【MIT硬核新书】深度神经网络高效处理,82页pdf论述DNN计算加速设计原理技术
【导读】深度神经网络在很多监督任务都达到了SOTA性能,但是其计算量是个挑战。来自MIT 教授 Vivienne Sze等学者发布了关于《深度神经网络的高效处理》著作,本书为深度神经网络(DNNs)的高效处理提供了关键原理和技术的结构化处理。值得关注。

https://www.morganclaypoolpublishers.com/catalog_Orig/product_info.php?cPath=22&products_id=1530
本书为深度神经网络(DNNs)的高效处理提供了关键原则和技术的结构化处理。DNNs目前广泛应用于许多人工智能(AI)应用,包括计算机视觉、语音识别和机器人技术。虽然DNNs在许多人工智能任务中提供了最好的性能,但它以高计算复杂度为代价。因此,在不牺牲准确性或增加硬件成本的情况下,能够有效处理深层神经网络以提高指标(如能源效率、吞吐量和延迟)的技术对于在人工智能系统中广泛部署DNNs至关重要。
本书中包括了DNN处理的背景知识;设计DNN加速器的硬件架构方法的描述和分类;评价和比较不同设计的关键指标;DNN处理的特点是服从硬件/算法的共同设计,以提高能源效率和吞吐量;以及应用新技术的机会。读者将会发现对该领域的结构化介绍,以及对现有工作中关键概念的形式化和组织,从而提供可能激发新想法的见解。
深度神经网络(DNNs)已经变得非常流行; 然而,它们是以高计算复杂度为代价的。因此,人们对有效处理DNNs产生了极大的兴趣。DNN加速的挑战有三:
为了实现高性能和效率,
提供足够的灵活性,以满足广泛和快速变化的工作负载范围
能够很好地集成到现有的软件框架中。

