文本分类又来了,用 Scikit-Learn 解决多类文本分类问题

雷锋网 AI 研习社按:本文为雷锋字幕组编译的技术博客,原标题 Multi-Class Text Classification with Scikit-Learn,作者为 Susan Li 。
翻译 | 朱茵 整理 | 余杭 MY
在商业领域有很多文本分类的应用,比如新闻故事通常由主题来分类;内容或产品常常被打上标签;基于如何在线谈论产品或品牌,用户被分成支持者等等。
然而大部分的文本分类文章和网上教程是二进制的文本分类,像垃圾邮件过滤(spam vs. ham)、情感分析(积极的和消极的)。在大量实例中,我们现实世界的问题要比这些复杂的多。因此,这是我们今天要做的:将消费者的财务投诉分成12个预定义的类。这些数据可以从 data.gov 下载。
我们使用 Python 和 Jupyter Notebook 来开发我们的系统,依靠 Scikit-Learn 作为机器学习的部件。如果你想看下在 PySpark 中的实现,请阅读下一篇文章:
https://medium.com/@actsusanli/multi-class-text-classification-with-pyspark-7d78d022ed35。
问题形成
我们的问题是有监督的文本分类问题,目标是调查哪一种有监督的机器学习方法最适于解决该问题。
鉴于新的投诉的到来,我们想将它归到12个分类目录中。分类器使得每个新投诉被归类到一个仅且一个类别中。这是一个多类文本分类问题。我已经迫不及待地想看下我们完成的结果。
数据浏览
在投入训练机器学习模型前,我们应当先看一些实例以及每个类别中投诉的数量:

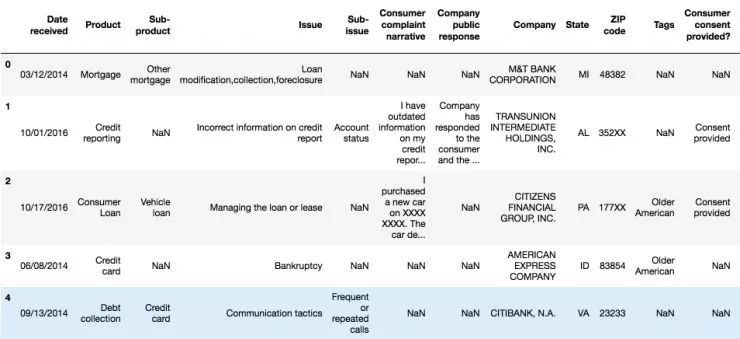
图1
针对这个项目而言,我们仅需要2栏:“Product”和“Consumer complaint narrative”。
输入: Consumer_complaint_narrative
实例:“在我的信用报告上有过时的信息,我之前对该信用报告有争议,该项信息记录应该被删除,该信息是7年多之前的并且不符合信用报告的要求。”
输出:产品
实例:信用报告
我们将在消费者投诉陈述栏删除无赋值的,并且增加一栏编译该产品作为一个整数值,因为通常分类属性变量用整数比用字符串代表要好。
我们也创建了几个字典以备将来使用。
清理后,这是我们要使用的最初的5行数据:


