 AI 技术峰会今日开幕!】
2019年的3月27日,新智元再汇AI之力,在北京泰富酒店举办AI开年盛典——2019新智元AI技术峰会。峰会以“智能云•芯世界“为主题,聚焦智能云和AI芯片的发展,重塑未来AI世界格局。
同时,新智元将在峰会现场权威发布若干AI白皮书,聚焦产业链的创新活跃,评述AI独角兽影响力,助力中国在世界级的AI竞争中实现超越。