第一部分理解深层神经网络
介绍
深度神经网络概述
第二部分处理DNNs的硬件设计
关键量度和设计目标
内核计算
设计DNN加速器
专用硬件上的操作映射
第三部分,DNN硬件和算法的协同设计
减少精度
利用稀疏
设计高效的DNN模型
先进技术
结论
第一个模块旨在提供DNN领域的总体背景和了解DNN工作负载的特点。
第一章提供了DNNs为什么重要的背景,他们的历史和他们的应用。
第二章概述了神经网络的基本组成部分和目前常用的神经网络模型。还介绍了用于DNN研究和开发的各种资源。这包括各种软件框架的讨论,以及用于训练和评估的公共数据集。
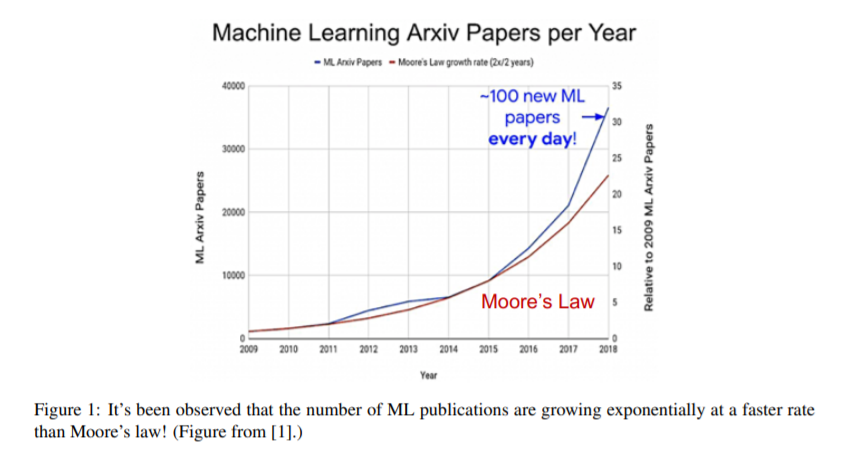
第二部分主要介绍处理DNNs的硬件设计。它根据定制程度(从通用平台到完全定制硬件)讨论各种架构设计决策,以及在将DNN工作负载映射到这些架构时的设计考虑。同时考虑了时间和空间架构。
第三章描述了在设计或比较各种DNN加速器时应该考虑的关键指标。
第四章描述了如何处理DNN内核,重点关注的是时序架构,比如cpu和gpu。为了获得更高的效率,这类架构通常具有缓存层次结构和粗粒度的计算能力,例如向量指令,从而使计算结果更高效。对于这样的架构,DNN处理通常可以转化为矩阵乘法,这有很多优化的机会。本章还讨论了各种软件和硬件优化,用于加速这些平台上的DNN计算,而不影响应用程序的精度。
第五章介绍了DNN处理专用硬件的设计,重点介绍了空间架构。它强调了用于处理DNN的硬件的处理顺序和产生的数据移动,以及与DNN的循环嵌套表示的关系。循环嵌套中的循环顺序称为数据流,它决定了移动每个数据块的频率。循环嵌套中的循环限制描述了如何将DNN工作负载分解成更小的块,称为平铺/阻塞,以说明在内存层次结构的不同级别上有限的存储容量。
第六章介绍了将DNN工作负载映射到DNN加速器的过程。它描述了找到优化映射所需的步骤,包括枚举所有合法映射,并通过使用预测吞吐量和能源效率的模型来搜索这些映射。
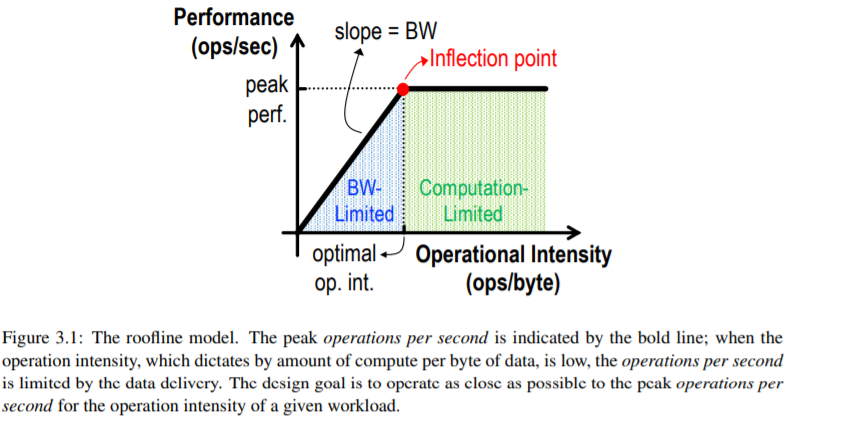
第三个模块讨论了如何通过算法和硬件的协同设计来提高堆栈的效率,或者通过使用混合信号电路和新的存储器或设备技术来降低堆栈的效率。在修改算法的情况下,必须仔细评估对精度的影响。
第七章描述了如何降低数据和计算的精度,从而提高吞吐量和能源效率。它讨论了如何使用量化和相关的设计考虑来降低精度,包括硬件成本和对精度的影响。
第八章描述了如何利用DNNs的稀疏性来减少数据的占用,这为减少存储需求、数据移动和算术操作提供了机会。它描述了稀疏的各种来源和增加稀疏的技术。然后讨论了稀疏DNN加速器如何将稀疏转化为能源效率和吞吐量的提高。它还提出了一种新的抽象数据表示,可用于表达和获得关于各种稀疏DNN加速器的数据流的见解。
第九章描述了如何优化DNN模型的结构(即(例如DNN的“网络架构”),以提高吞吐量和能源效率,同时尽量减少对准确性的影响。它讨论了手工设计方法和自动设计方法(例如。(如神经结构搜索)
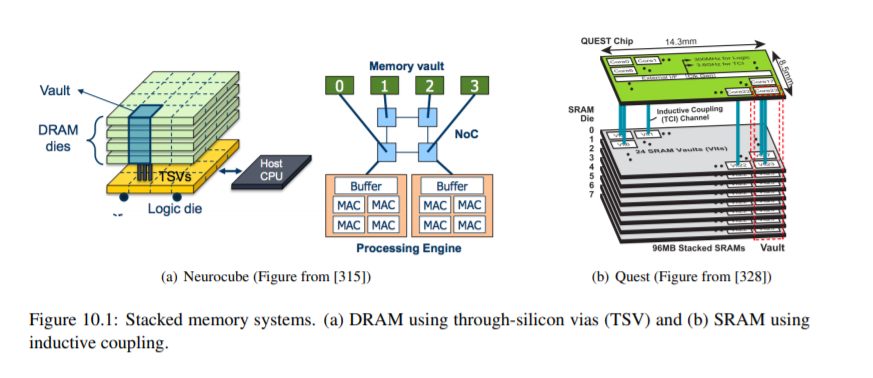
第十章,关于先进技术,讨论了如何使用混合信号电路和新的存储技术,使计算更接近数据(例如,在内存中处理),以解决昂贵的数据移动,支配吞吐量和DNNs的能源消耗。并简要讨论了在光域内进行计算和通信以降低能耗和提高吞吐量的前景。
Vivienne Sze,来自 MIT 的高效能多媒体系统组(Energy-Efficient Multimedia Systems Group)。她曾就读于多伦多大学,在 MIT 完成 PhD 学业并获得电气工程博士学位,目前在 MIT 任教。Sze 教授的主要研究兴趣是高效能算法和移动多媒体设备应用架构。

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DNNEC” 可以获取《【MIT硬核新书】深度神经网络高效处理82页pdf》专知下载链接索引





