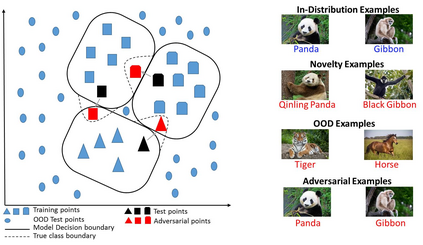
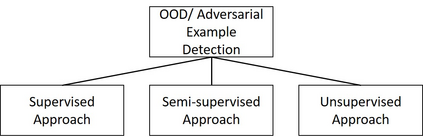
Deep Learning (DL) is vulnerable to out-of-distribution and adversarial examples resulting in incorrect outputs. To make DL more robust, several posthoc anomaly detection techniques to detect (and discard) these anomalous samples have been proposed in the recent past. This survey tries to provide a structured and comprehensive overview of the research on anomaly detection for DL based applications. We provide a taxonomy for existing techniques based on their underlying assumptions and adopted approaches. We discuss various techniques in each of the categories and provide the relative strengths and weaknesses of the approaches. Our goal in this survey is to provide an easier yet better understanding of the techniques belonging to different categories in which research has been done on this topic. Finally, we highlight the unsolved research challenges while applying anomaly detection techniques in DL systems and present some high-impact future research directions.
翻译:深度学习(DL)很容易被分配外和对抗性的例子造成不正确的产出。为了使DL更加稳健,近些年来曾提议采用几种后热异常探测技术来检测(和抛弃)这些异常样品。这项调查试图对基于DL应用的异常探测研究进行有条理和全面的概述。我们根据现有技术的基本假设和采用的方法,为现有技术提供分类法。我们讨论了每个类别的各种技术,并提供了这些方法的相对长处和短处。我们这次调查的目标是更方便、更深入地了解已经就这个主题进行研究的不同类别的技术。最后,我们强调在应用异常探测技术的同时,在DL系统中存在未解决的研究挑战,并提出一些影响很大的未来研究方向。