图2
不平衡的分类
我们看到每个产品的投诉数值不平衡。消费者的投诉多针对索回债款、信用报告和房屋抵押贷款。
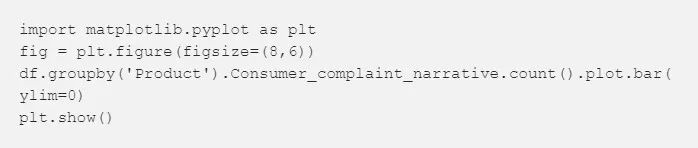
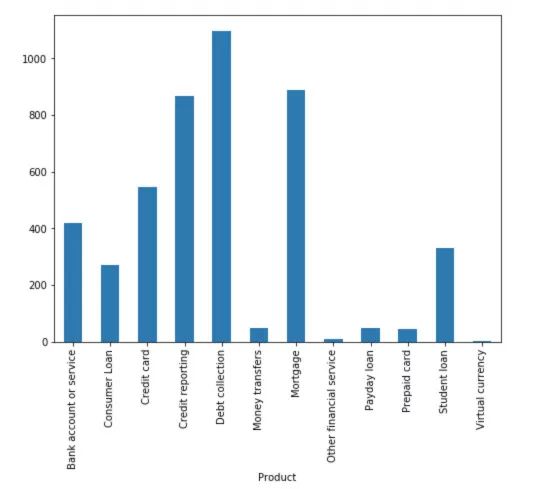
图3
当我们遇到问题时,我们会用标准算法解决这些问题。传统的算法常常倾向于大多数的分类,并不会将数据分布考虑进去。最糟的情况,少数的分类被当做异常值被忽略了。在一些例子中,像欺诈侦测和癌症预测,我们将仔细设置我们的模型或人工平衡数据集,比如通过欠采样和过采样每个类。
然而,在我们的学习不均衡的数据的例子中,我们会将兴趣点放在占少数的的分类上。在大多数分类上具有高准确率的分类器是令人满意的。然而针对占少数的分类也应当保持合理的准确度。就这样吧。
文本表达
分类器和学习算法不能以他们原来的形式直接处理文本文件,他们大多数需要有固定大小的数字特征向量而不是带有变量长度的原来的文本文件。因此,在预处理的阶段文本将被转成更好处理的表达方式。
一个从文本中提取特征的常用方法是使用词汇模型袋:一种给每个文件,在我们的例子中的投诉陈述,词汇的呈现(通常是频率)将被考虑进去,但这些词汇出现的顺序是被忽略的。
尤其是我们数据集的每个术语,我们将计算一种被称为术语频率的测量方法。逆文档频率,缩写成tf-idf。我们将使用 sklearn.feature_extraction.text.TfidfVectorizer 给每个消费者投诉陈述计算一个 tf-idf 向量:
sublinear_df 设置为True 给频率使用一种算法形式。
min_df 是文档的最小数值is the minimum numbers of documents a word must be present in to be kept.
norm 设置为l2,来确保我们的特征向量具有欧几里得标准1.
ngram_range 设置为) (1,2)来表明我们同时考虑一元语法和二元语法。
stop_words 设置为"english" 来移除所有相同的代词("a", "the", ...)用以减少噪音特征的数量。

(4569, 12633)
现在,每 4569 个消费者投诉陈述由12633个特征表示,代表不同的一元和二元语法的 tf-idf 分数。
我们可以使用 sklearn.feature_selection.chi2 来寻找和每个产品最相关的术语:
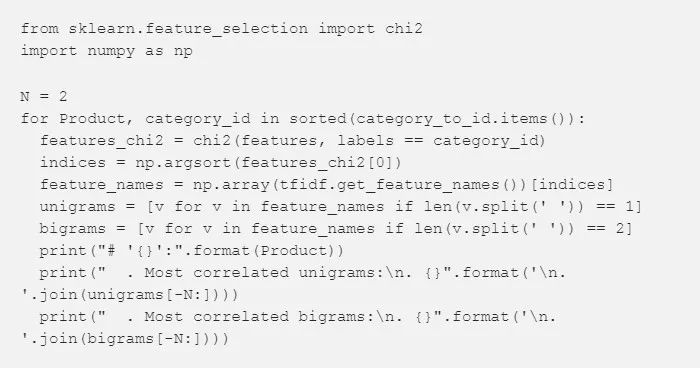
# ‘Bank account or service’:
. 最相关的一元语法:
. bank
. overdraft
. 最相关的二元语法:
. overdraft fees
. checking account
# ‘Consumer Loan’:
. 最相关的一元语法:
. car
. vehicle
. 最相关的二元语法:
. vehicle xxxx
. toyota financial
# ‘Credit card’:
. 最相关的一元语法:
. citi
. card
. 最相关的二元语法:
. annual fee
. credit card
# ‘Credit reporting:
. 最相关的一元语法:
. experian
. equifax
. 最相关的二元语法:
. trans union
. credit report
# ‘Debt collection’:
. 最相关的一元语法:
. collection
. debt
. 最相关的二元语法:
. collect debt
. collection agency
# ‘Money transfers’:
. 最相关的一元语法:
. wu
. paypal
. 最相关的二元语法:
. western union
. money transfer
# ‘Mortgage’:
. 最相关的一元语法:
. modification
. mortgage
. 最相关的二元语法:
. mortgage company
. loan modification
# ‘Other financial service’:
. 最相关的一元语法:
. dental
. passport
. 最相关的二元语法:
. help pay
. stated pay
# ‘Payday loan’:
. 最相关的一元语法:
. borrowed
. payday
. 最相关的二元语法:
. big picture
. payday loan
# ‘Prepaid card’:
. 最相关的一元语法:
. serve
. prepaid
. 最相关的二元语法:
. access money
. prepaid card
# ‘Student loan’:
. 最相关的一元语法:
. student
. navient
. 最相关的二元语法:
. student loans
. student loan
# ‘Virtual currency’:
. 最相关的一元语法:
. handles
. https
. 最相关的二元语法:
. xxxx provider
. money want
这些都很讲得通,对么?
多级类别分类器:特征和设计
为了训练有监督的分类器,我们首先将“消费者投诉陈述”转化为数字向量。我们开发了类似 TF-IDF 权值向量的向量表示。
在得到文本的向量表示后,我们可以训练有监督的分类器来训练看不见的“消费者投诉陈述”和预测“产品”将落在哪个分类。
上述所有这些数据转化后,现在我们有了所有的特征和标签,是时候来训练分类器了。针对这种类型的问题,许多算法可供我们使用。
朴素贝叶斯分类器:最适合的词汇计算的是多项式变量:

在配置好训练设置后,我们来做一些预测。

[‘Debt collection’]


图4

[‘Credit reporting’]


图5
还不算太糟!
模型选择
我们现在可以用不同的机器学习模型来做测试了,评估他们的准确度和寻找任一潜在问题的源头。
我们将用下列四种模型来做测试:
逻辑回归
(多项) 朴素贝叶斯
线性支持向量机
随机森林


图6

model_name
LinearSVC: 0.822890
LogisticRegression: 0.792927
MultinomialNB: 0.688519
RandomForestClassifier: 0.443826
Name: accuracy, dtype: float64
线性支持向量机和逻辑回归比其他两种分类器表现更好,线性支持向量机有一个小优势,它具备 82% 左右的准确率。
模型评估
继续我们最好的模型(线性支持向量机),我们看下混淆矩阵,展示下预测的和实际的标签之间的差异。

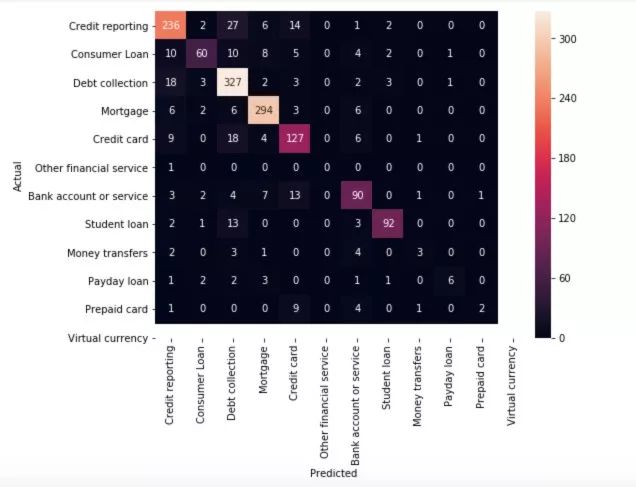
图7
大多数的预测最终呈现的是对角线(预测的标签 = 实际的标签),正是我们想要的。然而,还是有许多的误分类,看看他们是由什么引起的也许蛮有意思的:
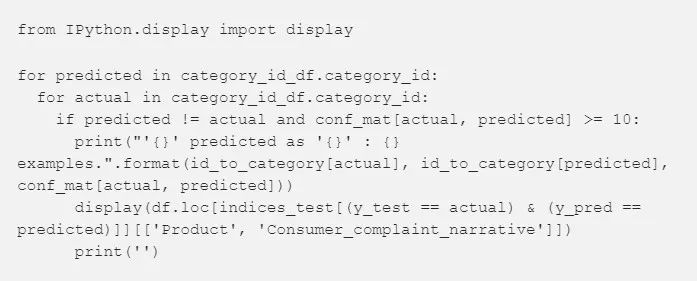

图8

图9
你可以看到,一些误分类的投诉是一些跟不止一个主题相关的投诉(比如,包括信用卡和信用报告的投诉)。这种错误将一直发生。
然后我们使用 chi-squared test 来寻找与每个目录最相关的术语:

# ‘Bank account or service’:
. 最高一元语法:
. bank
. account
. 最高二元语法:
. debit card
. overdraft fees
# ‘Consumer Loan’:
. 最高一元语法:
. vehicle
. car
. 最高二元语法:
. personal loan
. history xxxx
# ‘Credit card’:
. 最高一元语法:
. citi
. card
. 最高二元语法:
. credit card
. discover card
# ‘Credit reporting:
. 最高一元语法:
. equifax
. transunion
. 最高二元语法:
. xxxx account
. trans union
# ‘Debt collection’:
. 最高一元语法:
. collection
. debt
. 最高二元语法:
. account credit
. time provided
# ‘Money transfers’:
. 最高一元语法:
. paypal
. transfer
. 最高二元语法:
. money transfer
. send money
# ‘Mortgage’:
. 最高一元语法:
. mortgage
. escrow
. 最高二元语法:
. loan modification
. mortgage company
# ‘Other financial service’:
. 最高一元语法:
. passport
. dental
. 最高二元语法:
. stated pay
. help pay
# ‘Payday loan’:
. 最高一元语法:
. payday
. loan
. 最高二元语法:
. payday loan
. pay day
# ‘Prepaid card’:
. 最高一元语法:
. prepaid
. serve
. 最高二元语法:
. prepaid card
. use card
# ‘Student loan’:
. 最高一元语法:
. navient
. loans
. 最高二元语法:
. student loan
. sallie mae
# ‘Virtual currency’:
. 最高一元语法:
. https
. tx
. 最高二元语法:
. money want
. xxxx provider
这些跟我们的预期一致。
最后,我们给每个类别打印分类报告:

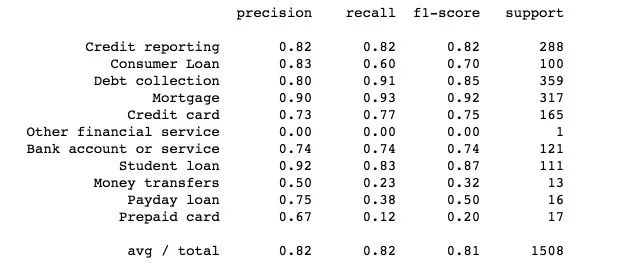
图9
源代码可以在 Github 上找到,链接如下:
http://suo.im/5l2J51
原文链接:
https://towardsdatascience.com/multi-class-text-classification-with-scikit-learn-12f1e60e0a9

号外号外~
一个专注于
AI技术发展和AI工程师成长的求知求职社区
诞生啦!
欢迎大家扫码体验


采用通用语言模型的最新文本分类介绍
▼▼▼




